文章目录
- Abstract
- Introduction
- The DETR model
- Object detection set prediction loss
- 二元匹配
- 匈牙利损失如下
- Bounding box loss
- DETR architecture
- Conclusion
hh
源代码
Abstract
我们提出了一种将目标检测视为直接集预测问题的新方法。我们的方法简化了检测管道,有效地消除了许多手工设计的组件,如非最大抑制过程或锚生成,这些组件显式地编码了我们对任务的先验知识。新框架的主要组成部分,被称为检测变压器或DETR,是一个基于集合的全局损失,它通过二元匹配强制进行唯一预测,以及一个变压器编码器-解码器架构。
给定一组固定的小学习对象查询,DETR对对象和全局图像上下文的关系进行推理,以直接并行输出最终的预测集。在具有挑战性的COCO对象检测数据集上,DETR展示了与成熟且高度优化的Faster R- CNN基线相当的准确性和运行时性能。此外,DETR可以很容易地推广到统一的全视分割。我们表明,它明显优于竞争基线。
Introduction
现代检测器的性能受后期处理步骤、锚点集的设计以及将目标框分配给锚点的启发式算法的显著影响。
我们通过将目标检测视为直接集预测问题来简化训练管道,我们采用了一种基于变压器的编码器-解码器架构[47],这是一种常用的序列预测架构
我们的检测变压器(DETR)一次预测所有对象,并使用一组损失函数进行端到端训练,该函数在预测对象和真实对象之间执行二部匹配。DETR通过删除多个手工设计的组件来简化检测流程,这些组件编码先验知识,如空间锚定或非最大抑制
与之前大多数直接集预测工作相比,DETR的主要特征是将二部匹配损失和Transformer与(非自回归)并行解码结合在一起
我们的实验表明,DETR在大型对象上表现出明显更好的性能,这可能是由Transformer的非局部计算实现的。然而,它在小对象上获得较低的性能
DETR具有很好的泛化能力。在我们的实验中,我们证明了在预训练的DETR之上训练的简单分割头在Panoptic segmentation上的表现优于竞争基线[19],这是一项具有挑战性的像素级识别任务
The DETR model
对于检测中的直接集预测来说,有两个要素是必不可少的:(1)集预测损失,它迫使在预测值和真实值之间的唯一匹配;(2)预测(单次)一组对象并为它们之间的关系建模的架构
Object detection set prediction loss
由于输出物体的顺序不一定与ground truth的序列相同,作者使用二元匹配将GT框与预测框进行匹配。
二元匹配

L match (y i, yhat σ(i))是基真y i与索引为σ(i)的预测之间的成对匹配代价
匹配方式采用的匈牙利算法
匈牙利算法详解
正如爱情里没有所谓的先到先得,它是先到先让
假设abc和def在两个集合里,a先配对到d;
如果b也配对到d,则a让出d,a再去配对其能配对的第2个(e);
然后c如果配对到e,则让a再找a能配对的第三个(假设只剩f),
如果c配对到d,则b先让出d,假设b第二次配对到f,则这时a再让出f
匈牙利损失如下

σ是在第一步(1)中计算的最优分配,ci为目标类标号(可以是∅),bi∈[0,1]^4是定义地面真值盒中心坐标及其相对于图像大小的高度和宽度的向量,即第i个框,pσ(i)表示σ(i)指向的元素对应各个类的概率分布,bσ(i)表示predictions中σ(i)指向的元素的bbox,1{ci≠∅}表示当目标类部位空时取值为1
Bounding box loss
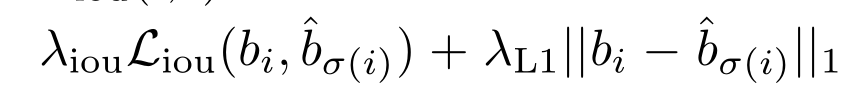
DETR architecture
整个DETR体系结构非常简单,它包含三个主要组件,提取紧凑特征表示的CNN主干,编码器-解码器Transformer,以及进行最终检测预测的简单前馈网络(FFN)。

在将其传递到Transformer编码器之前,模型将其扁平化并使用位置编码进行补充。然后,Transformer解码器将少量固定数量的学习到的位置嵌入(我们称之为对象查询)作为输入,并额外关注编码器输出。我们将解码器的每个输出嵌入传递给一个共享前馈网络(FFN),该网络预测检测(类和边界框)或“无对象”类
DETR可以在任何深度学习框架中实现,只要提供通用的CNN主干和变压器架构实现,只需几百行。在PyTorch中,DETR的推理代码可以用不到50行来实现[32]。
对于解码器,与原始Transformer的不同之处在于,我们的模型在每个解码器层并行解码N个对象,由于解码器也是排列不变的,因此N个输入嵌入必须不同才能产生不同的结果,与编码器类似,我们将它们添加到每个注意层的输入中。N个对象查询由解码器转换为输出嵌入。然后通过前馈网络将它们独立解码为框坐标和类标签,从而产生N个最终预测。在这些嵌入上使用自关注和编码器-解码器关注,该模型使用它们之间的成对关系全局地推断所有对象,同时能够使用整个图像作为上下文。
对于预测前馈网络FFN,最后的预测由一个具有ReLU激活函数和隐藏维数d的3层感知器和一个线性投影层来计算。FFN预测输入图像的归一化中心坐标、高度和宽度,线性层使用softmax函数预测类标签
Auxiliary decoding losses:我们发现在训练过程中,在解码器中使用辅助损失[1]是很有帮助的,特别是帮助模型输出每个类的正确对象数量。我们在每个解码器层后添加预测FFN和匈牙利损失,所有的预测FFN都共享它们的参数。我们使用一个额外的共享层规范来规范化来自不同解码器层的预测FFN的输入。
Conclusion
我们提出了一种新的基于transformers和二元匹配损失的目标检测系统,用于直接集预测。该方法在具有挑战性的COCO数据集上实现了与优化的Faster R-CNN基线相当的结果。DETR易于实现,具有灵活的架构,易于扩展到全光分割,具有竞争力的结果。此外,它在大型目标上的性能明显优于Faster R-CNN,这可能要归功于自关注对全局信息的处理。
这种检测器的新设计也带来了新的挑战,特别是在小物体的训练、优化和性能方面。目前的检测器需要几年的改进才能解决类似的问题,我们希望未来的工作能够成功地解决DETR的问题。