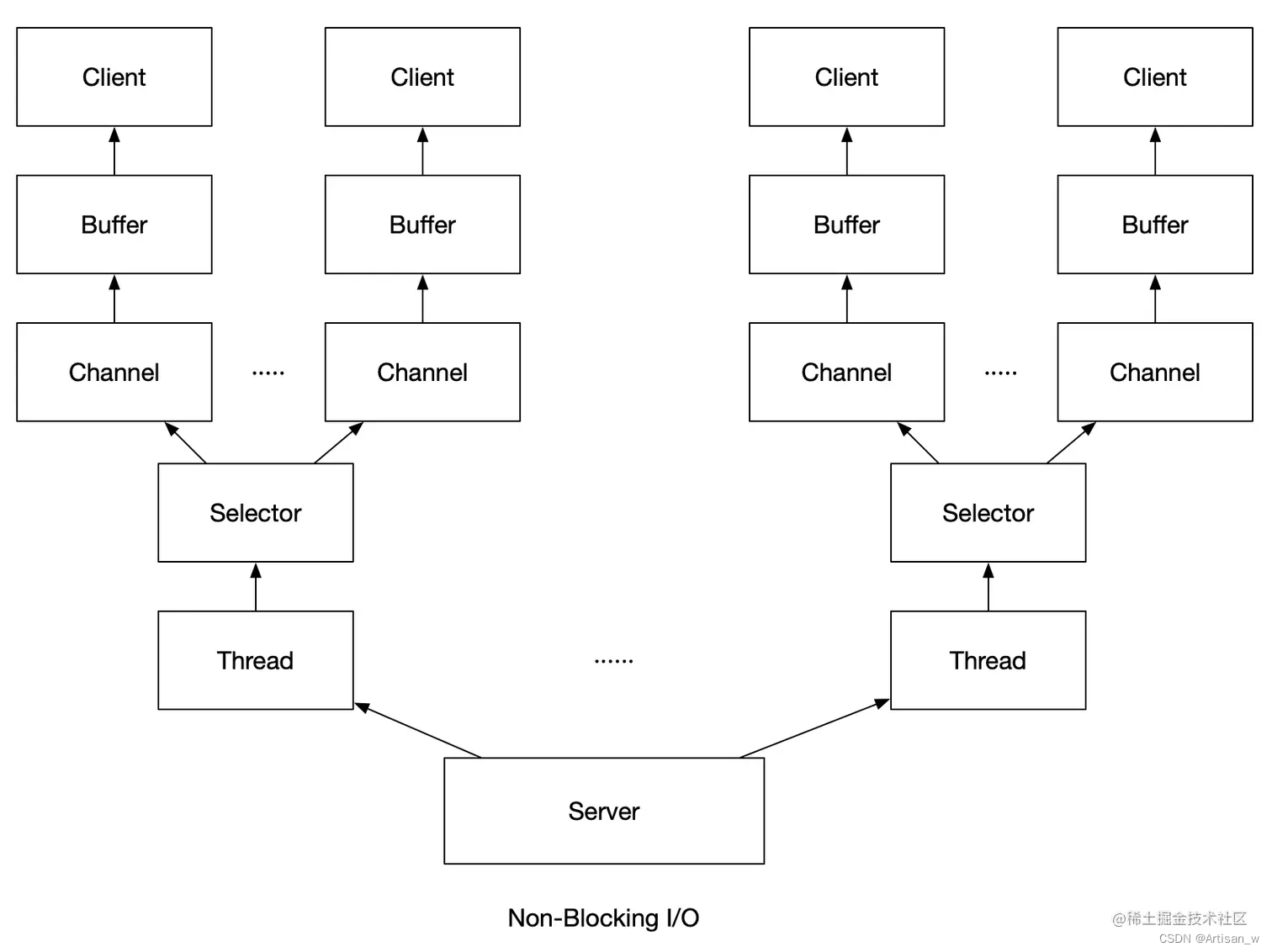
一、引言
在软件开发中,字符编码是一个非常重要的概念。不同的编码方式用于在不同的系统和应用中表示文本数据。UCS2、UTF8和GBK2312是三种常见的字符编码方式。为了实现不同编码间的转换,我们可以使用C语言进行编程,利用已有的库或者手动实现转换算法。
二、编码概述
1、UCS2编码
UCS2,全称“Universal Character Set 2”,是一个固定长度的Unicode字符编码。它使用2个字节(16位)来表示每一个字符,这意味着它可以表示2^16,即65536个不同的字符。这种编码方式简单且直接,因为它为每个字符提供了相同的字节长度,使得字符处理变得相对容易。但是,由于它不能表示超过65536个字符,因此它无法覆盖所有的Unicode字符集。
2、UTF8编码
UTF8,全称“Unicode Transformation Format 8-bit”,是一种可变长度的Unicode字符编码。它可以用来表示Unicode标准中的所有字符,且其编码方式是与ASCII兼容的。在UTF8中,字符可以使用1到4个字节不等来表示。对于常见的字符,UTF8使用较少的字节来表示,而对于不常见的字符,则使用更多的字节。这种设计使得UTF8在文本存储和网络传输中非常高效。
UTF8的一个重要特性是它的字节顺序不依赖性,即不论文件的字节顺序如何,UTF8编码的文本都可以被正确地解释。这使得UTF8成为一种非常流行的国际文本编码方式。
3、GBK2312编码
GBK2312,全称“国家标准扩展编码集”,是一种简体中文的字符编码标准。它是基于早期的GB2312标准而开发的,用于解决GB2312中字符数量不足的问题。GBK2312扩展了字符集,包含了更多的汉字和符号,使得它能够更好地支持简体中文的文本处理。
与Unicode不同,GBK2312是一个双字节编码,它使用两个字节来表示一个字符。它的编码方式与ASCII不兼容,因此在处理包含ASCII字符和GBK2312字符的混合文本时,需要特别注意编码转换的问题。
三、转换方法
-
UCS2与UTF8之间的转换:由于UCS2是固定长度编码,而UTF8是变长编码,因此转换时需要按照各自的编码规则进行。对于UCS2转UTF8,需要根据Unicode码点范围判断使用几个字节表示;对于UTF8转UCS2,则需要根据UTF8的字节序列还原出Unicode码点。
-
UTF8与GBK2312之间的转换:由于这两种编码的字符集不同,直接转换是不可能的。通常需要通过Unicode作为中间桥梁进行转换。先将UTF8转换为Unicode码点,再根据码点查找GBK2312对应的编码;反之亦然。
三、C语言实现UCS2、UTF8与GBK2312编码转换
1、UCS2转UTF8
#include <stdio.h>
void ucs2_to_utf8(unsigned char *ucs2, unsigned char *utf8) {
unsigned int ch;
ch = ucs2[0] + (ucs2[1] << 8);
if (ch < 0x80) {
utf8[0] = ch;
utf8[1] = '\0';
} else if (ch < 0x800) {
utf8[0] = 0xC0 | (ch >> 6);
utf8[1] = 0x80 | (ch & 0x3F);
utf8[2] = '\0';
} else {
utf8[0] = 0xE0 | (ch >> 12);
utf8[1] = 0x80 | ((ch >> 6) & 0x3F);
utf8[2] = 0x80 | (ch & 0x3F);
utf8[3] = '\0';
}
}
int main() {
unsigned char ucs2[] = {0x4F, 0x60}; // 你好 的第一个字 in UCS-2LE
unsigned char utf8[4];
ucs2_to_utf8(ucs2, utf8);
printf("Converted string: %s\n", utf8); // Should print: 你
return 0;
}
2、UTF8转UCS2
#include <stdio.h>
void utf8_to_ucs2(unsigned char *utf8, unsigned char *ucs2) {
unsigned int ch;
if ((utf8[0] & 0xE0) == 0xC0) { // 2 bytes UTF-8 sequence
ch = (utf8[0] & 0x1F) << 6;
ch |= utf8[1] & 0x3F;
ucs2[1] = ch & 0xFF;
ucs2[0] = (ch >> 8) & 0xFF;
} else if ((utf8[0] & 0xF0) == 0xE0) { // 3 bytes UTF-8 sequence
ch = (utf8[0] & 0x0F) << 12;
ch |= (utf8[1] & 0x3F) << 6;
ch |= utf8[2] & 0x3F;
ucs2[1] = ch & 0xFF;
ucs2[0] = (ch >> 8) & 0xFF;
} else { // ASCII character or invalid UTF-8 sequence
ucs2[1] = utf8[0];
ucs2[0] = '\0'; // Only the lower byte is significant for ASCII chars in UCS-2LE
}
}
int main() {
unsigned char utf8[] = {0xE4, 0xBD, 0xA0}; // 你 in UTF-8
unsigned char ucs2[2];
utf8_to_ucs2(utf8, ucs2);
printf("Converted UCS-2: %X %X\n", ucs2[1], ucs2[0]); // Should print: 60 4F
return 0;
}
3、关于GBK2312
由于GBK2312是一个与Unicode不同的字符集,所以简单的位操作转换是不可能的。要实现与GBK的转换,您通常需要一个映射表或外部库来执行转换。在没有外部库的情况下,您可能需要手动创建一个映射表或使用现有的开源映射数据。
实现UTF-8与GBK2312编码之间的转换而不使用第三方库是一个复杂的任务,因为这两种编码方式有很大的差异。UTF-8是一种变长的Unicode编码,而GBK2312是一种双字节编码,用于简化中文字符。
由于GBK2312并不包含所有的Unicode字符,并且其编码方式与UTF-8完全不同,因此无法简单地通过位操作或算术运算来完成转换。通常,这种转换需要查阅编码表或使用预先定义的映射。
请注意,这个示例不会包含完整的GBK2312到UTF-8的映射表,因为这样的表格通常非常大。在实际应用中,你通常需要使用现有的库或数据文件来提供这种映射。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 假设你有一个函数可以将GBK2312编码转换为UTF-8
char* gbk2312_to_utf8(const char* gbk, size_t gbk_len, size_t* utf8_len) {
// 在这里,你需要查阅GBK2312到UTF-8的映射表来完成转换。
// 这个示例不包含映射表。
char* utf8 = malloc(gbk_len * 3 + 1); // UTF-8最多可能需要3个字节
if (!utf8) return NULL;
// 这里应该是查阅映射表并进行转换的代码
// ...
*utf8_len = strlen(utf8); // 设置转换后的字符串长度
return utf8;
}
// 假设你有一个函数可以将UTF-8编码转换为GBK2312
char* utf8_to_gbk2312(const char* utf8, size_t utf8_len, size_t* gbk_len) {
// 在这里,你需要查阅UTF-8到GBK2312的映射表来完成转换。
// 这个示例不包含映射表。
char* gbk = malloc(utf8_len * 2 + 1); // GBK2312最多可能需要2个字节
if (!gbk) return NULL;
// 这里应该是查阅映射表并进行转换的代码
// ...
*gbk_len = strlen(gbk); // 设置转换后的字符串长度
return gbk;
}
int main() {
const char* gbk_str = "你的GBK字符串"; // 假设这是一个有效的GBK字符串
size_t utf8_len;
char* utf8_str = gbk2312_to_utf8(gbk_str, strlen(gbk_str), &utf8_len);
if (utf8_str) {
printf("GBK2312转换为UTF-8: %s\n", utf8_str);
free(utf8_str);
} else {
printf("GBK2312到UTF-8的转换失败。\n");
}
const char* utf8_input = "你的UTF-8字符串"; // 假设这是一个有效的UTF-8字符串
size_t gbk_len;
char* gbk_output = utf8_to_gbk2312(utf8_input, strlen(utf8_input), &gbk_len);
if (gbk_output) {
printf("UTF-8转换为GBK2312: %s\n", gbk_output);
free(gbk_output);
} else {
printf("UTF-8到GBK2312的转换失败。\n");
}
return 0;
}
在这个示例中,gbk2312_to_utf8 和 utf8_to_gbk2312 函数分别表示了两种转换的方向。这两个函数都需要查阅相应的编码映射表来完成转换。
实现UCS2与GBK2312编码之间的转换而不使用第三方库是一个具有挑战性的任务,因为这两种编码方式有很大的差异。UCS2(也称为UTF-16BE)是一种固定长度的Unicode编码,每个字符使用2个字节,而GBK2312是一种双字节编码,用于简化中文字符。
和前面的UTF-8与GBK2312转换类似,这种转换也需要查阅编码表或使用预先定义的映射。但是,由于GBK2312和UCS2的编码方式完全不同,不能通过简单的位操作或算术运算完成转换。
以下是使用C语言实现UCS2与GBK2312编码之间转换的大致框架。这个示例也不会包含完整的映射表,因为这样的表格通常非常大。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 假设你有一个函数可以将UCS2编码转换为GBK2312
char* ucs2_to_gbk2312(const uint16_t* ucs2, size_t ucs2_len, size_t* gbk_len) {
// 在这里,你需要查阅UCS2到GBK2312的映射表来完成转换。
// 这个示例不包含映射表。
char* gbk = malloc(ucs2_len * 2 + 1); // GBK最多可能需要2个字节
if (!gbk) return NULL;
// 这里应该是查阅映射表并进行转换的代码
// ...
*gbk_len = strlen(gbk); // 设置转换后的字符串长度
return gbk;
}
// 假设你有一个函数可以将GBK2312编码转换为UCS2
uint16_t* gbk2312_to_ucs2(const char* gbk, size_t gbk_len, size_t* ucs2_len) {
// 在这里,你需要查阅GBK2312到UCS2的映射表来完成转换。
// 这个示例不包含映射表。
uint16_t* ucs2 = malloc(gbk_len * sizeof(uint16_t) + 1); // UCS2每个字符需要2个字节
if (!ucs2) return NULL;
// 这里应该是查阅映射表并进行转换的代码
// ...
*ucs2_len = (strlen(ucs2) * sizeof(uint16_t)); // 设置转换后的字符串长度
return ucs2;
}
int main() {
const uint16_t* ucs2_str = L"你的UCS2字符串"; // 假设这是一个有效的UCS2字符串
size_t gbk_len;
char* gbk_str = ucs2_to_gbk2312(ucs2_str, wcslen(ucs2_str), &gbk_len);
if (gbk_str) {
printf("UCS2转换为GBK2312: %s\n", gbk_str);
free(gbk_str);
} else {
printf("UCS2到GBK2312的转换失败。\n");
}
const char* gbk_input = "你的GBK字符串"; // 假设这是一个有效的GBK字符串
size_t ucs2_len;
uint16_t* ucs2_output = gbk2312_to_ucs2(gbk_input, strlen(gbk_input), &ucs2_len);
if (ucs2_output) {
wprintf(L"GBK2312转换为UCS2: %ls\n", ucs2_output);
free(ucs2_output);
} else {
printf("GBK2312到UCS2的转换失败。\n");
}
return 0;
}
在这个示例中,ucs2_to_gbk2312 和 gbk2312_to_ucs2 函数分别表示了两种转换的方向。这两个函数都需要查阅相应的编码映射表来完成转换。
四、总结
UCS2、UTF8和GBK2312是三种不同的字符编码方式,它们各自有着不同的特点和适用场景。UCS2是一种固定长度的Unicode编码,适用于需要简单且直接的字符表示的场景;UTF8是一种可变长度的Unicode编码,适用于需要高效且兼容ASCII的文本处理场景;而GBK2312则是一种简体中文的字符编码标准,适用于需要支持简体中文的文本处理场景。在实际应用中,我们需要根据具体的需求选择合适的编码方式,并注意不同编码之间的转换问题。