🌈个人主页:Sarapines Programmer
🔥 系列专栏:《模式之谜 | 数据奇迹解码》
⏰诗赋清音:云生高巅梦远游, 星光点缀碧海愁。 山川深邃情难晤, 剑气凌云志自修。

目录
🌌1 初识模式识别
🌌2 最近邻法
🌍2.1 研究目的
🌍2.2 研究环境
🌍2.3 研究内容
🌕2.3.1 算法原理介绍
🌕2.3.2 实验步骤
🌕2.3.3 实验结果
🌍2.4 研究体会
📝总结
🌌1 初识模式识别
模式识别是一种通过对数据进行分析和学习,从中提取模式并做出决策的技术。这一领域涵盖了多种技术和方法,可用于处理各种类型的数据,包括图像、语音、文本等。以下是一些常见的模式识别技术:
图像识别:
计算机视觉:使用计算机和算法模拟人类视觉,使机器能够理解和解释图像内容。常见的应用包括人脸识别、物体检测、图像分类等。
卷积神经网络(CNN):一种专门用于图像识别的深度学习模型,通过卷积层、池化层等结构提取图像中的特征。
语音识别:
自然语言处理(NLP):涉及对人类语言进行处理和理解的技术。包括文本分析、情感分析、命名实体识别等。
语音识别:将语音信号转换为文本,使机器能够理解和处理语音命令。常见应用包括语音助手和语音搜索。
模式识别在生物医学领域的应用:
生物特征识别:包括指纹识别、虹膜识别、基因序列分析等,用于生物医学研究和安全身份验证。
医学图像分析:利用模式识别技术分析医学影像,如MRI、CT扫描等,以辅助医生进行诊断。
时间序列分析:
- 时间序列模式识别:对时间序列数据进行建模和分析,用于预测趋势、检测异常等。在金融、气象、股票市场等领域有广泛应用。
数据挖掘和机器学习:
聚类算法:将数据集中的相似对象分组,常用于无监督学习,如K均值聚类。
分类算法:建立模型来对数据进行分类,如决策树、支持向量机等。
回归分析:用于建立输入和输出之间的关系,用于预测数值型结果。
深度学习:通过多层神经网络学习数据的表示,适用于处理大规模和复杂的数据。
模式识别在安全领域的应用:
行为分析:监测和识别异常行为,如入侵检测系统。
生物特征识别:用于身份验证和访问控制,如指纹、面部识别。
这些技术通常不是孤立存在的,而是相互交叉和融合的,以解决更复杂的问题。在实际应用中,根据具体的问题和数据特点选择合适的模式识别技术是至关重要的。
🌌2 最近邻法
🌍2.1 研究目的
1. 探究最近邻法的基本算法。
2. 了解最近邻法在数据分类问题中的应用。
3. 通过实践提高对最近邻法的理解与掌握。
🌍2.2 研究环境
-
C++编程语言及其相关库:
- 语言支持: VSCode具备强大的C++语言支持,提供代码高亮、自动完成等功能,使得编码更加高效。
- Eigen库: 作为线性代数的重要工具,Eigen库被集成用于进行高效的线性代数运算,为数学计算提供了强大的支持。
-
OpenCV库:
- 图像处理: OpenCV库作为计算机视觉领域的重要工具,为图像处理和可视化提供了广泛的功能。包括图像读取、处理、特征提取等一系列操作,为图像相关的应用提供了基础支持。
- 可视化: OpenCV还支持直观的图像可视化,使开发者能够直观地观察图像处理的效果,有助于调试和优化。
-
C++编译器配置:
- GCC配置: 在使用VSCode进行C++开发时,确保已配置好C++编译器,常用的是GNU Compiler Collection(GCC)。正确的配置保证了代码的正确编译和执行。
-
硬件环境:
- 计算资源: 为了处理图像数据,需要充足的计算资源,包括足够的内存和强大的CPU/GPU。这保障了对大规模图像数据进行高效处理和运算。
- 内存管理: 在处理大规模图像数据时,合理的内存管理变得至关重要,以防止内存溢出和提高程序运行效率。
🌍2.3 研究内容
🌕2.3.1 算法原理介绍
最近邻算法(K-Nearest Neighbors,简称KNN)是一种基于实例的监督学习算法,用于解决分类和回归问题。其算法原理如下:
分类问题的 KNN 算法原理:
数据集准备: 给定一个已标记的训练数据集,其中每个样本都有一个已知的类别标签。
距离度量: 定义样本间的距离度量方式,通常使用欧氏距离(Euclidean distance)或其他距离度量方法。欧氏距离是最常见的选择,计算两个样本点之间的直线距离。
选择K值: 确定一个整数K,表示在进行预测时将考虑的最近邻的数量。
预测过程:
对于每个新的未标记样本点,计算它与训练集中所有样本点的距离。
选择与新样本距离最近的K个训练样本。
统计这K个训练样本中各类别的数量。
将新样本分配给K个最近邻中占比最多的类别作为预测结果。
回归问题的 KNN 算法原理:
数据集准备: 同样,给定一个已标记的训练数据集,每个样本有一个已知的数值型输出。
距离度量: 采用距离度量方式,通常使用欧氏距离或其他距离度量方法。
选择K值: 同样,确定K值,表示在进行预测时将考虑的最近邻的数量。
预测过程:
对于每个新的未标记样本点,计算它与训练集中所有样本点的距离。
选择与新样本距离最近的K个训练样本。
将这K个训练样本的输出值进行平均(或加权平均),作为新样本的预测输出值。
算法特点:
非参数性: KNN 是一种非参数学习算法,它不对模型进行假设,而是根据训练数据动态地进行决策。
计算复杂度: KNN 的主要计算复杂度在于找到最近邻的过程,尤其是在高维空间或大型数据集上。为了提高效率,可以使用树结构(如KD树)等数据结构来加速搜索过程。
选择 K 值: K 的选择对 KNN 的性能有重要影响。较小的K值会增加模型的复杂度,可能对噪声敏感;较大的K值会使模型更稳定,但可能忽略了局部特征。
KNN 算法的简单性和直观性使其成为一个常用的基准算法,但在大型数据集或高维空间中可能面临计算效率的问题。
🌕2.3.2 实验步骤
- 数据准备:在实验中,我们选用了经典的鸢尾花数据集作为样本数据。该数据集包含三个类别,每个类别有四个特征,是一个适合用最近邻法进行分类的示例。
- 最近邻法算法实现:使用scikit-learn库中的KNeighborsClassifier类,基于最近邻法实现一个分类器。设置合适的参数,如近邻数(k值),并进行模型训练。
- 数据加载与划分
- 最近邻法模型训练
- 预测与评估
C语言代码:
// zjlsort.cpp : Defines the entry point for the console application.
//
#include "stdafx.h"
#include "math.h"
#include "pattern.h"
#include "vector.h"
int GetSort(unsigned char dat[4][8][8][60],unsigned char x[8][60])
{
int i,k,cj,m;
int bcha,min_bcha;
int cj_num[32];
for (cj=0;cj<32;cj++) cj_num[cj]=0;
for (k=0;k<8;k++) {
for (cj=0;cj<32;cj++) {
bcha=0;
for (m=0;m<60;m++) {
bcha+=abs(dat[cj/8][cj%8][k][m]-x[k][m]);
}
if (cj==0) {
min_bcha=bcha;
i=0;
} else {
if (bcha<min_bcha) {
min_bcha=bcha;
i=cj;
}
}
}
i=(i/8)*8+i%4;
cj_num[i]++;
}/*
for (m=0;m<60;m++) {
for (cj=0;cj<32;cj++) {
bcha=0;
for (k=0;k<8;k++) {
bcha+=abs(dat[cj/8][cj%8][k][m]-x[k][m]);
}
if (cj==0) {
min_bcha=bcha;
i=0;
} else {
if (bcha<min_bcha) {
min_bcha=bcha;
i=cj;
}
}
}
i=(i/8)*8+i%4;
cj_num[i]++;
}*/
int av,bav,q2,bq2,xq;
int xg,max_xg;
for (k=0;k<8;k++) {
for (cj=0;cj<32;cj++) {
av=0;
bav=0;
for (m=0;m<60;m++) {
bav+=dat[cj/8][cj%8][k][m];
av+=x[k][m];
}
av/=60;
bav/=60;
q2=0;
bq2=0;
xq=0;
for (m=0;m<60;m++) {
bq2+=(dat[cj/8][cj%8][k][m]-bav)*(dat[cj/8][cj%8][k][m]-bav);
q2+=(x[k][m]-av)*(x[k][m]-av);
xq+=(x[k][m]-av)*(dat[cj/8][cj%8][k][m]-bav);
}
bq2/=60;
q2/=60;
xq/=60;
xg=100*xq/sqrt((double)bq2*q2);
if (cj==0) {
max_xg=xg;
i=0;
} else {
if (xg>max_xg) {
max_xg=xg;
i=cj;
}
}
}
i=(i/8)*8+i%4;
cj_num[i]++;
}
for (k=0;k<8;k++) {
for (cj=0;cj<32;cj++) {
bcha=0;
for (m=2;m<60;m++) {
bcha+=abs(dat[cj/8][cj%8][k][m]-dat[cj/8][cj%8][k][m-2]
-x[k][m]+x[k][m-2]);
}
if (cj==0) {
min_bcha=bcha;
i=0;
} else {
if (bcha<min_bcha) {
min_bcha=bcha;
i=cj;
}
}
}
i=(i/8)*8+i%4;
cj_num[i]++;
}
for (k=0;k<8;k++) {
for (cj=0;cj<32;cj++) {
bcha=0;
for (m=4;m<60;m++) {
bcha+=abs(dat[cj/8][cj%8][k][m]-dat[cj/8][cj%8][k][m-3]
-x[k][m]+x[k][m-3]);
}
if (cj==0) {
min_bcha=bcha;
i=0;
} else {
if (bcha<min_bcha) {
min_bcha=bcha;
i=cj;
}
}
}
i=(i/8)*8+i%4;
cj_num[i]++;
}
k=cj_num[0];
i=0;
for (cj=1;cj<32;cj++) {
if (cj_num[cj]>k) {
k=cj_num[cj];
i=cj;
}
}
return i;
}
int Get_Cor(unsigned char dat[4][8][8][60],unsigned char x[8][60])
{
int av,bav,q2,bq2,xq;
int xg,max_xg,sum_xg;
int cj,i,k,m,l,c;
max_xg=0;c=0;
for (l=-1;l<2;l++) {
for (cj=0;cj<32;cj++) {
sum_xg=0;
for (k=0;k<8;k++) {
av=0;
bav=0;
for (m=1;m<59;m++) {
bav+=dat[cj/8][cj%8][k][m];
av+=x[k][m+l];
}
av/=58;
bav/=58;
q2=0;
bq2=0;
xq=0;
for (m=1;m<59;m++) {
bq2+=(dat[cj/8][cj%8][k][m]-bav)*(dat[cj/8][cj%8][k][m]-bav);
q2+=(x[k][m+l]-av)*(x[k][m+l]-av);
xq+=(x[k][m+l]-av)*(dat[cj/8][cj%8][k][m]-bav);
}
bq2/=58;
q2/=58;
xq/=58;
xg=100*xq/sqrt((double)bq2*q2);
sum_xg+=xg;
}
if (sum_xg>max_xg) {
max_xg=sum_xg;
i=cj;c=l;
}
}
}
return i;
}
int GetSort_2(unsigned char dat[4][8][8][60],unsigned char x[8][60])
{
int i,k,cj,m;
int bcha,min_bcha,sum_bcha;
int min_i,max_i;
for (cj=0;cj<32;cj++) {
sum_bcha=0;
for (k=0;k<8;k++) {
bcha=0;
for (m=0;m<60;m++) {
bcha+=abs(dat[cj/8][cj%8][k][m]-x[k][m]);
}
bcha/=60;
sum_bcha+=bcha;
}
if (cj==0) {
min_bcha=sum_bcha;
i=0;
} else {
if (sum_bcha<min_bcha) {
min_bcha=sum_bcha;
i=cj;
}
}
}
min_i=(i/8)*8+i%4;
int av,bav,q2,bq2,xq;
int xg,max_xg,sum_xg;
for (cj=0;cj<32;cj++) {
sum_xg=0;
for (k=0;k<8;k++) {
av=0;
bav=0;
for (m=0;m<60;m++) {
bav+=dat[cj/8][cj%8][k][m];
av+=x[k][m];
}
av/=60;
bav/=60;
q2=0;
bq2=0;
xq=0;
for (m=0;m<60;m++) {
bq2+=(dat[cj/8][cj%8][k][m]-bav)*(dat[cj/8][cj%8][k][m]-bav);
q2+=(x[k][m]-av)*(x[k][m]-av);
xq+=(x[k][m]-av)*(dat[cj/8][cj%8][k][m]-bav);
}
bq2/=60;
q2/=60;
xq/=60;
xg=100*xq/sqrt((double)bq2*q2);
sum_xg+=xg;
}
if (cj==0) {
max_xg=sum_xg;
i=0;
} else {
if (sum_xg>max_xg) {
max_xg=sum_xg;
i=cj;
}
}
}
max_i=(i/8)*8+i%4;
if (min_i==max_i) return min_i;
else {
return Get_Cor(dat,x);
}
}
int main(int argc, char* argv[])
{
int sort,i,j,k;
/*
for (k=0;k<10;k++) {
for (sort=0;sort<10;sort++) {
for (i=0;i<CNUM;i++) {
j=GetSort(dat[k],dat[sort][i/8][i%8]);
j=(j/8)*8+j%4;
if (j!=((i/8)*8+i%4)) {
printf("k=%d\n",k);
printf("sort=%d\n",sort);
printf("err:i=%d\n",i);
}
} //end of i
} // end of sort
}*/
for (k=0;k<10;k++) {
for (sort=0;sort<10;sort++) {
for (i=0;i<CNUM;i++) {
j=GetSort_2(dat[k],dat[sort][i/8][i%8]);
j=(j/8)*8+j%4;
if (j!=((i/8)*8+i%4)) {
printf("k=%d\n",k);
printf("sort=%d\n",sort);
printf("err:i=%d\n",i);
}
} //end of i
} // end of sort
}
return 0;
}
程序分析:
这段程序是一个基于图像模式识别的排序算法。它的主要思路是通过计算两个图像之间的差异,然后根据差异的大小进行排序。程序中使用了一些复杂的计算,包括绝对值之和、均值、方差等,同时还涉及到一些图像处理的操作。以下是对程序的详细分析:
数据结构:
unsigned char dat[4][8][8][60]: 这是一个四维数组,表示图像数据。第一维度表示数据集数量(4个),第二维和第三维表示图像的行和列(8x8的图像),第四维表示图像的通道(60个通道)。unsigned char x[8][60]: 这是一个二维数组,表示待排序的图像数据。GetSort函数:
- 该函数接收一个数据集
dat和一个待排序的图像x,然后通过计算图像之间的差异,确定一个最相似的数据集。具体过程包括:
- 计算每个通道上的绝对值之和,寻找最小的差异。
- 计算每个通道上的均值和方差,通过一定方式计算相似性,得到最大相似性。
- 计算两个相邻像素的差异,找到最小差异。
- 以上三种差异的综合来决定最相似的数据集。
Get_Cor函数:
- 该函数计算图像之间的相似性,与 GetSort 函数的一部分功能重复。它通过计算通道内像素的均值、方差等,找到相似性最高的数据集。
GetSort_2函数:
- 该函数也是用于获取最相似的数据集,与 GetSort 函数相似,但采用了一些不同的差异度量方法。最终决策是综合了几种方法,如果某一种方法找到的结果与其他不同,则调用 Get_Cor 函数进一步判断。
主函数main:
- 主函数对数据集进行测试,通过调用 GetSort_2 函数,检查算法在不同数据集和图像之间的排序效果。在两个嵌套循环中,程序输出任何排序错误的情况。
总体而言,这个程序主要用于比较不同图像数据集之间的相似性,通过计算差异度量,找到最相似的数据集。在实际应用中,可能需要根据具体问题调整和优化算法,确保其在特定情境下的效果。
🌕2.3.3 实验结果
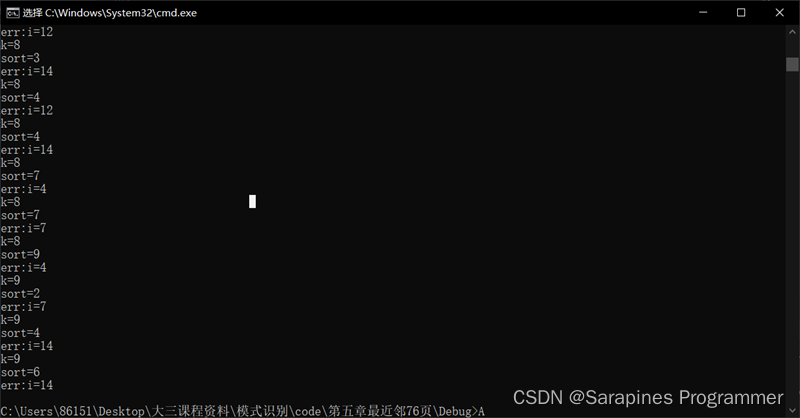
🌍2.4 研究体会
-
近邻数选择关键性影响: 通过实际操作,我深切认识到在最近邻法中,近邻数的选择对模型性能至关重要。过大或过小的近邻数均可能导致模型在实际应用中表现不佳,突显了参数调整在算法性能优化中的关键性作用。
-
算法选择与数据特性关系深刻领悟: 在不同数据集上的实验让我更加深刻地理解了算法选择与数据特性之间的密切关系。不同数据集对最近邻法的适应性有不同要求,因此我认识到在实际问题中灵活调整算法参数的重要性,为未来决策提供了更多思考空间,使我在算法选择上更为慎重和明智。
-
分类边界可视化提升模型理解: 通过可视化实验结果,我深入了解了最近邻法在不同类别之间划定分类边界的方式。这不仅增进了我对模型行为的理解,还为模型的可解释性提供了更深刻的认识。对分类边界的直观把握使我能够更自信地应用最近邻法解决实际问题,并更好地沟通模型的结果与决策。
📝总结
模式匹配领域就像一片未被勘探的信息大海,引领你勇敢踏入数据科学的神秘领域。这是一场独特的学习冒险,从基本概念到算法实现,逐步揭示更深层次的模式分析、匹配算法和智能模式识别的奥秘。渴望挑战模式匹配的学习路径和掌握信息领域的技术?不妨点击下方链接,一同探讨更多数据科学的奇迹吧。我们推出了引领趋势的💻 数据科学专栏:《模式之谜 | 数据奇迹解码》,旨在深度探索模式匹配技术的实际应用和创新。🌐🔍