文章目录
- 一、Linux线程概念
- 1.什么是线程
- 2.线程的优缺点
- 3.线程异常
- 4.线程用途
- 5.Linux进程VS线程
- 二、线程控制
- 1.线程创建
- 2.线程终止
- 3.线程等待
- 4.线程分离
一、Linux线程概念
1.什么是线程
线程是进程内的一个执行流。

我们知道,一个进程会有对应的PCB,虚拟地址空间,页表以及映射的物理内存。所以我们把这一个整体看做一个进程,即进程=内核数据结构+进程对应的代码和数据。我们可以这样看待虚存:虚拟内存决定了进程能够看到的"资源"。因为每一个进程都有对应的虚拟内存,所以进程具有独立性,从而进程需要通信的前提是看到同一份资源。我们fork创建子进程的时候,会将父进程的PCB的内容,进程地址空间和页表都给子进程拷贝一份。那么我们可不可以创建多个PCB,而这些PCB使用同一个进程地址空间和页表,这样就可以看到同一份资源了,这就是线程。
线程是进程内的一个执行流,线程咋进程内运行,线程在进程的地址空间内运行,拥有该进程的一部分资源。线程是CPU调度的基本单位。进程是承担系统资源的基本实体,内部可以有一个或多个执行流。因为我们可以通过虚拟地址空间+页表的方式对进程的资源进行划分,单个"进程"(线程)执行粒度,一定要比之前的进程要细。
如果我们OS系统真的要专门设计线程的概念,OS系统未来就需要对线程进行管理,就需要先描述,再组织,即一定要为线程设计专门的数据结构表示线程对象TCB。但是线程和进程一样都需要被执行,被调度(id,状态,优先级,上下文,栈…),二者十分相似,所以单纯从线程调度角度,线程和进程有很多的地方是重叠的。所以Linux工程师不想给"线程"专门设计对应的数据结构,而是直接复用PCB,用PCB用来表示Linux内部的"线程",所以在Linux中,进程我们称为轻量级进程。而windows有单独的TCB结构
总结:
1.Linux内核中没有真正意义是线程,Linux是用进程的PCB来进行模拟,是一种完全属于自己的一套线程方案
2.站在CPU视角,每一个PCB,都可以称之为轻量级进程
3.Linux线程是CPU调度的基本单位,而进程是承担资源分配的基本单位
4.进程用来整体申请资源,线程用来伸手向进程要资源
5.在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序列”
6.一切进程至少都有一个执行线程
7.线程在进程内部运行,本质是在进程地址空间内运行
8.在Linux系统中,在CPU眼中,看到的PCB都要比传统的进程更加轻量化
9.透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形成了线程执行流
Linux内核中没有真正意义是线程,所以Linux便无法直接提供创建线程的系统调用接口,而只能给我们提供创建轻量级进程的接口,但是操作系统只认线程,用户(程序员)也只认线程,所以Linux在软件层给我们提供了一个原生的线程库。

任何Linux操作系统,都必须默认携带这个原生线程库–用户级线程库
这里我们先见一见线程:
#include <iostream>
#include <cassert>
#include <unistd.h>
#include <pthread.h>
using namespace std;
void *start_routine(void *args)
{
while (true)
{
cout << "我是新线程, 我正在运行! " << endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
int n = pthread_create(&tid, nullptr, start_routine, (void *)"thread one");
assert(0 == n);
(void)n;
while (true)
{
cout << "我是主线程, 我正在运行!" << endl;
sleep(1);
}
return 0;
}

运行结果:

我们可以看到,有两个执行流在运行,这两个执行流的PID相同,而L不相同,其中LWP为light weight process为轻量级进程ID,我们知道线程的CPU调度的基本单位,那么就需要唯一的标识符,LWP就是线程的唯一标识符。
CPU调度的时候以LWP为标识符唯一的表示一个执行流
当我们只要一个执行流的时候:

此时PID==LWP
注意:
线程一旦被创建,几乎所有的资源都是被线程所共享的
线程也一定要有自己的私有资源:PCB私有,私有上下文结构,每一个线程都有自己独立的栈结构
线程切换和进程切换相比,线程之间的切换需要操作系统做的工作要少很多:
1.进程:切换页表 && 虚拟地址空间 && 切换PCB &&上下文切换
2.线程:切换PCB &&上下文切换
3.线程切换,cache不用太更新,进程切换需要全部更新。根据局部性原理我们知道,加载数据的时候会把需要访问的数据的周围数据也加载进去,所以执行流运行一段时间之后,cache里保存了许多热点数据,线程又使用相同的虚拟地址空间,所以线程切换的时候cache里面的数据就不用太更新,而进程是使用不同的虚拟地址空间,所以进程间切换的时候,需要重新加载数据
2.线程的优缺点
线程的优点
创建一个新线程的代价要比创建一个新进程小得多
与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
线程占用的资源要比进程少很多
能充分利用多处理器的可并行数量
在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
线程的缺点
性能损失
一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
健壮性降低
编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
缺乏访问控制
进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
编程难度提高
编写与调试一个多线程程序比单线程程序困难得多
3.线程异常
单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃,因为信号在整体发给进程的
线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出
#include <iostream>
#include <cassert>
#include <unistd.h>
#include <pthread.h>
using namespace std;
void *start_routine(void *args)
{
while (true)
{
cout << "我是新线程, 我正在运行! " << endl;
sleep(1);
int *p = nullptr;
*p = 0;
}
}
int main()
{
pthread_t tid;
int n = pthread_create(&tid, nullptr, start_routine, (void *)"thread one");
assert(0 == n);
(void)n;
while (true)
{
cout << "我是主线程, 我正在运行!" << endl;
sleep(1);
}
return 0;
}

4.线程用途
合理的使用多线程,能提高CPU密集型程序的执行效率
合理的使用多线程,能提高IO密集型程序的用户体验(如生活中我们一边写代码一边下载开发工具,就是多线程运行的一种表现)
5.Linux进程VS线程
进程是资源分配的基本单位
线程是调度的基本单位
线程共享进程数据,但也拥有自己的一部分数据:
线程ID
一组寄存器
栈
errno
信号屏蔽字
调度优先级
进程的多个线程共享 同一地址空间,因此Text Segment、Data Segment都是共享的,如果定义一个函数,在各线程
中都可以调用,如果定义一个全局变量,在各线程中都可以访问到,除此之外,各线程还共享以下进程资源和环境:
文件描述符表
每种信号的处理方式(SIG_ IGN、SIG_ DFL或者自定义的信号处理函数)
当前工作目录
用户id和组id
进程和线程的关系如下图:

二、线程控制
1.线程创建
POSIX线程库
与线程有关的函数构成了一个完整的系列,绝大多数函数的名字都是以“pthread_”打头的
要使用这些函数库,要通过引入头文<pthread.h>
链接这些线程函数库时要使用编译器命令的“-lpthread”选项
创建线程函数接口 – pthread_create
功能:创建一个新的线程
原型
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *
(*start_routine)(void*), void *arg);
参数
thread:返回线程ID
attr:设置线程的属性,attr为NULL表示使用默认属性
start_routine:是个函数地址,线程启动后要执行的函数
arg:传给线程启动函数的参数
返回值:成功返回0;失败返回错误码
错误检查:
传统的一些函数是,成功返回0,失败返回-1,并且对全局变量errno赋值以指示错误。
pthreads函数出错时不会设置全局变量errno(而大部分其他POSIX函数会这样做)。而是将错误代码通过返回值返回
pthreads同样也提供了线程内的errno变量,以支持其它使用errno的代码。对于pthreads函数的错误,建议通过返回值业判定,因为读取返回值要比读取线程内的errno变量的开销更小
我们这里创建10个进程,打印相关信息,主要是线程的tid
#include <iostream>
#include <cassert>
#include <unistd.h>
#include <vector>
#include <pthread.h>
using namespace std;
#define NUM 10
class ThreadData
{
public:
int number;
pthread_t tid;
char namebuffer[64];
};
void *start_routine(void *args)
{
ThreadData *td = static_cast<ThreadData *>(args);
int cnt = 10;
while (cnt)
{
cout << "new thread create success, name: " << td->namebuffer << " cnt: " << cnt-- << endl;
sleep(1);
}
return nullptr;
}
int main()
{
vector<ThreadData *> threads;
for (int i = 0; i < NUM; i++)
{
ThreadData *td = new ThreadData();
td->number = i + 1;
snprintf(td->namebuffer, sizeof(td->namebuffer), "thread:%d", i + 1);
pthread_create(&td->tid, nullptr, start_routine, td);
threads.push_back(td);
sleep(1);
}
for (auto &iter : threads)
{
cout << "create thread: " << iter->namebuffer << " : " << iter->tid << " suceesss" << endl;
}
return 0;
}

tid这么大的数字是什么呢,其实它是进程地址空间上的一个地址
我们知道,Linux中的线程使用的是原生线程库,那么,在原生线程库中就可能会存在多个线程,此时就需要对线程进行管理,管理的方法是先描述再组织。在Linux中,用户级线程,用户关系的线程属性在库中,内核中提供执行流的调度。Linux用户级线程:内核轻量级进程 = 1 : 1。
那么用户级线程的tid究竟是什么呢,是库中描述线程结构体的起始地址。所以pthread_t 到底是什么类型呢?取决于实现。对于Linux目前实现的NPTL实现而言,pthread_t类型的线程ID,本质就是一个进程地址空间上的一个地址。

每一个结构体就相当于一个线程控制块TCB,然后再使用数组进行管理,就完成了对线程的管理
线程ID及进程地址空间布局
pthread_ create函数会产生一个线程ID,存放在第一个参数指向的地址中。该线程ID和前面说的线程ID不是一回事。
前面讲的线程ID属于进程调度的范畴。因为线程是轻量级进程,是操作系统调度器的最小单位,所以需要一个数值来唯一表示该线程。
pthread_ create函数第一个参数指向一个虚拟内存单元,该内存单元的地址即为新创建线程的线程ID,属于NPTL线程库的范畴。线程库的后续操作,就是根据该线程ID来操作线程的。
线程库NPTL提供了pthread_ self函数,可以获得线程自身的ID:
获取线程ID函数接口–pthread_self
#include <pthread.h>
pthread_t pthread_self(void);
返回值是线程的id
2.线程终止
如果需要只终止某个线程而不终止整个进程,可以有三种方法:
1.从线程函数return。这种方法对主线程不适用,从main函数return相当于调用exit。
2.线程可以调用pthread_ exit终止自己。
3.一个线程可以调用pthread_ cancel终止同一进程中的另一个线程。
1.从线程函数return终止线程
从线程函数return之后终止进程就相当于函数调用完毕,线程终止
void *start_routine(void *args)
{
string name = static_cast<char*>(args);
int cnt = 10;
while (cnt)
{
cout << "thread name: " << name << " cnt: " << cnt-- << endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,start_routine,(void*)"thread one");
pthread_join(tid,nullptr);
return 0;
}

2.调用pthread_ exit终止线程
pthread_exit函数
功能:线程终止
原型
void pthread_exit(void *value_ptr);
参数
value_ptr:value_ptr不要指向一个局部变量。
返回值:无返回值,跟进程一样,线程结束的时候无法返回到它的调用者(自身)
需要注意,pthread_exit或者return返回的指针所指向的内存单元必须是全局的或者是用malloc分配的,不能在线程函数的栈上分配,因为当其它线程得到这个返回指针时线程函数已经退出了。
void *start_routine(void *args)
{
string name = static_cast<char*>(args);
int cnt = 10;
while (cnt)
{
cout << "thread name: " << name << " cnt: " << cnt-- << endl;
if(cnt<5)
{
pthread_exit(nullptr);
}
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,start_routine,(void*)"thread one");
while (true)
{
cout << "new thread create success, name: main thread" << endl;
sleep(1);
}
pthread_join(tid,nullptr);
return 0;
}

为什么我们不直接只有exit结束呢,而还要提供一个pthread_exit函数来终止线程,因为exit是通过发送信号的方式来终止的,但是信号是整体发给进程的,如果使用exit的话,主线程和新线程都会退出
3.调用pthread_ cancel终止线程
pthread_cancel函数
功能:取消一个执行中的线程
原型
int pthread_cancel(pthread_t thread);
参数
thread:线程ID
返回值:成功返回0;失败返回错误码

3.线程等待
为什么需要线程等待?
线程也是需要等待的,如果不进行等待,那么就会像僵尸进程一样,导致内存泄漏。
所以线程也必须进行等待:1.获取新线程的退出信息 2.回收新线程对应的PCB等内核资源,防止内存泄漏
已经退出的线程,其空间没有被释放,仍然在进程的地址空间内。
创建新的线程不会复用刚才退出线程的地址空间。
pthread_join函数接口
功能:等待线程结束
原型
int pthread_join(pthread_t thread, void **value_ptr);
参数
thread:线程ID
value_ptr:它指向一个指针,后者指向线程的返回值
返回值:成功返回0;失败返回错误码
调用该函数的线程将挂起等待,直到id为thread的线程终止。thread线程以不同的方法终止,通过pthread_join得到的
我们发现value_ptr的类型是二级指针,而start_routine函数的返回值是void*,那么会不会start_routine的返回值就是线程的退出信息呢,答案是是的。本质是从库中获取执行线程的退出结果
#include <iostream>
#include <cassert>
#include <unistd.h>
#include <vector>
#include <pthread.h>
using namespace std;
#define NUM 10
class ThreadData
{
public:
int number;
pthread_t tid;
char namebuffer[64];
};
class returnCode
{
public:
int exit_code;
int exit_result;
};
void *start_routine(void *args)
{
ThreadData *td = static_cast<ThreadData *>(args);
int cnt = 10;
while (cnt)
{
cout << "new thread create success, name: " << td->namebuffer << " cnt: " << cnt-- << endl;
sleep(1);
}
return (void*)td->number;
}
int main()
{
vector<ThreadData *> threads;
for (int i = 0; i < NUM; i++)
{
ThreadData *td = new ThreadData();
td->number = i + 1;
snprintf(td->namebuffer, sizeof(td->namebuffer), "thread:%d", i + 1);
pthread_create(&td->tid, nullptr, start_routine, td);
threads.push_back(td);
sleep(1);
}
for (auto &iter : threads)
{
void *ret = nullptr;
int n = pthread_join(iter->tid, (void **)&ret);
assert(n == 0);
cout << "join : " << iter->namebuffer << " sucess,exit_code: " << (long long)ret << endl;
delete iter;
}
return 0;
}

我们可以返回假的地址,整数,对空间的地址,对象的地址,栈上的地址都能够返回。
class ThreadReturn
{
public:
int exit_code;
int exit_result;
};
return (void *)td->number; // warning, void *ret = (void*)td->number;
return (void *)100;
pthread_exit((void *)111); // 既然假的地址,整数都能被外部拿到,那么如何返回的是,堆空间的地址呢?对象的地址呢?
ThreadReturn *tr = new ThreadReturn();
tr->exit_code = 1;
tr->exit_result = 100;
ThreadReturn tr; // 在栈上开辟的空间 return &tr;
return (void *)100; // 右值
我们需要注意的是:
我们使用一个void* ret来接收返回值,在函数pthread_join(tid,(void**)&ret)传递ret的地址进去,在start_routine函数中返回的是(void*)100;所以void** p = &ret; 而(void*) x = (void*)100;那么*p = x。
所以ret = x。

终止状态是不同的,总结如下:
1.如果thread线程通过return返回,value_ ptr所指向的单元里存放的是thread线程函数的返回值。
2.如果thread线程被别的线程调用pthread_ cancel异常终掉,value_ ptr所指向的单元里存放的是常数
PTHREAD_ CANCELED。
3.如果thread线程是自己调用pthread_exit终止的,value_ptr所指向的单元存放的是传给pthread_exit的参数。
4.如果对thread线程的终止状态不感兴趣,可以传NULL给value_ ptr参数。
为什么没有见到,线程退出的时候,对应的退出信号??? 线程出异常,收到信号,整个进程都会退出!
pthread_join:默认就认为函数会调用成功!不考虑异常问题,异常问题是你进程该考虑的问题!
4.线程分离
线程是可以等待的,等待的时候,join是阻塞式等待,如果我们不想等待呢。我们可以将线程设置为分离状态。
默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。
如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源。
pthread_detach函数接口
功能:线程分离
原型
int pthread_detach(pthread_t thread);
thread:线程ID
返回值:成功返回0;失败返回错误码
可以是线程组内其他线程对目标线程进行分离,也可以是线程自己分离:
pthread_detach(pthread_self());
joinable和分离是冲突的,一个线程不能既是joinable又是分离的。
void *start_routine(void *args)
{
string threadname = static_cast<char *>(args);
pthread_detach(pthread_self()); // 设置为分离状态
int cnt = 5;
while (cnt--)
{
cout << threadname << " running " << endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, start_routine, (void *)"thread one");
cout << "main thread running..." << endl;
//一个线程默认是joinable,如果设置的分离状态,就不能够进行等待了
int n = pthread_join(tid, nullptr);
cout << "result: " << n << " : " << strerror(n) << endl;
return 0;
}
线程未分离之前:

这是正常的退出。
将线程进行分离:
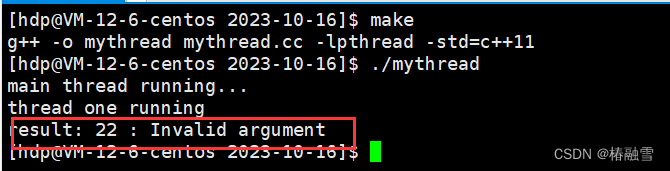
此时就出现了错误,印证了线程自己分离之后主线程再进行join。
如果没有出现错误,那么原因是我们无法判断那个执行流先运行,如果是主线程先运行,在新线程还没有分离之前,主线程就已经join处于阻塞状态,那么新线程进行分离之后,主线程就无法得知,因为主线程处于阻塞状态,那么也就不会发生错误,我们可以让主线程sleep(2),或者在主线程中创建线程之后就直接进行分离。


![NC65凭证保存时,报“错误:凭证内部错误号:[10001]凭证借贷金额不平!”](https://img-blog.csdnimg.cn/direct/f79fa83d5d90423cb6dba739e8c59f36.png)