在上一篇文章中,我们探索了顺序表这一基础的数据结构,它提供了一种有序存储数据的方法,使得数据的访 问和操作变得更加高效。想要进一步了解,大家可以移步于上一篇文章:探索顺序表:数据结构中的秩序之美
今天,我们将进一步深入,探讨另一个重要的数据结构——链表
链表和顺序表一样,都属于线性表,也用于存储数据,但其内部结构和操作方式有着明显的不同。通过C语言的具体实现,我们将会更加直观地理解它
源码可以打我的gitee里面查找:唔姆/比特学习过程2 (gitee.com)
文章目录
- @[toc]
- 一.链表的概念及结构
- 二.链表的分类
- 三.无头单向非循环链表的实现
- 1.项目文件规划
- 2.基本结构及功能一览
- 3.各功能接口具体实现
- 3.1打印单链表
- 3.2尾插
- 3.3头插
- 3.4尾删
- 3.5头删
- 3.6查找
- 3.7插入pos前一个
- 3.8删除pos前一个
- 3.9插入pos后一个
- 3.10删除pos后一个
- 3.11销毁(避免内存泄露)
文章目录
- @[toc]
- 一.链表的概念及结构
- 二.链表的分类
- 三.无头单向非循环链表的实现
- 1.项目文件规划
- 2.基本结构及功能一览
- 3.各功能接口具体实现
- 3.1打印单链表
- 3.2尾插
- 3.3头插
- 3.4尾删
- 3.5头删
- 3.6查找
- 3.7插入pos前一个
- 3.8删除pos前一个
- 3.9插入pos后一个
- 3.10删除pos后一个
- 3.11销毁(避免内存泄露)
一.链表的概念及结构

链表是一种物理存储(实际上)结构上==非连续、非顺序==(杂乱随意排序)的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的
实际情况中:
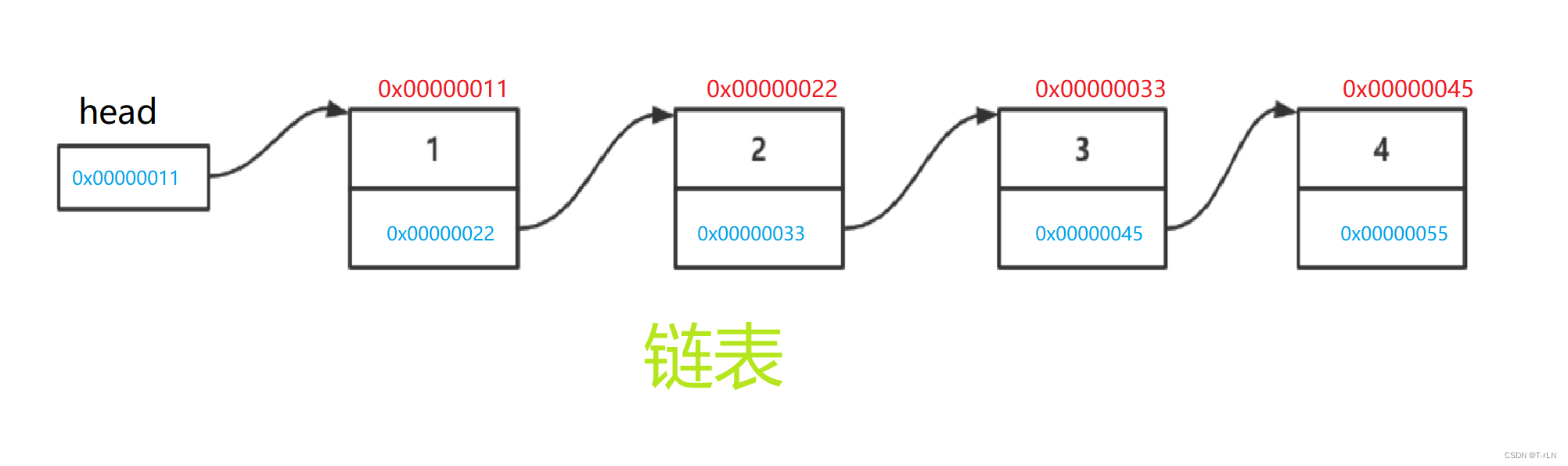
从上图可发现:
- 链表在逻辑上连续,在物理上是不连续的
- 各个节点(Node)一般都是从堆上面申请空间的
- 从堆上面申请的空间是有一定策略的,可能连续,可也能不连续
二.链表的分类
- 单向或者双向
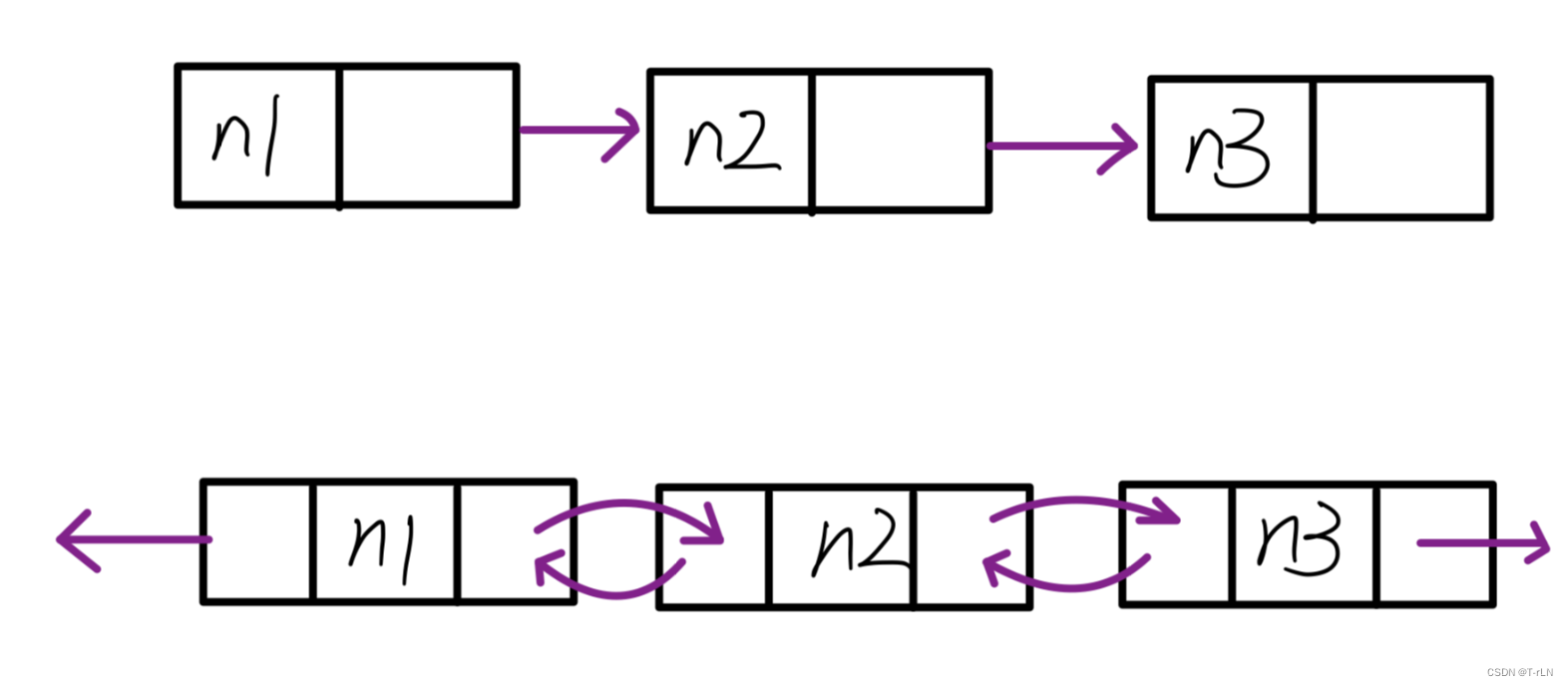
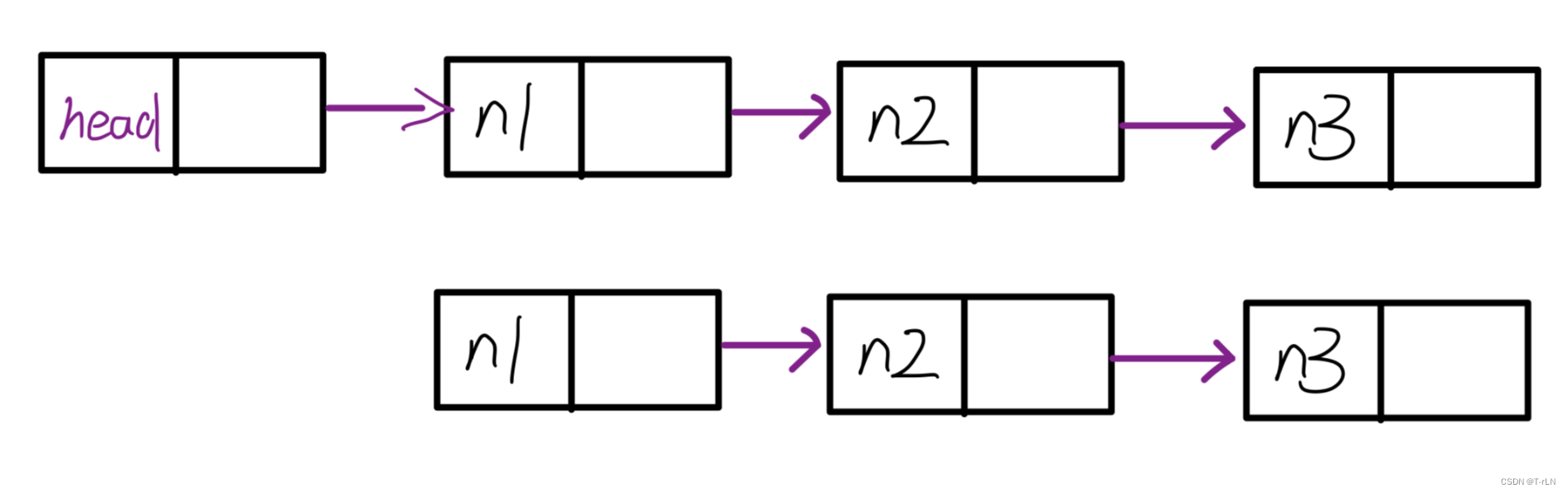
- 带头或者不带头
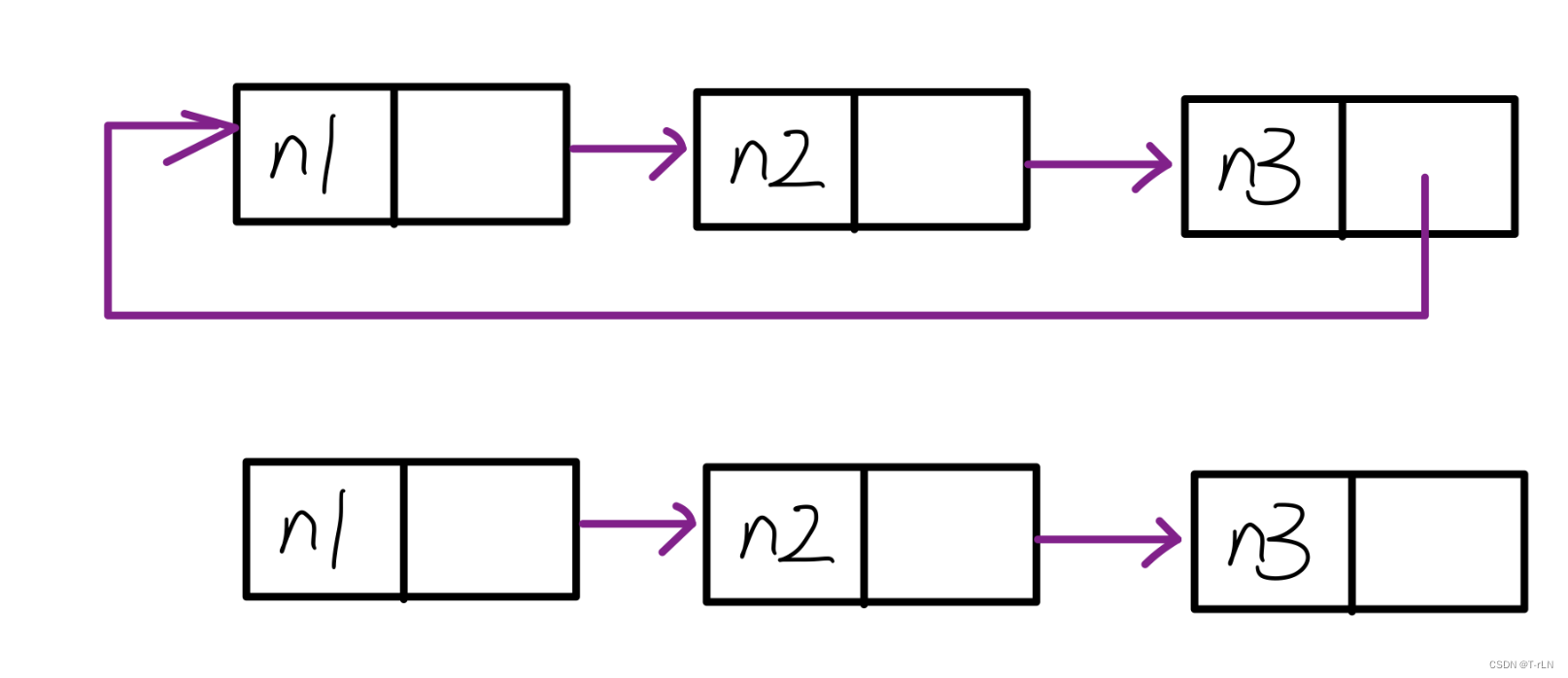
- 循环或者非循环
三种情况随意组合起来就有8种链表结构
其中,最为常用的是:
无头单向非循环和带头双向循环
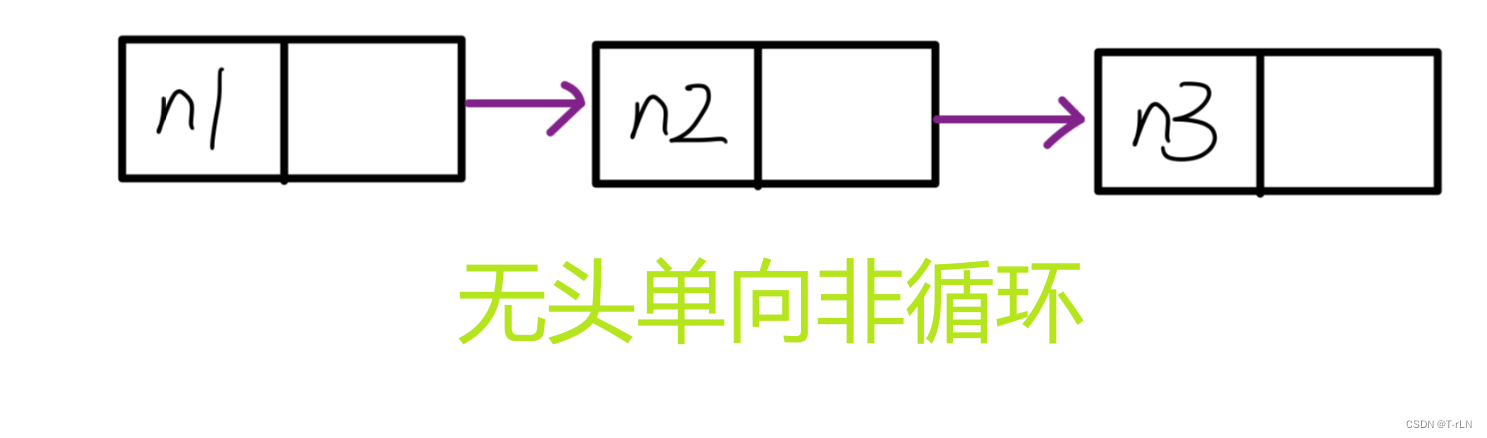
无头单向非循环链表:结构简单,但是一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等
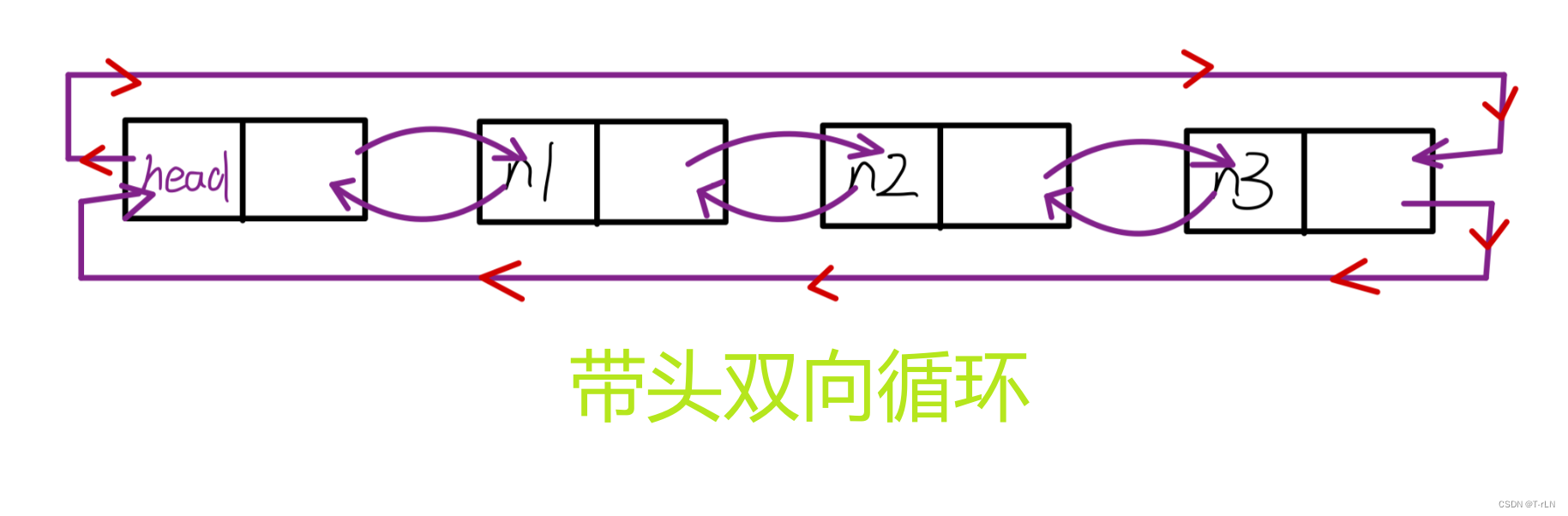
带头双向循环链表:结构最复杂,一般用在单独存储数。实际中使用的链表数据结构,都是带头双向循环链表。这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现它反而简单了
这两种结果都会给大家实现的,今天先来无头单向非循环链表
三.无头单向非循环链表的实现
1.项目文件规划
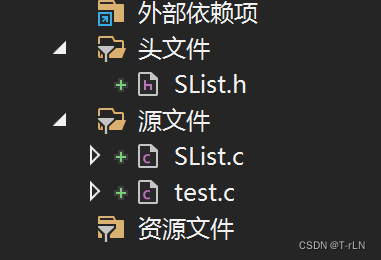
- 头文件SList.h:用来基础准备(常量定义,typedef),链表表的基本框架,函数的声明
- 源文件SList.h:用来各种功能函数的具体实现
- 源文件test.c:用来测试功能是否有问题,进行基本功能的使用
2.基本结构及功能一览
#pragma once
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
typedef int SLDataType;
typedef struct SingleListNode
{
int data;
SingleListNode* next;
}SLNode;
void SLPrint(SLNode* phead);// 单链表打印
void SLPushBack(SLNode** pphead, int n);// 单链表尾插
void SLPushFront(SLNode** pphead, int n);// 单链表头插
void SLPopBack(SLNode** pphead);// 单链表尾删
void SLPopFront(SLNode** pphead);// 单链表尾删
SLNode* SLFind(SLNode* phead, int n);
SLNode* SLInsert(SLNode** pphead, SLNode* pos, int n);//在pos前面插入
SLNode* SLErase(SLNode** pphead, SLNode* pos);//删除pos前面那个
void SLInsertAfter(SLNode* pos, int n);//在pos后面插入
void SLEraseAfter(SLNode* pos);//在pos后面删除
void SLDestory(SLNode** pphead);
3.各功能接口具体实现
3.1打印单链表
void SLPrint(SLNode* phead)
{
assert(phead);
SLNode* cur = phead;
while (cur != NULL)//与while(cur)同样的效果
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}
3.2尾插
SLNode* CreateNode(int n)
{
SLNode* newNode= (SLNode*)malloc(sizeof(SLNode));
if (newNode == NULL)
{
perror("malloc error");
return -1;
}
newNode->data = n;
newNode->next = NULL;
return newNode;
}
void SLPushBack(SLNode** pphead, int n)
{
assert(pphead);
SLNode* newNode = CreateNode(n);//先把节点搞好
//先考虑一下没有节点的情况
if (*pphead == NULL)
{
*pphead = newNode; //这就是传二级指针的原因:
//我们要改变 SLNode* phead本身的指向,就把他地址传过来
//当我们只是要改变指向的结构体里的内容时只要传SLNode* phead就行了
}
else
{
SLNode* tail = *pphead;
while (tail->next != NULL)//找到最后一个节点
{
tail = tail->next;
}
tail->next = newNode;
}
}
- 通过
CreateNode函数创建了一个含有数值n的新节点newNode- 然后根据链表是否为空进行不同的操作:
- 如果链表为空(即头指针指向空),则将新节点
newNode赋值给头指针*pphead- 如果链表不为空,则需要找到链表末尾的节点,通过遍历找到最后一个节点(tail),并将其
next指针指向新节点newNode,以将新节点插入到链表的末尾
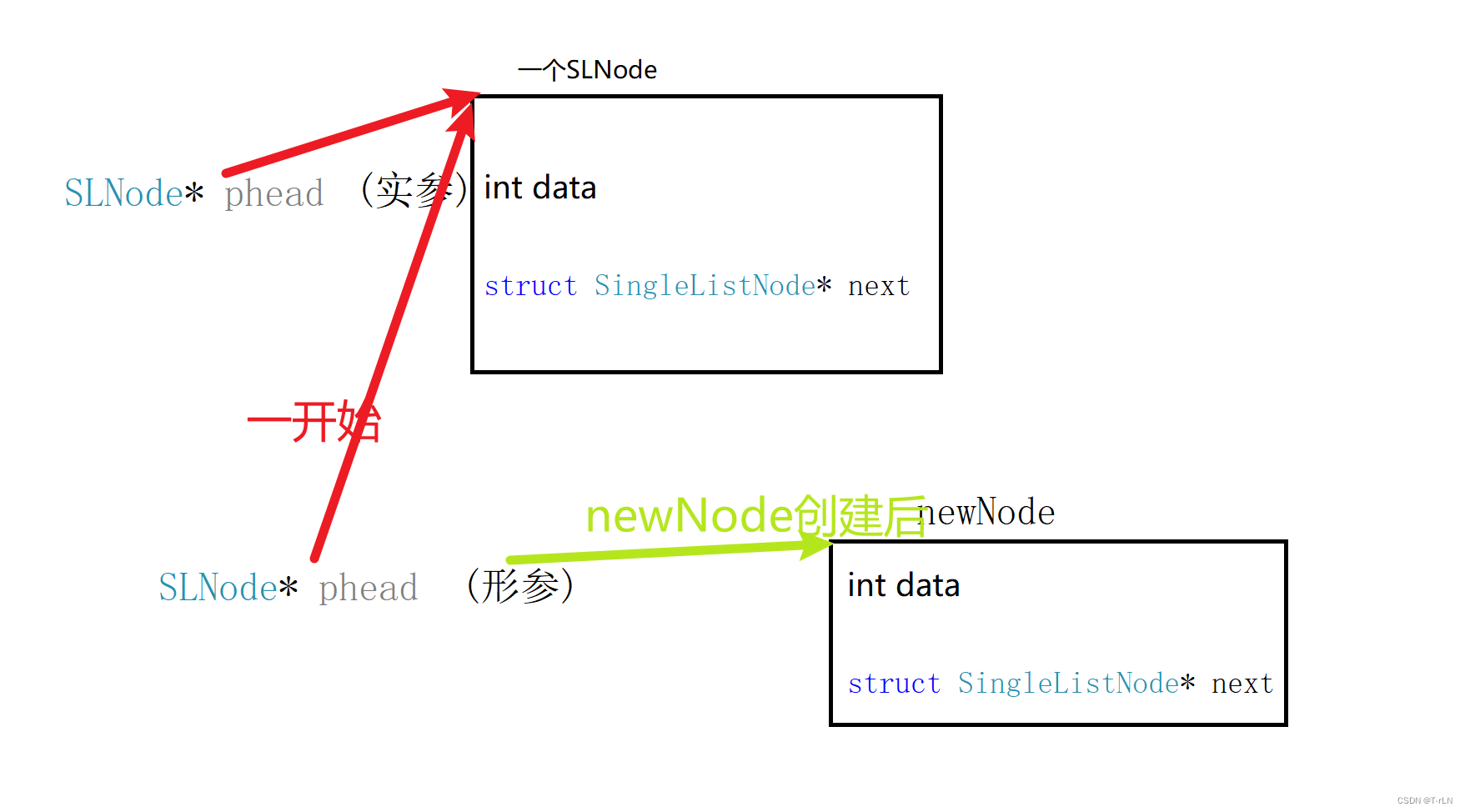
为什么传入二级指针:
这种设计方式的原因在于需要修改指针本身的值,而不是只修改指针所指向的内容
考虑到单链表在插入节点时,可能会涉及链表头指针的修改,如果直接传递单级指针(指向头指针),在函数内部对头指针进行修改是不会反映到函数外部的==(形参是实参的临时拷贝)==。但如果使用二级指针,可以在函数内部修改指针的指向,这样修改后的指向会在函数外部保持
3.3头插
void SLPushFront(SLNode** pphead, int n)
{
assert(pphead);
SLNode* newNode = CreateNode(n);//先把节点搞好
if (*pphead == NULL)
{
*pphead = newNode;
}
else
{
newNode->next = (*pphead)->next;
(*pphead)->next = newNode;
}
//或者
//newNode->next = (*pphead);
//*pphead = newNode;
}
- 通过
CreateNode函数创建了一个含有数值n的新节点newNode- 接着,根据链表是否为空进行不同的操作:
- 如果链表为空(即头指针指向空),则将新节点
newNode赋值给头指针*pphead- 如果链表不为空,则将新节点
newNode的next指针指向当前头节点的下一个节点(原链表的第二个节点),然后将当前头节点的next指针指向新节点newNode,以完成插入
注释部分显示了另一种写法,通过先设置新节点的 next 指针指向当前头节点,然后再将链表的头指针指向新节点,实现了同样的插入操作
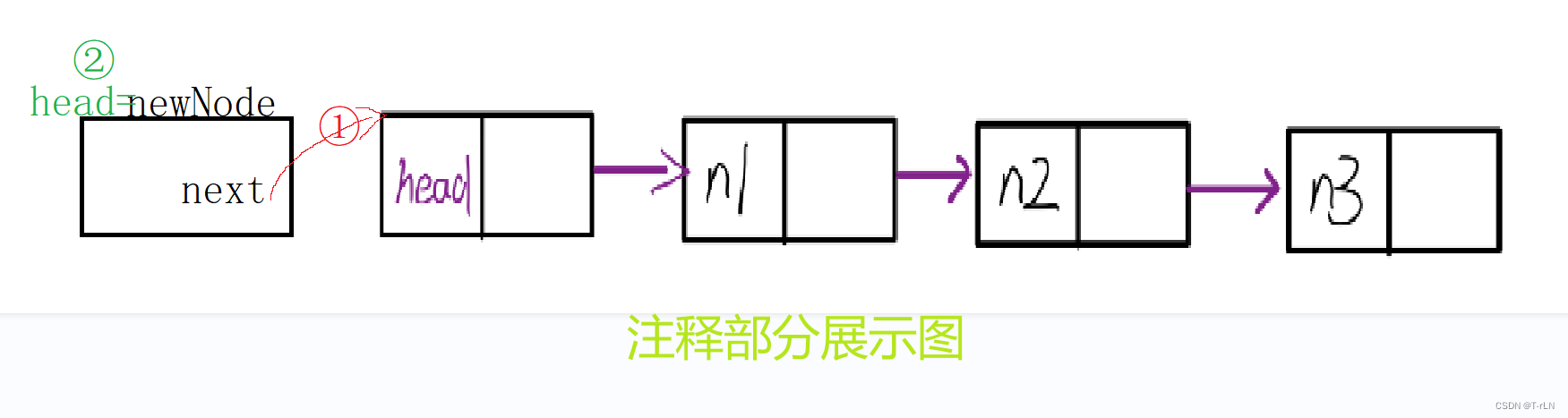
3.4尾删
void SLPopBack(SLNode** pphead)
{
assert(pphead);
assert(*pphead);//防止一个都没有还删
if ((*pphead)->next == NULL)//只有一个
{
free(*pphead);
*pphead = NULL;
}
else
{
//找到倒数第二个
SLNode* pre_tail = *pphead;
while (pre_tail->next->next != NULL)
{
pre_tail = pre_tail->next;
}
free(pre_tail->next);
pre_tail->next = NULL;
}
}
- 检查链表头指针
*pphead是否存在(不为 NULL),以及链表是否为空(只有一个节点)-
- 如果链表中只有一个节点,则直接释放该节点,并将链表头指针设置为 NULL,表示链表为空
- 如果链表中有多个节点,则会找到倒数第二个节点,即指向最后一个节点的前一个节点。它通过遍历链表直到找到倒数第二个节点
pre_tail,然后释放最后一个节点,并将倒数第二个节点的next指针设置为 NULL,表示该节点成为新的末尾节点
3.5头删
void SLPopFront(SLNode** pphead)
{
assert(pphead);
assert(*pphead);//防止一个都没有还删
SLNode* first = (*pphead)->next;//一个和多个都适用
free(*pphead);
*pphead = first;
}
- 创建了一个临时指针
first来指向原链表的第二个节点(如果存在)。这是因为要删除的是链表的头节点,为了不断开链表,需要先保存第二个节点的地址- 通过
free(*pphead)释放掉原来的头节点,然后将链表的头指针*pphead更新为原头节点的下一个节点first
3.6查找
SLNode* SLFind(SLNode* phead, int n)
{
assert(phead);
SLNode* cur = phead;
while (cur != NULL)//与while(cur)同样的效果
{
if (cur->data == n)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
3.7插入pos前一个
void SLInsert(SLNode** pphead, SLNode* pos, int n)//在pos前面插入
{
assert(pphead);
assert(pos);
SLNode* cur = *pphead;
if (*pphead == pos)//在第一个节点前面插入
{
// 头插
SLTPushFront(pphead, n);
}
else
{
while (cur->next != pos)
{
cur = cur->next;
}
SLNode* newNode = CreateNode(n);
newNode->next = cur->next;
cur->next = newNode;
}
}
- 如果要插入的位置
pos就是链表的头节点*pphead,即在第一个节点前面插入,则调用SLTPushFront函数,直接在链表头部插入新节点newNode- 如果要插入的位置不是头节点,则通过循环遍历链表,直到找到
pos的前一个节点cur,然后创建新节点newNode并将其插入到pos前面,完成节点的插入操作
3.8删除pos前一个
void SLErase(SLNode** pphead, SLNode* pos)
{
assert(pphead);
assert(pos);
assert(*pphead != pos);//防止前面没有
SLNode* cur = *pphead;
SLNode* pre_cur = *pphead;
while (cur->next != pos)
{
pre_cur = cur;
cur = cur->next;
}
pre_cur->next = pos;
free(cur);
cur = NULL;
}
3.9插入pos后一个
void SLInsertAfter(SLNode* pos, int n)
{
assert(pos);
SLNode* newNode =CreateNode(n);
newNode->next = pos->next;
pos->next = newNode;
}
- 创建一个新节点
newNode,并将新节点的next指针指向pos节点原本的下一个节点,以保证链表的连续性- 将
pos节点的next指针指向新节点newNode,完成了在指定节点之后插入新节点的操作
3.10删除pos后一个
void SLEraseAfter(SLNode* pos)
{
assert(pos);
SLNode* next = pos->next->next;
free(pos->next);
pos->next = NULL;
pos->next = next;
}
3.11销毁(避免内存泄露)
void SLDestory(SLNode** pphead)
{
assert(pphead);
SLNode* cur = *pphead;
SLNode* next = *pphead;
while (cur!=NULL)
{
next = cur->next;
free(cur);
cur = next;
}
*pphead = NULL;
}
循环删除每一个
Node,最后把原本的结构体指针指向NULL
好啦,这次知识就先到这里啦!下一次大概率是双向带头循环的代码实现了。