原文地址: https://debezium.io/blog/2017/09/25/streaming-to-another-database/
欢迎关注留言,我是收集整理小能手,工具翻译,仅供参考,笔芯笔芯.
将数据流式传输到下游数据库
九月 25, 2017 作者: Jiri Pechanec
mysql postgres smt 示例
在这篇博文中,我们将创建一个简单的流数据管道来持续捕获 MySQL 数据库中的更改,并将它们近乎实时地复制到 PostgreSQL 数据库中。我们将展示如何在不编写任何代码的情况下完成此操作,而是通过使用和配置 Kafka Connect、Debezium MySQL 源连接器、Confluence JDBC 接收器连接器和一些单消息转换 (SMT)。
这种通过 Kafka 复制数据的方法本身确实非常有用,但当我们可以将近乎实时的数据更改流与其他流、连接器和流处理应用程序相结合时,它会变得更加有利。最近的Confluence 博客文章系列展示了类似的流数据管道,但使用不同的连接器和 SMT。Kafka Connect 的优点在于您可以混合和匹配连接器以在多个系统之间移动数据。
我们还将演示Debezium 0.6.0中发布的一项新功能: CDC 事件扁平化的单个消息转换。
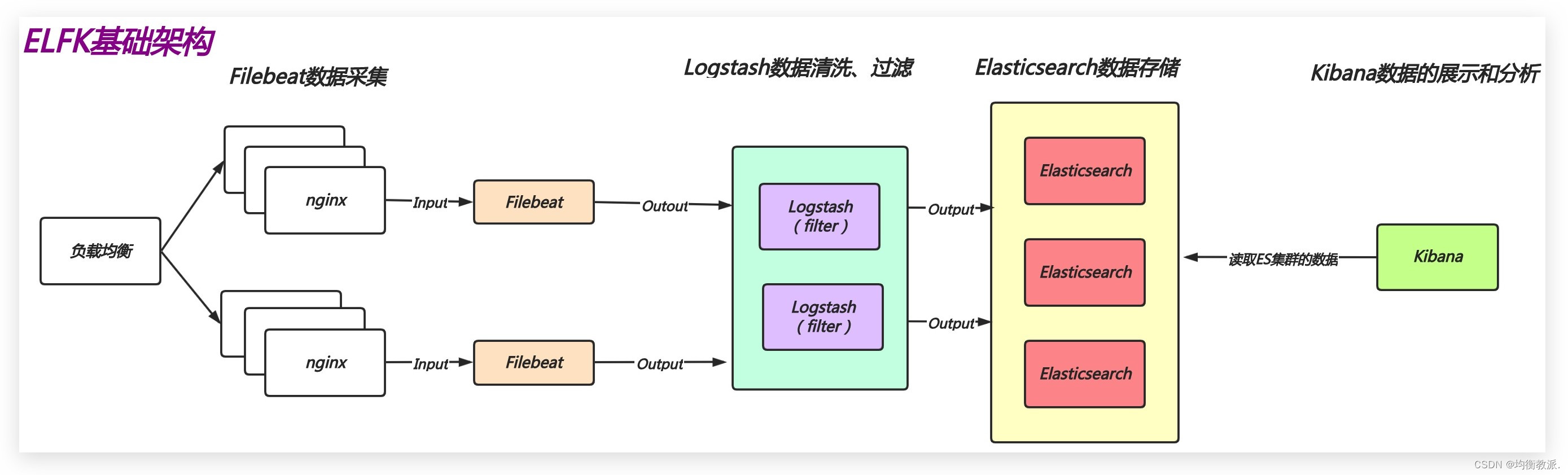
拓扑结构
该场景的一般拓扑如下图所示:
图片来源于debezium官网

图 1:一般拓扑
为了稍微简化设置,我们将仅使用一个包含所有连接器的 Kafka Connect 实例。即该实例将充当事件生产者和事件消费者:
图片来源于debezium官网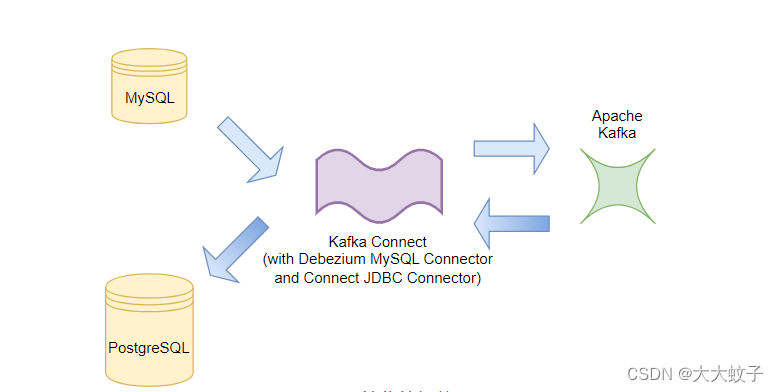
图 2:简化的拓扑
配置
我们将使用此组合来快速部署演示。该部署由以下 Docker 映像组成:
阿帕奇动物园管理员
阿帕奇·卡夫卡
经过更改的丰富的Kafka Connect / Debezium镜像
PostgreSQL JDBC 驱动程序放入/kafka/libs目录中
Kafka Connect JDBC Connector(由Confluence开发)放入/kafka/connect/kafka-connect-jdbc目录
我们的教程中使用的预填充 MySQL
空 PostgreSQL
Debezium MySQL 连接器旨在专门捕获数据库更改,并提供有关这些事件的尽可能多的信息,而不仅仅是每行的新状态。同时,Confluence JDBC Sink Connector 的设计目的是根据消息的结构将每条消息简单地转换为数据库插入/更新插入。因此,两个连接器具有不同的消息结构,但它们也使用不同的主题命名约定和表示已删除记录的行为。
当使用并非设计用于协同工作的连接器时,结构和行为上的不匹配很常见。但这是我们可以轻松处理的事情,我们将在接下来的几节中讨论如何处理。
活动形式
Debezium 以复杂的格式发出事件,其中包含有关捕获的数据更改的所有信息:操作类型、源元数据、连接器处理事件的时间戳以及更改前后的行状态。Debezium 将此结构称为“信封”:
{
“op”: “u”,
“source”: {
…
},
“ts_ms” : “…”,
“before” : {
“field1” : “oldvalue1”,
“field2” : “oldvalue2”
},
“after” : {
“field1” : “newvalue1”,
“field2” : “newvalue2”
}
}
许多其他 Kafka Connect 源连接器没有能力了解这么多有关更改的信息,而是使用更简单的模型,其中每条消息直接代表行的后状态。这也是许多接收器连接器所期望的,Confluence JDBC Sink Connector 也不例外:
{
“field1” : “newvalue1”,
“field2” : “newvalue2”
}
虽然我们认为 Debezium CDC 连接器提供尽可能多的细节实际上是一件很棒的事情,但我们还使您可以轻松地将 Debezium 的“信封”格式转换为许多其他连接器所期望的“行”格式。Debezium 以单一消息转换的形式提供了这两种格式之间的桥梁。该ExtractNewRecordState转换会自动提取新的行记录,从而有效地将复杂的记录扁平化为可由其他连接器使用的简单记录。
您可以在源连接器上使用此 SMT 在将消息写入 Kafka之前转换消息,也可以将源连接器更丰富的消息“信封”形式存储在 Kafka 中,并在接收器连接器上使用此 SMT 来转换消息从 Kafka 读取数据之后以及传递到接收器连接器之前。这两个选项都有效,这仅取决于您是否发现消息的信封形式可用于其他目的。
在我们的示例中,我们使用以下配置属性在接收器连接器上应用 SMT:
“transforms”: “unwrap”,
“transforms.unwrap.type”: “io.debezium.transforms.ExtractNewRecordState”,
删除记录
当 Debezium 连接器检测到行被删除时,它会创建两个事件消息:删除事件和逻辑删除消息。删除消息有一个信封,其中字段中包含已删除行的状态before,并且after字段为null。逻辑删除消息包含与删除消息相同的键,但整个消息值为null,Kafka 的日志压缩利用这一点来知道它可以删除任何具有相同键的较早消息。许多接收器连接器(包括 Confluence 的 JDBC 接收器连接器)并不期望这些消息,如果它们看到任何一种消息,就会失败。默认情况下, SMTExtractNewRecordState将过滤掉这两者删除和逻辑删除记录,但如果您使用 SMT 并希望保留其中一种或两种消息,则可以更改此设置。
主题命名
最后但并非最不重要的一点是,主题的命名有所不同。Debezium 对代表其管理的每个表的目标主题使用完全限定的命名。命名遵循模式..。Kafka Connect JDBC 连接器使用简单的名称。
在更复杂的场景中,用户可以部署Kafka Streams框架来在源路由和目标路由之间建立详细的路由。在我们的示例中,我们将使用库存RegexRouterSMT,它将 Debezium 创建的记录路由到根据 JDBC 连接器架构命名的主题中。同样,我们可以在源连接器或接收器连接器中使用此 SMT,但在本示例中,我们将在源连接器中使用它,以便我们可以选择将在其中写入记录的 Kafka 主题的名称。
“transforms”: “route”,
“transforms.route.type”: “org.apache.kafka.connect.transforms.RegexRouter”,
“transforms.route.regex”: “([.]+)\.([.]+)\.([^.]+)”,
“transforms.route.replacement”: “$3”
例子
踢轮胎,让我们试试我们的例子!
首先我们需要部署所有组件。
export DEBEZIUM_VERSION=0.6
docker-compose up
当所有组件启动后,我们将注册 JDBC Sink 连接器写入 PostgreSQL 数据库:
curl -i -X POST -H “Accept:application/json” -H “Content-Type:application/json” http://localhost:8083/connectors/ -d @jdbc-sink.json
使用此注册请求:
{
“name”: “jdbc-sink”,
“config”: {
“connector.class”: “io.confluent.connect.jdbc.JdbcSinkConnector”,
“tasks.max”: “1”,
“topics”: “customers”,
“connection.url”: “jdbc:postgresql://postgres:5432/inventory?user=postgresuser&password=postgrespw”,
“transforms”: “unwrap”, (1)
“transforms.unwrap.type”: “io.debezium.transforms.ExtractNewRecordState”,(1)
“auto.create”: “true”, (2)
“insert.mode”: “upsert”, (3)
“pk.fields”: “id”, (4)
“pk.mode”: “record_value” (4)
}
}
该请求配置这些选项:
将 Debezium 的复杂格式分解为简单格式
自动创建目标表
如果不存在则插入一行或更新现有行
识别存储在Kafka记录值字段中的主键
然后必须设置源连接器:
curl -i -X POST -H “Accept:application/json” -H “Content-Type:application/json” http://localhost:8083/connectors/ -d @source.json
使用此注册请求:
{
“name”: “inventory-connector”,
“config”: {
“connector.class”: “io.debezium.connector.mysql.MySqlConnector”,
“tasks.max”: “1”,
“database.hostname”: “mysql”,
“database.port”: “3306”,
“database.user”: “debezium”,
“database.password”: “dbz”,
“database.server.id”: “184054”,
“database.server.name”: “dbserver1”, (1)
“database.whitelist”: “inventory”, (2)
“database.history.kafka.bootstrap.servers”: “kafka:9092”,
“database.history.kafka.topic”: “schema-changes.inventory”,
“transforms”: “route”, (3)
“transforms.route.type”: “org.apache.kafka.connect.transforms.RegexRouter”, (3)
“transforms.route.regex”: “([.]+)\.([.]+)\.([^.]+)”, (3)
“transforms.route.replacement”: “$3” (3)
}
}
该请求配置这些选项:
数据库的逻辑名称
我们要监控的数据库
一个SMT,定义与主题名称匹配的正则表达式..,并提取其中的第三部分作为最终的主题名称
让我们检查一下数据库是否同步。表的所有行都customers应该在源数据库(MySQL)和目标数据库(Postgres)中找到:
docker-compose exec mysql bash -c ‘mysql -u
M
Y
S
Q
L
U
S
E
R
−
p
MYSQL_USER -p
MYSQLUSER−pMYSQL_PASSWORD inventory -e “select * from customers”’
±-----±-----------±----------±----------------------+
| id | first_name | last_name | email |
±-----±-----------±----------±----------------------+
| 1001 | Sally | Thomas | sally.thomas@acme.com |
| 1002 | George | Bailey | gbailey@foobar.com |
| 1003 | Edward | Walker | ed@walker.com |
| 1004 | Anne | Kretchmar | annek@noanswer.org |
±-----±-----------±----------±----------------------+
docker-compose exec postgres bash -c ‘psql -U $POSTGRES_USER $POSTGRES_DB -c “select * from customers”’
last_name | id | first_name | email
-----------±-----±-----------±----------------------
Thomas | 1001 | Sally | sally.thomas@acme.com
Bailey | 1002 | George | gbailey@foobar.com
Walker | 1003 | Edward | ed@walker.com
Kretchmar | 1004 | Anne | annek@noanswer.org
在连接器仍在运行的情况下,我们可以向 MySQL 数据库添加一个新行,然后检查它是否已复制到 PostgreSQL 数据库中:
docker-compose exec mysql bash -c ‘mysql -u
M
Y
S
Q
L
U
S
E
R
−
p
MYSQL_USER -p
MYSQLUSER−pMYSQL_PASSWORD inventory’
mysql> insert into customers values(default, ‘John’, ‘Doe’, ‘john.doe@example.com’);
Query OK, 1 row affected (0.02 sec)
docker-compose exec -postgres bash -c ‘psql -U $POSTGRES_USER $POSTGRES_DB -c “select * from customers”’
last_name | id | first_name | email
-----------±-----±-----------±----------------------
…
Doe | 1005 | John | john.doe@example.com
(5 rows)
概括
我们建立了一个简单的流数据管道,以近乎实时的方式将数据从 MySQL 数据库复制到 PostgreSQL 数据库。我们使用 Kafka Connect、Debezium MySQL 源连接器、Confluence JDBC 接收器连接器和一些 SMT 来完成此任务 - 所有这些都无需编写任何代码。由于它是一个流系统,它将继续捕获对 MySQL 数据库所做的所有更改并近乎实时地复制它们。
下一步是什么?
在未来的博客文章中,我们将使用 Elasticsearch 作为事件目标来重现相同的场景。




![[SWPUCTF 2021 新生赛]gift_F12](https://img-blog.csdnimg.cn/direct/7bb46ed524a94528b3ccec70d2d1b531.png)