1、cat:查看文件内容--上下合并文件
注意:cat只能查看普通的文本文件
如果文件内容过多会显示不全
| 选项 | 效果 |
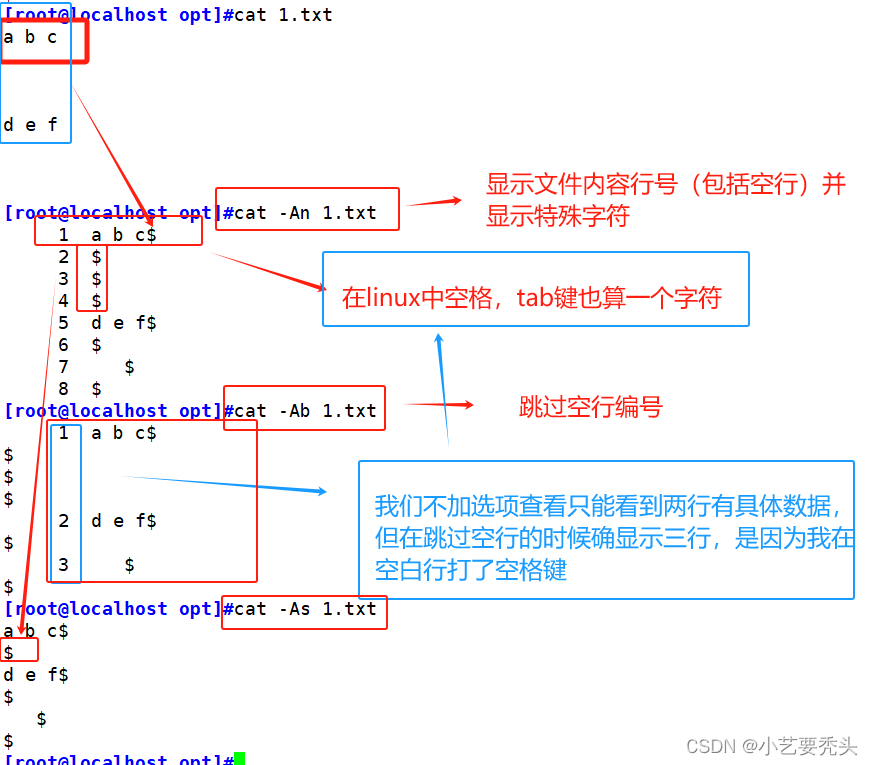
| -n | 显示行号包括空行 |
| -b | 跳过空白行编号;注意,在一行打了空格不算空白行,enter键直接跳过这一行才算 |
| -s | 将所有连续的多个空行替换成一个空行 |
| -A | 显示隐藏字符 |
1.1例子
1.2思考
如何将两个文件合并成一个文件?
在回答这个问题之前,我们要了解是标志输入,标志输出和重定向
标准输入:你输入的指令
标准输出:电脑反馈给你的信息
错误输出:电脑的一些报错信息,提示信息也是错误的。
重定向,重新定义标志输出方向 >
- > 一个是覆盖,全文覆盖
- >>两个是追加
- 注意:只有标准输出才可以改变方向


现在我们来回答如何合并文件?
1、上下合并用cat
2、左右合并用paste


1.3 tac--逆向显示文本内容

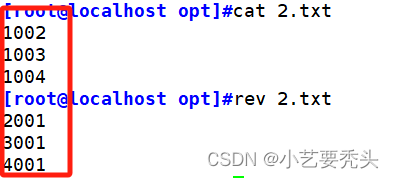
1.4 rev--同一行的内容逆向显示
2、paste:查看文件内容--左右合并文件
| 选项 | 效果 | |
| -d | 指定分隔符 | 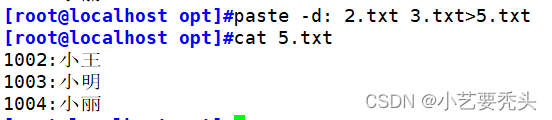 |
| -s | 不使用平行的行目输出模式,而是每个文件占用一行 | |
 | ||
3、more:全屏方式分页显示文件内容
基本操作
空格下一行 到文末后自动退出
b上一行
enter一行一行滚动
自动退出
q退出
注意:该命令不可以向上翻页,更建议使用less文件
4、less:全屏方式分页显示文件内容
基本操作
可以使用/ 查找
n向下 N向上查找
Page Up 向上翻页,Page Down 向下翻页
其余参考more
注意:less文件内容到底也不会自动退出
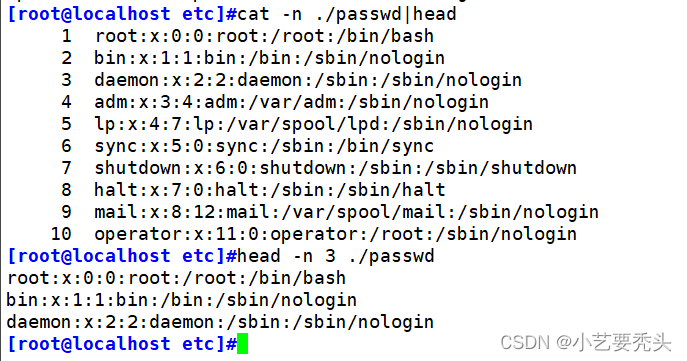
5、head:查看文件开头部分内容(默认10行)
格式:head [选项] [文件]
head -n 具体数字 文件名 (不加具体的数字,默认开头十行)
head -c #具体数字 取“#具体数字位“,中文占三个字符。
head -n -数字 去掉最后数字行


6、tail:查看文件结尾部分内容(默认10行)
tail -n 具体数字 文件名 (不加具体的数字,默认结尾十行)
tail -f 具体数字 文件名 实时跟踪最后十行
tailf==tail -f
tail -n +数字,从数字行开始显示

7、wc:统计文件内字节数、字数、行数
-l:统计行数
-w:统计单词个数
--并不是真正的单词,用空格或者tab键隔开算一个单词
-c:统计字节数

8、grep:过滤文件内容中的关键字
格式:grep [选项] 查找条件 目标文件
注意:这边的查找条件和目标文件的位置不能互换。
grep 后面跟的是正则表达式
. 任意字符
^ 一行的开头
$ 一行的结尾
^$ 空行
grep 过滤 文件中命中的字符
选项:
-i 查找时忽略大小写
-v 反向查找,输出与查找条件不相符的行(反选)
-o 只显示匹配项,只显示找出来的内容
-f 对比两个文件的相同行
-c 匹配的行数
-w 把字符串看成单词
8.1思考:
1、找出两个文件中相同的部分
- grep -f a文件 b文件
2、在某一文件夹中,快速找到所有含有root字符的文件?
如何快速过滤数据,找到含有特定字符的文件?
- grep -r 表达式 文件夹
9、split:分割文件

9.1 思考
我有一个10G的文件,怎么分割成小的文件存储?
split -b 100M 文件名
10、tar:归档
tar [选项] 压缩包的名字(*.tar.gz) 需要压缩的文件
-c 创建(Create).tar 格式的包文件
-C 解压时指定释放的目标文件夹
-x 解开.tar 格式的包文件
-f 表示使用归档文件 (一般都要带上表示使用tar)
-p 打包时保留文件及目录的权限
-P 打包时保留文件及目录的绝对径
-t 列表查看包内的文件 (要和f一起使用)在不解压的情况查看归档文件内容
-v 输出详细信息 (Verbose)
-j 调用 bzip2 程序进行压缩或解压
-z 调用 gzip 程序进行压缩或解压
注意:
- tar 一定要加 f 选项
- 加了 - f 选项,要放在在最后 ,不加没有顺序要求
- 解压的时可以不考虑 gz 还是 bzip2