论文笔记--Learning Political Polarization on Social Media Using Neural Networks
- 1. 文章简介
- 2. 文章概括
- 3. 相关工作
- 4. 文章重点技术
- 4.1 Collection of posts
- 4.1.1 数据下载
- 4.1.2 数据预处理
- 4.1.3 统计显著性分析
- 4.2 Classification of Posts
- 4.3 Polarization of users
- 5. 文章亮点
- 6. 原文传送门
1. 文章简介
- 标题:Learning Political Polarization on Social Media Using Neural Networks
- 作者:LORIS BELCASTRO, RICCARDO CANTINI, FABRIZIO MAROZZO, DOMENICO TALIA AND PAOLO TRUNFIO
- 日期:2020
- 期刊:IEEE
2. 文章概括
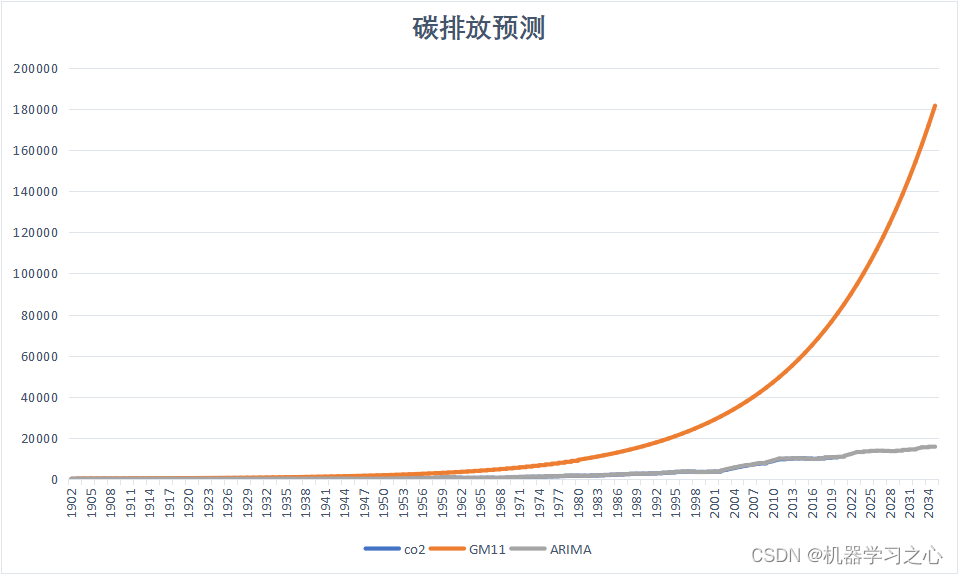
文章提出了一种基于神经网络对政治两极化观点进行分析的方法IOM-NN, 基于两组case的分析结果表明该方法相比于传统的分析方法准确率更高,得到的结果更加接近真实结果,甚至比民意调查结果更可靠。
3. 相关工作
简单的介绍一下近年来常用的通过社交媒体来分析公共观点、预测选举结果的一些方法。现存的方法一般可分为三类:
- Volume-based:计算各个候选人的博客/点赞/评论的数量,预测选票结果。但基于volume的方法常常受到发文数量的影响,比如某用户发文特别多,则其支持的候选人被预测的可能性会变大。IOM-NN则优化为基于用户数量的预测,从而避免了该问题。
- Sentiment- or opinion-based: 利用NLP/文本挖掘技术尝试理解用户对某候选人或某党派的观点。IOM-NN使用了BOW词袋模型和神经网络相结合来对博文进行分类,进一步对撰写博文的博主进行分类。
- Network-based:分析社交媒体用户的网络结构,从而可以理解公共观点的动态。
4. 文章重点技术
文章提出了IOM-NN(Iterative Opinion Mining using Neural Network)方法。主要步骤如下
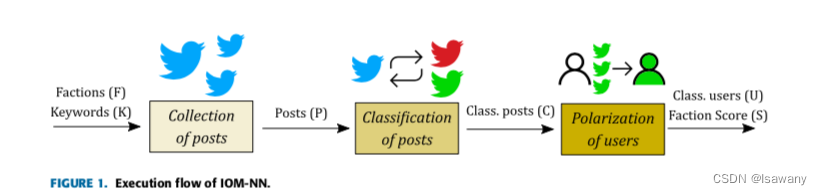
4.1 Collection of posts
4.1.1 数据下载
定义 E \mathcal{E} E为不同党派 F = { f 1 , … , f n } F=\{f_1, \dots, f_n\} F={f1,…,fn}之间的竞争时间。则数据收集阶段我们需要知道如下信息
- K c o n t e x t K_{context} Kcontext表示和事件 E \mathcal{E} E相关的通用关键词集合
-
K
F
⊕
=
K
f
1
⊕
∪
⋯
∪
K
f
n
⊕
K_F^\oplus = K_{f_1}^{\oplus} \cup \dots \cup K_{f_n}^{\oplus}
KF⊕=Kf1⊕∪⋯∪Kfn⊕表示和各个党派相关的postive keywords(支持该党派的关键词)。
接下来我们下载收集包含上述任一组关键词中一个或多个关键词的博客,得到数据集。
4.1.2 数据预处理
- 将文本转化为小写,将特殊的accent字符替换为对应的普通字符
- 取单词的stem
- 移除停词
- 不考虑非本国家的人发表的该国语言的博文。
最终输出的结果为博文集合 P P P
4.1.3 统计显著性分析
在使用数据之前,文章分析了数据集的年龄、性别和地理分布,为了确定用户是否具有代表性
4.2 Classification of Posts
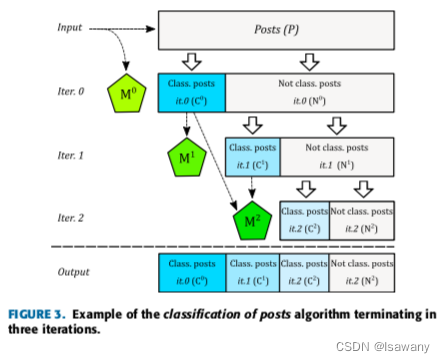
下表为文章对博文进行分类的伪代码。

- 第一部分(1-9行)为算法的初始化过程:先尝试对每个博文进行分类(分类方法为返回一个0-1向量,表示该博文是否包含某个党派对应的关键词集合 K f ⊕ K_f^{\oplus} Kf⊕,如果某博文属于且仅属于其中一个党派 f f f,则将博文 p p p分类到该党派,并将结果对 < p , f > <p, f> <p,f>加入到已分类的博文集合 C 0 C^0 C0。最终剩余为分类的集合记作 N 0 N^0 N0
- 第二部分(10~21行)对分类规则和结果进行迭代的更新,每一步的更新方法类似初始化过程,区别为迭代过程中,文章会迭代地利用前面所有步骤的分类结果训练一个神经网络模型,然后通过神经网络模型对当前未分类的博文集合进行预测,得到一个概率向量,如果该向量某概率值大于给定阈值
t
h
th
th,则将该博文分类到该党派,并将结果对加入到已分类的集合中。迭代停止条件为当前轮次有分类结果的占比大于等于某阈值(已经有足够多的分类结果),或者当前轮次有分类结果的占比小于等于某阈值(无法再通过迭代优化)。
下图为该算法的图示
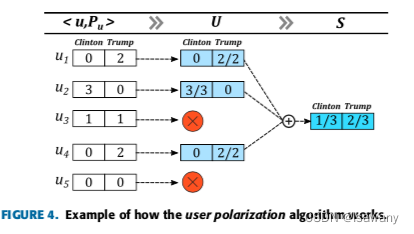
4.3 Polarization of users
下图为对用户极性进行分析的伪代码:

- 聚合:首先文章按照用户将上述分类结果进行聚合,得到字典 C U = ( u , P u ) C_U={(u, P_u)} CU=(u,Pu),其中 P u P_u Pu表示拥护 u u u对应的所有博文的分类结果list。
- 过滤:接下来,对字典中的每一个结果对,文章会首先判断用户是否满足以下过滤条件,全部满足的拥护才被保留
- 在该事件至少发文 m i n P o s t minPost minPost次
- 该拥护的博文中存在至少 2 / 3 2/3 2/3的博文是关于某个党派的
- 分极:针对上述未被过滤的博文对,文章按照下图所示方法对用户进行分极。具体来说,文章生成一个用户
u
u
u对应的百分比向量,用该向量进行聚合、归一化得到最终的分极向量
S
S
S
5. 文章亮点
文章提出了一种基于迭代式的神经网络进行政治极化预测的方法,该方法只需收集关键词和博文数据,便可自适应地迭代训练得到一个较为准确的分类结果。在2018意大利选举和2016美国总统竞选数据集上,该方法表现超过其它测试的算法,几乎接近真实结果。未来或可考虑通过该方法替代昂贵的民意调查来进行竞选结果预测、支持率调研等。
6. 原文传送门
Learning Political Polarization on Social Media Using Neural Networks