目录
- 3. 最速下降法
- 3.1 最速下降法的基本思想
- 3.2 基于精确搜索的最速下降法
- 3.3 基于精确搜索的最速下降法的程序实现
- 3.4 基于精确搜索的最速下降法的缺点
- Reference
3. 最速下降法
3.1 最速下降法的基本思想
最速下降法是典型的线搜索方法. 设 f f f 是 R n \mathbb{R}^n Rn 上可微函数,在第 k k k 次迭代时,若 ∇ f ( x k ) = 0 \nabla f(x_k)=0 ∇f(xk)=0,则认为 x k x_k xk 已经是 f f f 的极小点,否则令 d k = − ∇ f ( x k ) . \begin{align} d_k=-\nabla f(x_k).\end{align} dk=−∇f(xk).则 ∇ f ( x k ) T d k = − ∥ ∇ f ( x k ) ∥ 2 < 0 \nabla f(x_k)^Td_k=-\|\nabla f(x_k)\|^2<0 ∇f(xk)Tdk=−∥∇f(xk)∥2<0.以 − ∇ f ( x k ) -\nabla f(x_k) −∇f(xk) 为线搜索方向的方法称为最速下降法.
梯度方向是函数值增长最快的方向,那么梯度的负方向就是函数值下降最快的方向。也就是说梯度下降法选取了函数下降最快的方向来作为搜索方向.
需要说明的是,函数下降最快不代表函数值的下降幅度最大.下面证明这点.
设目标函数
f
f
f 连续可微,将
f
f
f 在
x
k
x_k
xk 处Taylor展开:
f
(
x
)
=
f
(
x
k
)
+
∇
f
(
x
k
)
T
(
x
−
x
k
)
+
o
(
∣
∣
x
−
x
k
∣
∣
)
f(x)=f(x_k)+\nabla f(x_k)^T(x-x_k)+o(||x-x_k||)
f(x)=f(xk)+∇f(xk)T(x−xk)+o(∣∣x−xk∣∣)令
x
=
x
k
+
1
x=x_{k+1}
x=xk+1 ,结合
x
k
+
1
=
x
k
+
α
k
d
k
x_{k+1}=x_k+\alpha_kd_k
xk+1=xk+αkdk 迭代法可得:
f
(
x
k
+
1
)
=
f
(
x
k
)
+
α
k
∇
f
(
x
k
)
T
d
k
+
o
(
∣
∣
x
k
+
1
−
x
k
∣
∣
)
f(x_{k+1})=f(x_k)+\alpha_k\nabla f(x_k)^Td_k+o(||x_{k+1}-x_k||)
f(xk+1)=f(xk)+αk∇f(xk)Tdk+o(∣∣xk+1−xk∣∣)如果迭代的点列
{
x
k
}
\{x_{k}\}
{xk} 是收敛的,那么很显然有
x
k
+
1
−
x
k
→
0
(
k
→
∞
)
x_{k+1}-x_k\to0(k\to\infty)
xk+1−xk→0(k→∞) 。因此,我们有:
f
(
x
k
+
1
)
=
f
(
x
k
)
+
α
k
∇
f
(
x
k
)
T
d
k
f(x_{k+1})=f(x_k)+\alpha_k\nabla f(x_k)^Td_k
f(xk+1)=f(xk)+αk∇f(xk)Tdk 。
为了使得本次迭代有意义,即
f
(
x
k
+
1
)
<
f
(
x
k
)
f(x_{k+1})<f(x_k)
f(xk+1)<f(xk) ,需要确保
f
(
x
k
+
1
)
f(x_{k+1})
f(xk+1) 随着
α
k
\alpha_k
αk 的增大而减小 (
x
t
x_t
xt
的小领域内),即
∂
f
∂
α
=
∇
f
(
x
k
)
T
d
k
<
0
\frac{\partial f}{\partial\alpha}=\nabla f(x_k)^Td_k<0
∂α∂f=∇f(xk)Tdk<0 ,由于希望
f
(
x
t
+
1
)
f(x_{t+1})
f(xt+1) 下降得尽可能快,也就是想要的满足:
d
k
∗
=
arg
min
d
k
∂
f
∂
α
=
arg
max
d
k
−
∂
f
∂
α
d_k^*=\arg\min_{d_k}\frac{\partial f}{\partial\alpha}=\arg\max_{d_k}-\frac{\partial f}{\partial\alpha}
dk∗=argdkmin∂α∂f=argdkmax−∂α∂f由Cauchy不等式有:
−
∂
f
∂
α
=
−
∇
f
(
x
k
)
T
d
k
≤
∣
∣
∇
f
(
x
k
)
∣
∣
⋅
∣
∣
d
k
∣
∣
-\frac{\partial f}{\partial\alpha}=-\nabla f(x_k)^Td_k\leq||\nabla f(x_k)||\cdot||d_k||
−∂α∂f=−∇f(xk)Tdk≤∣∣∇f(xk)∣∣⋅∣∣dk∣∣根据Cauchy不等式成立的条件,当且仅当
d
k
d_k
dk 与
−
∇
f
(
x
t
)
-\nabla f(x_t)
−∇f(xt) 同向时,上述不等式的等号成立。所以下降最快的方向
d
k
∗
d_k^*
dk∗ 与
−
∇
f
(
x
k
)
-\nabla f(x_k)
−∇f(xk) 同向.也就是说梯度下降法只考虑了当前的函数关于
a
l
p
h
a
alpha
alpha 下降最快的方向,但不一定是函数值下降幅度最大的.
3.2 基于精确搜索的最速下降法
当
f
(
x
k
+
α
d
k
)
f(x_k+\alpha d_k)
f(xk+αdk) 关于
α
\alpha
α 可微时,精确搜索算法中由于
α
k
\alpha_k
αk 是最优步长, 那么必然有
d
d
t
f
(
x
k
+
t
d
k
)
∣
t
=
α
k
=
0
\frac d{dt}f(x_k+td_k)|_{t=\alpha_k}=0
dtdf(xk+tdk)∣t=αk=0 ,从而精确线搜索的迭代点列
x
k
+
1
=
x
k
+
α
k
d
k
x_{k+1}=x_k+\alpha_kd_k
xk+1=xk+αkdk 满足
∇
f
(
x
k
+
1
)
T
d
k
=
0
\nabla f(x_{k+1})^Td_k=0
∇f(xk+1)Tdk=0, 即当
∇
f
(
x
k
)
≠
0
\nabla f(x_k)\neq0
∇f(xk)=0 时,有
∇
f
(
x
k
+
1
)
T
d
k
=
0
,
其中
d
k
:
=
−
∇
f
(
x
k
)
.
\begin{align}\nabla f(x_{k+1})^Td_k&=0,\quad\text{其中}\quad d_k:=-\nabla f(x_k).\end{align}
∇f(xk+1)Tdk=0,其中dk:=−∇f(xk).考虑二次函数
f
(
x
)
=
1
2
x
T
A
x
+
b
T
x
+
c
,
f(x)=\frac12x^TAx+b^Tx+c,
f(x)=21xTAx+bTx+c,其中
A
∈
S
+
+
n
,
b
∈
R
n
,
c
∈
R
A\in\mathbb{S}_{++}^n,\:b\in\mathbb{R}^n,\:c\in\mathbb{R}
A∈S++n,b∈Rn,c∈R.由于
∇
f
(
x
k
+
1
)
=
A
x
k
+
1
+
b
\nabla f(x_{k+1})=Ax_{k+1}+b
∇f(xk+1)=Axk+1+b. 代入(2)便得
(
A
x
k
+
1
+
b
)
T
d
k
=
0.
(Ax_{k+1}+b)^Td_k=0.
(Axk+1+b)Tdk=0.将
x
k
+
1
=
x
k
+
α
k
d
k
x_{k+1}=x_k+\alpha_kd_k
xk+1=xk+αkdk 代入上式,并利用
∇
f
(
x
k
)
=
A
x
k
+
b
\nabla f(x_k)=Ax_k+b
∇f(xk)=Axk+b 整理便得
α
k
:
=
argmin
α
>
0
f
(
x
k
+
α
d
k
)
=
−
(
A
x
k
+
b
)
T
d
k
d
k
T
A
d
k
=
−
∇
f
(
x
k
)
T
d
k
d
k
T
A
d
k
.
\begin{align} \alpha_k:=\underset{\alpha>0}{\operatorname*{argmin}}f(x_k+\alpha d_k)=-\frac{(Ax_k+b)^Td_k}{d_k^TAd_k}=-\frac{\nabla f(x_k)^Td_k}{d_k^TAd_k}.\end{align}
αk:=α>0argminf(xk+αdk)=−dkTAdk(Axk+b)Tdk=−dkTAdk∇f(xk)Tdk.
下面看看用最速下降法求二次函数之收敛速度的估计. 记
∥
x
∥
A
2
:
=
x
T
A
x
,
∀
x
∈
R
n
.
\begin{aligned}\|x\|_A^2:=x^TAx,\quad\forall x\in\mathbb{R}^n.\end{aligned}
∥x∥A2:=xTAx,∀x∈Rn.实际上,最速下降法求二次函数的收敛速度是可求的,具体地如下面的命题所示.
命题 3.2 (精确搜索最速下降法之收敛速度) 设目标函数为 f ( x ) = 1 2 x T A x + b T x + c f(x)=\frac12x^TAx+b^Tx+c f(x)=21xTAx+bTx+c, 其中 A A A是一个 n n n 阶正定矩阵, b ∈ R n , c ∈ R b\in\mathbb{R}^n,\quad c\in\mathbb{R} b∈Rn,c∈R. 那么,任取初值 x 0 ∈ R n x_0\in\mathbb{R}^n x0∈Rn, 使用精确搜索的最速下降法所得的点列 { x k } \{x_k\} {xk} 当 x k ≠ x ∗ x_k\neq x^* xk=x∗ 时,有 ∥ x k + 1 − x ∗ ∥ A ∥ x k − x ∗ ∥ A ≤ c o n d ( A ) 2 − 1 c o n d ( A ) 2 + 1 , \begin{align}\frac{\|x_{k+1}-x^*\|_A}{\|x_k-x^*\|_A}\leq\frac{\mathbf{cond}(A)_2-1}{\mathbf{cond}(A)_2+1},\end{align} ∥xk−x∗∥A∥xk+1−x∗∥A≤cond(A)2+1cond(A)2−1,其中, x ∗ x^* x∗为 f f f 的极小值点,cond ( A ) 2 : = λ max / λ min ( A) _2: = \lambda_{\max }/\lambda_{\min } (A)2:=λmax/λmin 是矩阵 A A A 的条件数, λ max , λ min \lambda_{\max},\lambda_{\min} λmax,λmin 分别为 A A A 的最大和最小特征值.
证.设
x
∗
:
=
argmin
x
∈
R
n
f
(
x
)
x^*:=\operatorname{argmin}_{x\in\mathbb{R}^n}f(x)
x∗:=argminx∈Rnf(x).则
∇
f
(
x
∗
)
=
0
\nabla f(x^*)=0
∇f(x∗)=0.由于
∇
2
f
(
x
k
)
=
A
\nabla^2f(x_k)=A
∇2f(xk)=A ,且上文中我们规定了
∥
x
∥
A
2
:
=
x
T
A
x
,
∀
x
∈
R
n
.
\begin{aligned}\|x\|_A^2:=x^TAx,\quad\forall x\in\mathbb{R}^n.\end{aligned}
∥x∥A2:=xTAx,∀x∈Rn. ,于是可以得到
f
(
x
k
)
=
f
(
x
∗
)
+
1
2
(
x
k
−
x
∗
)
T
A
(
x
k
−
x
∗
)
=
f
(
x
∗
)
+
1
2
∥
x
k
−
x
∗
∥
A
2
.
\begin{aligned}f(x_k)&=f(x^*)+\frac12(x_k-x^*)^TA(x_k-x^*)=f(x^*)+\frac12\|x_k-x^*\|_A^2.\end{aligned}
f(xk)=f(x∗)+21(xk−x∗)TA(xk−x∗)=f(x∗)+21∥xk−x∗∥A2.将
k
k
k 换成
k
+
1
k+1
k+1, 有
f
(
x
k
+
1
)
=
f
(
x
∗
)
+
1
2
∥
x
k
+
1
−
x
∗
∥
A
2
.
\begin{aligned}f(x_{k+1})=f(x^*)+\frac{1}{2}\|x_{k+1}-x^*\|_A^2.\end{aligned}
f(xk+1)=f(x∗)+21∥xk+1−x∗∥A2.两式相减,得
f
(
x
k
+
1
)
−
f
(
x
k
)
=
1
2
(
∥
x
k
+
1
−
x
∗
∥
A
2
−
∥
x
k
−
x
∗
∥
A
2
)
.
f(x_{k+1})-f(x_k)=\frac12\big(\|x_{k+1}-x^*\|_A^2-\|x_k-x^*\|_A^2\big).
f(xk+1)−f(xk)=21(∥xk+1−x∗∥A2−∥xk−x∗∥A2).所以
∥
x
k
+
1
−
x
∗
∥
A
2
∥
x
k
−
x
∗
∥
A
2
=
1
+
2
f
(
x
k
+
1
)
−
f
(
x
k
)
∥
x
k
−
x
∗
∥
A
2
.
\begin{align}\frac{\|x_{k+1}-x^*\|_A^2}{\|x_k-x^*\|_A^2}=1+2\frac{f(x_{k+1})-f(x_k)}{\|x_k-x^*\|_A^2}.\end{align}
∥xk−x∗∥A2∥xk+1−x∗∥A2=1+2∥xk−x∗∥A2f(xk+1)−f(xk).记
g
k
:
=
∇
f
(
x
k
)
g_{k} :=\nabla f(x_k)
gk:=∇f(xk),可得
f
(
x
k
+
1
)
−
f
(
x
k
)
=
∇
f
(
x
k
)
T
(
x
k
+
1
−
x
k
)
+
1
2
(
x
k
+
1
−
x
k
)
T
A
(
x
k
+
1
−
x
k
)
=
α
k
g
k
T
d
k
+
1
2
α
k
2
d
k
T
A
d
k
.
\begin{align}\begin{aligned}f(x_{k+1})-f(x_{k})&=\nabla f(x_k)^T(x_{k+1}-x_k)+\frac{1}{2}(x_{k+1}-x_k)^TA(x_{k+1}-x_k)\\ &=\alpha_kg_k^Td_k+\frac12\alpha_k^2d_k^TAd_k.\end{aligned} \end{align}
f(xk+1)−f(xk)=∇f(xk)T(xk+1−xk)+21(xk+1−xk)TA(xk+1−xk)=αkgkTdk+21αk2dkTAdk.
利用
d
k
=
−
g
k
d_k=-g_k
dk=−gk 和(3)有
α
k
=
−
g
k
T
d
k
d
k
T
A
d
k
=
g
k
T
g
k
g
k
T
A
g
k
,
α
k
g
k
T
d
k
=
−
(
g
k
T
g
k
)
2
g
k
T
A
g
k
,
1
2
α
k
2
d
k
T
A
d
k
=
1
2
(
g
k
T
g
k
)
2
g
k
T
A
g
k
.
\begin{gathered} \alpha_{k}=-\frac{g_{k}^{T}d_{k}}{d_{k}^{T}Ad_{k}}=\frac{g_{k}^{T}g_{k}}{g_{k}^{T}Ag_{k}},\quad\alpha_{k}g_{k}^{T}d_{k}=-\frac{(g_{k}^{T}g_{k})^{2}}{g_{k}^{T}Ag_{k}},\quad\frac{1}{2}\alpha_{k}^{2}d_{k}^{T}Ad_{k}=\frac{1}{2}\frac{(g_{k}^{T}g_{k})^{2}}{g_{k}^{T}Ag_{k}}. \\\end{gathered}
αk=−dkTAdkgkTdk=gkTAgkgkTgk,αkgkTdk=−gkTAgk(gkTgk)2,21αk2dkTAdk=21gkTAgk(gkTgk)2.代入(6)便得
f
(
x
k
+
1
)
−
f
(
x
k
)
=
−
1
2
(
g
k
T
g
k
)
2
g
k
T
A
g
k
.
\begin{aligned}f(x_{k+1})-f(x_k)=-\frac{1}{2}\frac{(g_k^Tg_k)^2}{g_k^TAg_k}.\end{aligned}
f(xk+1)−f(xk)=−21gkTAgk(gkTgk)2.
因
A
(
x
∗
+
b
)
=
∇
f
(
x
∗
)
=
0
A(x^*+b)=\nabla f(x^*)=0
A(x∗+b)=∇f(x∗)=0, 我们有
g
k
=
A
x
k
+
b
=
A
(
x
k
−
x
∗
)
g_k=Ax_k+b=A(x_k-x^*)
gk=Axk+b=A(xk−x∗).即
x
k
−
x
∗
=
A
−
1
g
k
.
x_k-x^*=A^{-1}g_k.
xk−x∗=A−1gk.所以有
∥
x
k
−
x
∗
∥
A
2
=
g
k
T
(
A
−
1
)
T
A
A
−
1
g
k
=
g
k
T
A
−
1
g
k
.
\begin{aligned}\|x_k-x^*\|_A^2&=g_k^T(A^{-1})^TAA^{-1}g_k&=g_k^TA^{-1}g_k.\end{aligned}
∥xk−x∗∥A2=gkT(A−1)TAA−1gk=gkTA−1gk.
代入(5)便得
∥
x
k
+
1
−
x
∗
∥
A
2
∥
x
k
−
x
∗
∥
A
2
=
1
−
(
g
k
T
g
k
)
2
(
g
k
T
A
g
k
)
(
g
k
T
A
−
1
g
k
)
.
\begin{gathered} \begin{aligned}\frac{\|x_{k+1}-x^*\|_A^2}{\|x_k-x^*\|_A^2}&=1-\frac{(g_k^Tg_k)^2}{(g_k^TAg_k)(g_k^TA^{-1}g_k)}.\end{aligned} \end{gathered}
∥xk−x∗∥A2∥xk+1−x∗∥A2=1−(gkTAgk)(gkTA−1gk)(gkTgk)2.利用 Kantorovich 不等式
(
x
T
x
)
2
(
x
T
A
x
)
(
x
T
A
−
1
x
)
≥
4
λ
max
λ
min
(
λ
max
+
λ
min
)
2
,
∀
x
∈
R
n
∖
{
0
}
,
\begin{aligned}\frac{(x^Tx)^2}{(x^TAx)(x^TA^{-1}x)}\geq\frac{4\lambda_{\max}\lambda_{\min}}{(\lambda_{\max}+\lambda_{\min})^2},\quad\forall x\in\mathbb{R}^n\setminus\{0\},\end{aligned}
(xTAx)(xTA−1x)(xTx)2≥(λmax+λmin)24λmaxλmin,∀x∈Rn∖{0},
其中 λ m a x , λ m i n λ_{max}, λ_{min} λmax,λmin分别为 A A A 的最大和最小特征值,化简即得(4).
根据上面的证明可以发现利用最速下降法求二次函数的极小点的收敛阶至少是线性的.并且由于矩阵 A A A 是对称正定矩阵,那么根据解析几何相关的知识可以知道 f ( x ) f(x) f(x) 的等值面是一个椭球,而椭球的轴长就是 A A A 的各特征值,并且其最长轴和最短轴之比恰为 A A A 的谱条件数 c o n d ( A ) 2 \mathbf{cond}(A)_2 cond(A)2,并且可以知道条件数的值越大,则 f ( x ) f(x) f(x) 的等高面的长轴与短轴相差越大(也就是说椭球会越扁), 迭代点列的收敛就越慢.当谱条件数 c o n d ( A ) 2 \mathbf{cond}(A)_2 cond(A)2接近 1 时,等高线接近一个球,此时收敛很快.特别地,当谱条件数 c o n d ( A ) 2 \mathbf{cond}(A)_2 cond(A)2 = 1 时 , ∥ x 1 − x ∗ ∥ A = 0 ∥x_1 − x∗∥A = 0 ∥x1−x∗∥A=0, 也就是说只需要一次迭代就可以达到精确解.
3.3 基于精确搜索的最速下降法的程序实现
最优步长的推导
在此之前我们还需要讨论一下基于精确搜索的二次目标函数的最优步长应该如何选取.设讨论的二次型函数如下: f ( x ) = 1 2 x T Q x + b T x + c f(x)=\frac12x^TQx+b^Tx+c f(x)=21xTQx+bTx+c其中 x x x 是 n n n 维列向量, A A A 是实对称正定矩阵, b b b 是与 x x x 维度相同的列向量, c ∈ R c \in \mathbb{R} c∈R.
我们记
g
k
=
∇
f
(
x
k
)
g_k=\nabla f(x_k)
gk=∇f(xk) 。由矩阵求导的性质以及
A
A
A 是对称矩阵,那么有
∇
f
(
x
k
)
=
A
x
k
+
b
\nabla f(x_k)=Ax_k+b
∇f(xk)=Axk+b 时,就可以开始在
d
k
=
−
∇
f
(
x
k
)
d_k=-\nabla f(x_k)
dk=−∇f(xk) 的方向上实施精确线搜索,从而得到最优步长
α
∗
\alpha^*
α∗ 了:
α
∗
=
arg
min
α
f
(
x
k
+
α
d
k
)
=
arg
min
α
f
(
x
k
−
α
g
k
)
=
arg
min
α
(
1
2
g
k
T
A
g
k
α
2
−
g
k
T
g
k
α
+
f
(
x
k
)
)
\begin{aligned} \alpha^{*}& =\arg\min_\alpha f(x_k+\alpha d_k) \\ &=\arg\min_\alpha f(x_k-\alpha g_k) \\ &=\arg\min_\alpha\left(\frac12g_k^TAg_k\alpha^2-g_k^Tg_k\alpha+f(x_k)\right) \end{aligned}
α∗=argαminf(xk+αdk)=argαminf(xk−αgk)=argαmin(21gkTAgkα2−gkTgkα+f(xk))注意到上述函数是关于
α
\alpha
α 的二次函数,故最优步长
α
∗
\alpha^*
α∗ 为:
α
∗
=
g
k
T
g
k
g
k
T
A
g
k
\alpha^*=\frac{g_k^Tg_k}{g_k^TAg_k}
α∗=gkTAgkgkTgk因此在对正定二次型做梯度下降时,通过上述上述上述的精确线搜索得到最优步长后,更新迭代式为
x
k
+
1
=
x
k
−
g
k
T
g
k
g
k
T
A
g
k
(
A
x
k
+
b
)
x_{k+1}=x_k-\frac{g_k^Tg_k}{g_k^TAg_k}(Ax_k+b)
xk+1=xk−gkTAgkgkTgk(Axk+b)下面做一个正定二次型的最速下降法实现的总结,已知迭代的终止条件参数
ϵ
\epsilon
ϵ。初始迭代点为
x
0
x_0
x0,记
g
k
=
∇
f
(
x
k
)
g_k=\nabla f(x_k)
gk=∇f(xk),重复以下操作 :
1.计算 d k = − ∇ f ( x k ) d_k=-\nabla f(x_k) dk=−∇f(xk),若 ∣ ∣ d t ∣ ∣ < ϵ ||d_t||<\epsilon ∣∣dt∣∣<ϵ,迭代终止,否则执行下一步
2.计算精确线搜索的最优步长: α ∗ = g k T g k g k T A g k \alpha^*=\frac{g_k^Tg_k}{g_k^TAg_k} α∗=gkTAgkgkTgk
3.通过迭代式 x k + 1 = x k − g k T g k g k T A g k ( A x k + b ) x_{k+1}=x_k-\frac{g_k^Tg_k}{g_k^TAg_k}(Ax_k+b) xk+1=xk−gkTAgkgkTgk(Axk+b) 更新得到下一个迭代点,然后回退到第一步
程序实现
实际上,可以证明利用最速下降法来求二次函数的最优化问题时,如果存在局部最优点,那么该点是一定全局最优点,也就是说该优化问题满足全局收敛性.
下面基于此事实,利用Python来看看基于精确所搜的最速下降法的程序实现.
设需要优化的目标二次函数如下:
f
(
x
)
=
1
2
x
T
Q
x
+
b
T
x
,
Q
=
(
10
−
9
−
9
10
)
,
b
=
(
4
,
−
15
)
T
f(x)=\frac12x^TQx+b^Tx,Q=\begin{pmatrix}10&-9\\-9&10\end{pmatrix},b=(4,-15)^T
f(x)=21xTQx+bTx,Q=(10−9−910),b=(4,−15)T为了检验迭代过程的可靠性,我们可以解析地求出该优化问题的最优点:
x
∗
=
−
Q
−
1
b
=
(
5
,
6
)
T
x^*=-Q^{-1}b=(5,6)^T
x∗=−Q−1b=(5,6)T此外我们还需要定义目标函数中的
Q
,
b
Q,b
Q,b 还有原本的函数
f
f
f 和函数梯度
∇
f
\nabla f
∇f 的映射func和gradient.准备工作部分的代码如下:
# 准备工作
import numpy as np
import matplotlib.pyplot as plt
Q = np.array([[10, -9], [-9, 10]], dtype="float32") # 矩阵Q
b = np.array([4, -15], dtype="float32").reshape([-1, 1]) # 向量b
# function and its gradient defined in the question
func = lambda x: 0.5 * np.dot(x.T, np.dot(Q, x)).squeeze() + np.dot(b.T, x).squeeze() # 利用lambda表达式定义目标函数:1/2 x^T*Q*x + b^Tx
gradient = lambda x: np.dot(Q, x) + b # 定义梯度 = f' = Qx + b
x_0 = np.array([5, 6]).reshape([-1, 1]) # 定义最优点
准备工作完成后,编写基于精确搜索的最速下降法的函数实现:
# GD algorithm
def gradient_descent(start_point, func, gradient, epsilon=0.01):
"""
:param start_point: start point of GD 初始值
:param func: map of plain function 目标函数
:param gradient: gradient map of plain function 梯度函数
:param epsilon: threshold to stop the iteration 迭代终止的阈值
:return: converge point, # iterations
"""
assert isinstance(start_point, np.ndarray) # assert that input start point is ndarray
global Q, b, x_0 # claim the global varience
x_k_1, iter_num, loss = start_point, 0, []
xs = [x_k_1] # xs是迭代点的序列,最后一个就是最后一次求的点
while True:
g_k = gradient(x_k_1).reshape([-1, 1])
if np.sqrt(np.sum(g_k ** 2)) < epsilon:
break
alpha_k = np.dot(g_k.T, g_k).squeeze() / (np.dot(g_k.T, np.dot(Q, g_k))).squeeze()
x_k_2 = x_k_1 - alpha_k * g_k
iter_num += 1
xs.append(x_k_2)
loss.append(float(np.fabs(func(x_k_2) - func(x_0))))
if np.fabs(func(x_k_2) - func(x_k_1)) < epsilon:
break
x_k_1 = x_k_2
return xs, iter_num, loss
假设此处的迭代初值为 x 0 = ( 4 , 4 ) T x_0=(4,4)^T x0=(4,4)T ,进行梯度下降法,并可视化迭代过程:
x0 = np.array([4,4], dtype="float32").reshape([-1, 1])
xs, iter_num, loss = gradient_descent(start_point=x0,
func=func,
gradient=gradient,
epsilon=1e-6)
print(xs[-1]) # last point of the sequence
plt.style.use("seaborn") # 样式
plt.figure(figsize=[12, 6]) # 大小
plt.plot(loss)
plt.xlabel("# iteration", fontsize=12)
plt.ylabel("Loss: $|f(x_k) - f(x^*)|$", fontsize=12)
plt.yscale("log") # 对y轴取log
plt.show()
运行结果:
[[4.999424]
[5.998852]]
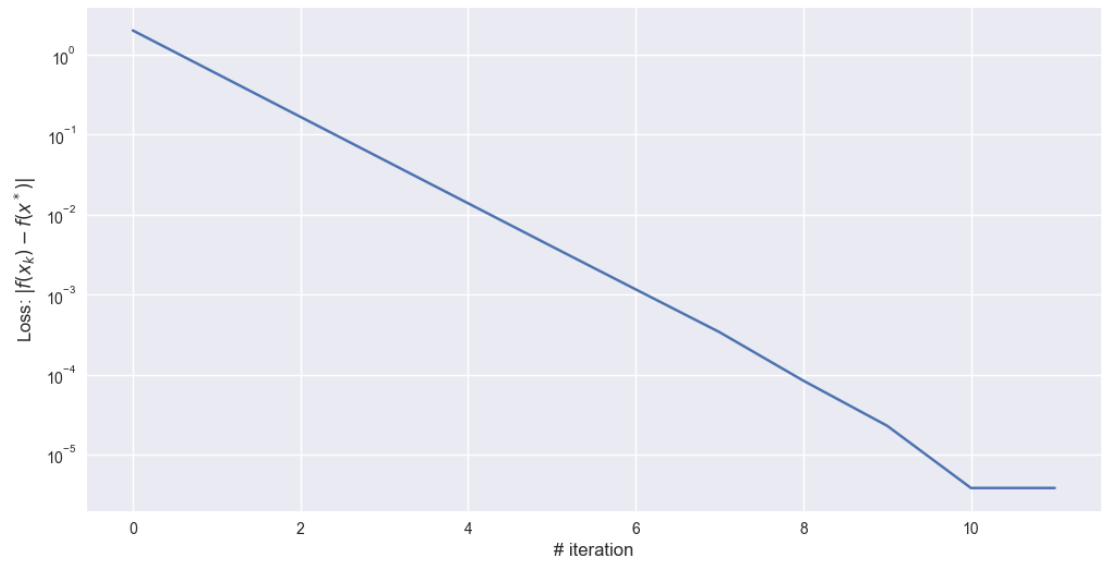
可以看到最终迭代点到达了最优点 ( 5 , 6 ) T (5,6)^T (5,6)T。当纵坐标取对数 l o g log log 时,收敛速率近似是线性的。也就是说梯度下降法用于优化是可行的,收敛速率也不错。但是结论还不能够下得太早,我们在更换几组初始点,并把相关的参数画在一个图像内看看效果.
我们再取四个迭代点: ( 0 , 0 ) , ( 0.4 , 0 ) , ( 10 , 0 ) , ( 11 , 0 ) (0,0),(0.4,0),(10,0),(11,0) (0,0),(0.4,0),(10,0),(11,0)
# create the list of all starting point x_0
starting_points = [np.array([num, 0]).astype(np.float).reshape([-1, 1]) for num in [0.0, 0.4, 10.0, 11.0]]
plt.figure(dpi=150)
xss = []
# implement GD
for idx, start_point in enumerate(starting_points):
xs, iter_num, losses = gradient_descent(start_point, func, gradient, epsilon=1e-6)
target_point = xs[-1]
xss.append(xs)
# plot the losses of $|f(x_k) - f(x^*)|$
plt.plot(np.arange(len(losses)), np.array(losses), label=f"start point: ({start_point[0][0]}, {start_point[1][0]})")
loss = np.fabs(func(target_point) - func(x_0))
print(f"{idx + 1}: start point:{np.round(start_point, 5).tolist()}, "
f"point after GD:{np.round(target_point, 5).tolist()}, "
f"loss:{np.round(loss, 16)}, # iterations: {iter_num}")
print("-" * 60)
plt.grid(True)
plt.legend()
plt.xlabel("# iteration", fontsize=12)
plt.ylabel("Loss: $|f(x_k) - f(x^*)|$", fontsize=12)
plt.yscale("log")
plt.title("Loss-iteration given to different starting points of GD", fontsize=18)
plt.show()
输出结果:
1: start point:[[0.0], [0.0]], point after GD:[[4.99855], [5.99826]], loss:2.9518850226e-06, # iterations: 60
------------------------------------------------------------
2: start point:[[0.4], [0.0]], point after GD:[[4.99902], [5.99873]], loss:1.6873629107e-06, # iterations: 42
------------------------------------------------------------
3: start point:[[10.0], [0.0]], point after GD:[[5.0], [6.0]], loss:1.33369e-11, # iterations: 4
------------------------------------------------------------
4: start point:[[11.0], [0.0]], point after GD:[[5.0], [6.0]], loss:0.0, # iterations: 1
------------------------------------------------------------
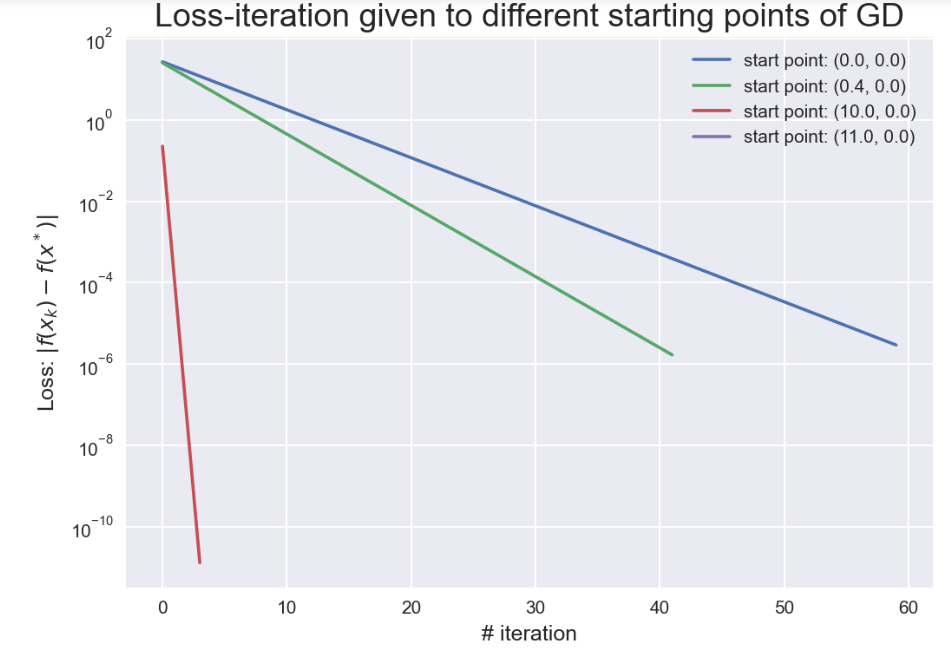
由上图可以看到可以看到不同的初值点,收敛速率不相同。也就是说不同的初始点到达最优点的所需的迭代次数不一样.为了更好滴感受不同初始点选取的差异,可以把上述过程在二维平面内可视化出来:
plt.figure(dpi=150)
X = np.linspace(-2, 12, 200)
Y = np.linspace(-2, 12, 200)
XX, YY = np.meshgrid(X, Y)
Z = [func(np.array([XX[i, j], YY[i, j]], dtype="float32").reshape([-1, 1])).tolist() for i in range(200) for j in range(200)]
Z = np.array(Z).reshape([200, 200])
plt.contourf(XX, YY, Z, cmap=plt.cm.BuGn)
plt.annotate(f"$(5.0, 6.0)$",
xy=(5, 6),
xytext=(5 - 2, 6 + 2),
arrowprops={
"color" : "black",
"shrink" : 0.1,
"width" : 0.6
})
# plot the scatter
for idx, start_point in enumerate(starting_points):
xx = [xss[idx][i][0] for i, _ in enumerate(xss[idx])]
yy = [xss[idx][i][1] for i, _ in enumerate(xss[idx])]
plt.plot(xx, yy, "o--", label=f"start point: ({start_point[0][0]}, {start_point[1][0]})")
# add some tips for start point
plt.annotate(f"$({start_point[0][0]}, {start_point[1][0]})$",
xy=(start_point[0][0], start_point[1][0]),
xytext=(start_point[0][0] - 1.5, start_point[1][0] + idx + 2),
arrowprops={
"color" : "black",
"shrink" : 0.1,
"width" : 0.6
})
plt.grid(True)
plt.title("Line Search For Two-dimensional Diagrams", fontsize=18)
plt.xlabel("$x_1$", fontsize=12)
plt.ylabel("$x_2$", fontsize=12)
plt.legend()
plt.show()
运行结果:
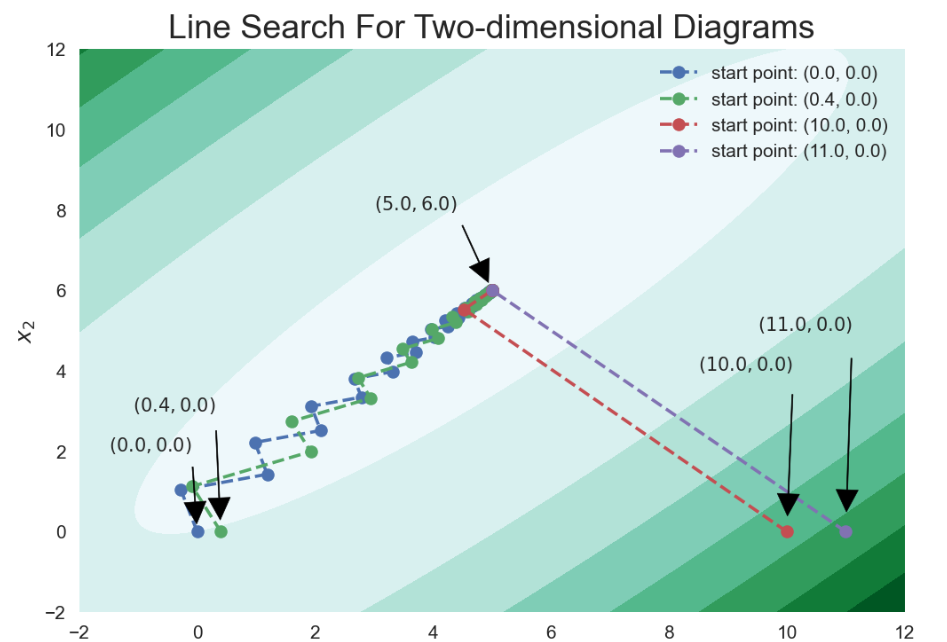
这张图可以直观地感受四个迭代点的迭代步数的差距。究其原因,我们在命题 3.2中提到,等高线代表的椭圆的长轴和短轴比的含义,不同初始点的选取所位于的等高面是不一样的,如果位于狭长的区域则收敛的速度会相应地快些,这是因为梯度方向的值要大些,从上图中可以直观的感受.
3.4 基于精确搜索的最速下降法的缺点
首先拿简单的二次型来说,随着条件数 c o n d ( A ) 2 cond(A)_2 cond(A)2 的增大,等高线的椭圆族会越来越扁,那么靠近椭圆长轴的迭代初值迭代到最优点会更加困难;或者说,精确线搜的梯度下降法的迭代次数会对迭代初值的选取越来越敏感。由于实际计算中初始值的选取是随机的,我们并不希望算法对初始值的选取过于敏感而导致算法的不稳定性.
其次最速下降法的下降方向选取存在一定的问题:虽然最速下降法选取了函数下降最快的方向,但是这并不一定就是函数值幅度减少最大的方向.简要地说这是因为,最快的下降方向只是对于一个很小的领域而言,但是在这个领域之外的函数值改变的幅度并没有考虑进去 。此外加上精确线搜的要求,使得整个算法变得很不灵活,因为程序会每步都找到 的最小值,但是由于每次迭代的函数值下降的幅度并不是最大的,这样就造成了一种计算资源的浪费.
关于下降最快不代表下降幅度最大可以如下证明:
设目标函数
f
f
f 连续可微,将
f
f
f 在
x
k
x_k
xk 处Taylor展开:
f
(
x
)
=
f
(
x
k
)
+
∇
f
(
x
k
)
T
(
x
−
x
k
)
+
o
(
∣
∣
x
−
x
k
∣
∣
)
f(x)=f(x_k)+\nabla f(x_k)^T(x-x_k)+o(||x-x_k||)
f(x)=f(xk)+∇f(xk)T(x−xk)+o(∣∣x−xk∣∣)令
x
=
x
k
+
1
x=x_{k+1}
x=xk+1 ,结合
x
k
+
1
=
x
k
+
α
k
d
k
x_{k+1}=x_k+\alpha_kd_k
xk+1=xk+αkdk 迭代法可得:
f
(
x
k
+
1
)
=
f
(
x
k
)
+
α
t
∇
f
(
x
k
)
T
d
t
+
o
(
∣
∣
x
k
+
1
−
x
k
∣
∣
)
f(x_{k+1})=f(x_k)+\alpha_t\nabla f(x_k)^Td_t+o(||x_{k+1}-x_k||)
f(xk+1)=f(xk)+αt∇f(xk)Tdt+o(∣∣xk+1−xk∣∣)如果迭代的序列点
{
x
k
}
\{x_{k}\}
{xk} 是收敛的,那么很显然有
x
k
+
1
−
x
k
→
0
(
t
→
∞
)
x_{k+1}-x_k\to0(t\to\infty)
xk+1−xk→0(t→∞) 。因此,我们有:
f
(
x
k
+
1
)
=
f
(
x
k
)
+
α
k
∇
f
(
x
k
)
T
d
k
f(x_{k+1})=f(x_k)+\alpha_k\nabla f(x_k)^Td_k
f(xk+1)=f(xk)+αk∇f(xk)Tdk 。
要是每次迭代都是有意义的,则要求
f
(
x
k
+
1
)
<
f
(
x
k
)
f(x_{k+1})<f(x_k)
f(xk+1)<f(xk) ,需要确保
f
(
x
k
+
1
)
f(x_{k+1})
f(xk+1) 随着
α
k
\alpha_k
αk 的增大而减小(
x
k
x_k
xk
的小领域内),即
∂
f
∂
α
=
∇
f
(
x
k
)
T
d
k
<
0
\frac{\partial f}{\partial\alpha}=\nabla f(x_k)^Td_k<0
∂α∂f=∇f(xk)Tdk<0 ,同时我们希望
f
(
x
k
+
1
)
f(x_{k+1})
f(xk+1) 下降得尽可能快,也就是满足:
d
t
∗
=
arg
min
d
t
∂
f
∂
α
=
arg
max
d
t
−
∂
f
∂
α
d_t^*=\arg\min_{d_t}\frac{\partial f}{\partial\alpha}=\arg\max_{d_t}-\frac{\partial f}{\partial\alpha}
dt∗=argdtmin∂α∂f=argdtmax−∂α∂f由Cauchy不等式:
−
∂
f
∂
α
=
−
∇
f
(
x
k
)
T
d
k
≤
∣
∣
∇
f
(
x
k
)
∣
∣
⋅
∣
∣
d
k
∣
∣
-\frac{\partial f}{\partial\alpha}=-\nabla f(x_k)^Td_k\leq||\nabla f(x_k)||\cdot||d_k||
−∂α∂f=−∇f(xk)Tdk≤∣∣∇f(xk)∣∣⋅∣∣dk∣∣根据Cauchy不等式成立的条件,当且仅当
d
k
d_k
dk 与
−
∇
f
(
x
k
)
-\nabla f(x_k)
−∇f(xk) 同向时,上述不等式中的等号成立.也就是说下降最快的方向
d
k
∗
d_k^*
dk∗与
−
∇
f
(
x
k
)
-\nabla f(x_k)
−∇f(xk) 同向。
Reference
本笔记内容的程序实现不分参考如下了文章:
最优化方法复习笔记(一)梯度下降法、精确线搜索与非精确线搜索(推导+程序)