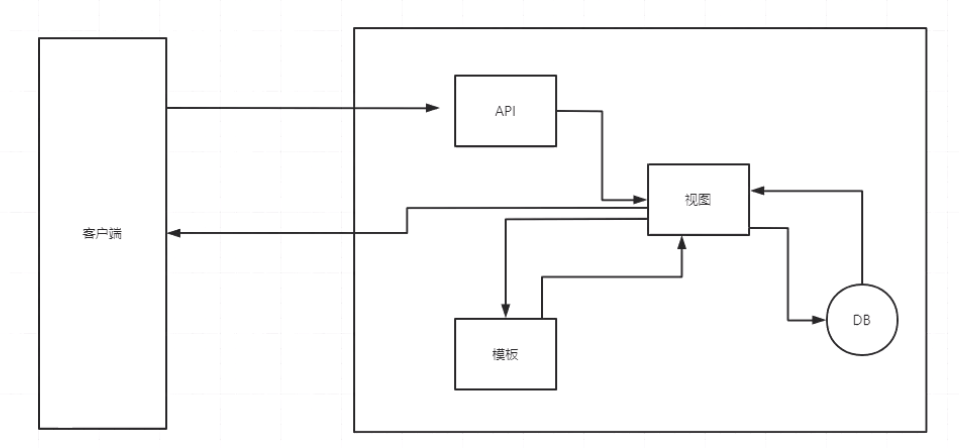
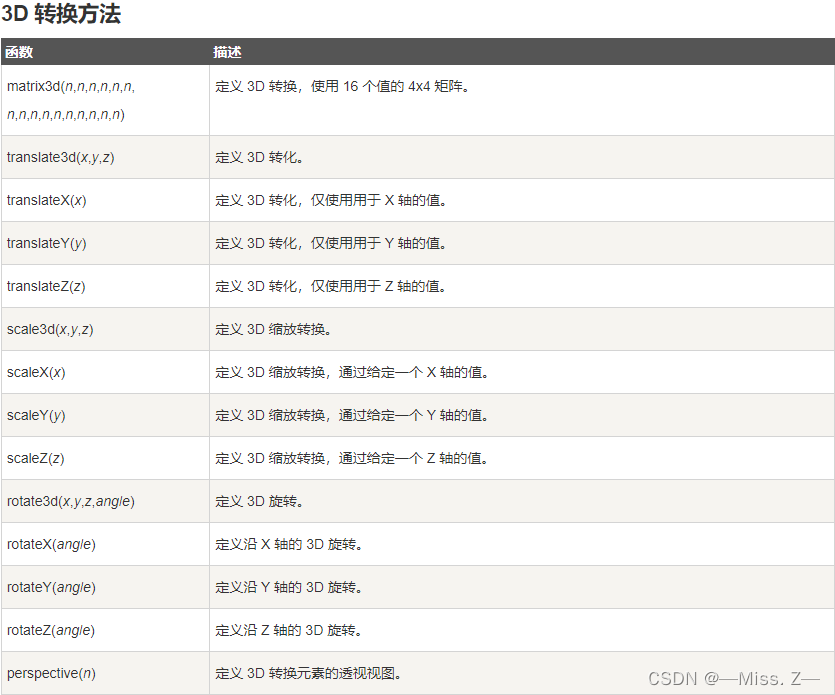
最近有个学妹学习遇到问题,想要的学习资料都在文库中,因为资料太多太杂,想要一篇篇找太难了,主要是太浪费精力了。因此,听说这个事情我能解决,立马找到我,给我一杯奶茶就把我收买了,拿人手短,东西都喝了,熬个通宵就解决完事情。

首先,这个需求需要使用到网络爬虫技术。C# 是一种常用的编程语言,可以用来编写网络爬虫程序。这里我们使用 C# 和第三方库 HtmlAgilityPack 来实现这个需求。
步骤如下:
1、安装必要的库。我们可以使用 NuGet 包管理器来安装 HtmlAgilityPack。
2、创建一个 C# 程序。我们需要编写一个 C# 类来实现网络爬虫功能。
3、设置代理信息。我们需要设置代理信息来爬取网站。在 C# 中,我们可以使用 HttpClient 类来设置代理信息。
4、获取网页内容。我们需要使用 HttpClient 类来获取网页内容。在获取网页内容时,我们需要设置请求的头部信息,以便正确解析网页内容。
5、解析网页内容。我们需要使用 HtmlAgilityPack 来解析网页内容。HtmlAgilityPack 是一个用于解析 HTML 和 XML 的库,它可以方便地解析网页内容。
6、提取需要的信息。我们需要从解析后的网页内容中提取需要的信息。我们可以使用 HtmlAgilityPack 提供的 API 来提取信息。
7、存储提取的信息。我们需要将提取的信息存储到本地文件或者数据库中。
请注意,爬虫程序可能会对网站服务器造成压力,因此在编写爬虫程序时,需要遵守网站的使用规则,尽量减少对服务器的请求。
以下是一个简单的示例代码:
using System;
using System.Net.Http;
using HtmlAgilityPack;
namespace WebCrawler
{
class Program
{
static void Main(string[] args)
{
// 创建 HttpClient 对象
var client = new HttpClient();
// 设置代理信息
// 提取代理IP jshk.com.cn/mb/reg.asp?kefu=xjy&csdn
client.DefaultRequestHeaders.Append("Proxy-Host", "duoip");
client.DefaultRequestHeaders.Append("Proxy-Port", "8000");
// 获取网页内容
var response = client.GetAsync("http://www renrenweng.com").Result;
response.EnsureSuccessStatusCode();
// 解析网页内容
var doc = new HtmlDocument();
doc.LoadHtml(response.Content.ReadAsStringAsync().Result);
// 提取需要的信息
var info = doc.DocumentNode.SelectSingleNode("//div[@class='download']/a/@href").Value;
// 存储提取的信息
Console.WriteLine("提取的信息:" + info);
}
}
}
这个示例代码使用 HttpClient 获取了网页内容,然后使用 HtmlAgilityPack 解析了网页内容,提取了需要的信息,并将信息输出到控制台。请注意,这只是一个简单的示例,实际的爬虫程序可能需要更复杂的逻辑。
其实说白了,爬虫就是绕过网站限制,并且利用第三方IP库不停的去爬取想要的数据而不被目标网站限制,所有好马配好鞍,好的代码也需要代理IP的辅助,这样才能让爬虫效率更高。今天就记录到这里,如果有更多的建议可以评论区留言讨论。






![力扣每日一题day36[112.路径总和]](https://img-blog.csdnimg.cn/img_convert/a1f33da4343b6696b8b450f7cd199895.jpeg)