内容导航
| 类别 | 内容导航 |
|---|---|
| 机器学习 | 机器学习算法应用场景与评价指标 |
| 机器学习算法—分类 | |
| 机器学习算法—回归 | |
| 机器学习算法—聚类 | |
| 机器学习算法—异常检测 | |
| 机器学习算法—时间序列 | |
| 数据可视化 | 数据可视化—折线图 |
| 数据可视化—箱线图 | |
| 数据可视化—柱状图 | |
| 数据可视化—饼图、环形图、雷达图 | |
| 统计学检验 | 箱线图筛选异常值 |
| 3 Sigma原则筛选离群值 | |
| Python统计学检验 | |
| 大数据 | PySpark大数据处理详细教程 |
| 使用教程 | CentOS服务器搭建Miniconda环境 |
| Linux服务器配置免密SSH | |
| 大数据集群缓存清理 | |
| 面试题整理 | 面试题—机器学习算法 |
| 面试题—推荐系统 |
"""
传入一个list,以及几倍的sigma参数threshold,可以将数据中的正常值及离群值用不同颜色展示出来
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
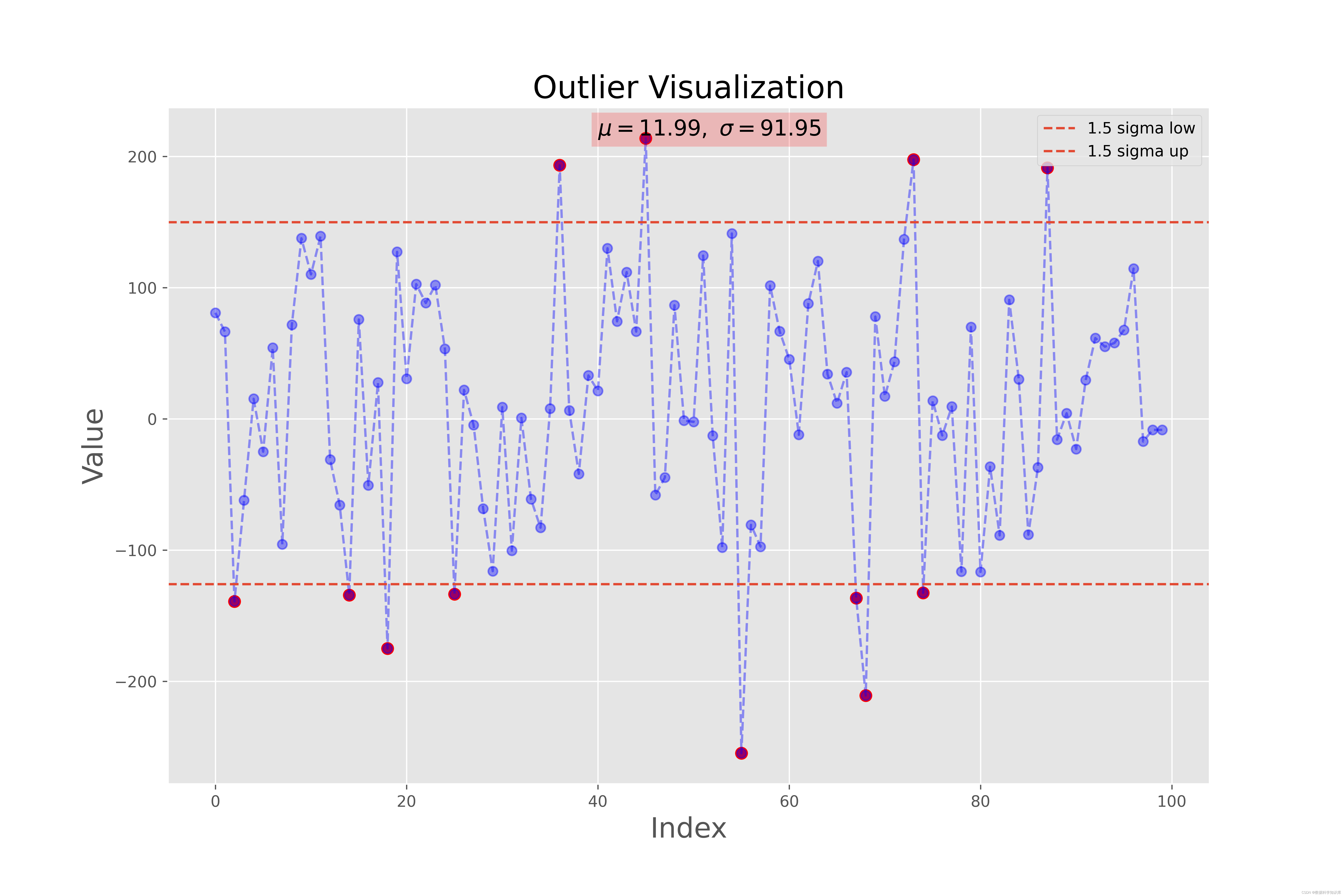
def Outlier_visualization_line(data,threshold):
plt.style.use('ggplot')
data = pd.Series(data)
mean = data.mean()
std = data.std()
#筛选出离群值
left = mean - threshold * std
right = mean + threshold * std
error = data[(data<left)|(data>right)]
data_c = data[(data>=left)&(data<=right)]
# #不同着色,正常绿色,离群值红色
# sp = np.where(data.isin(data_c),'g','r')
# 可视化
fig = plt.figure(figsize=(12,8))
plt.plot(data.index,data.values,'bo--',alpha=0.4)
plt.scatter(error.index,error.values,c='r',s=60)
plt.title('Outlier Visualization',size=20)
plt.text(len(data)*0.4,data.values.max()+data.values.max()*0.01,
r'$\mu={},\ \sigma={}$'.format(round(mean,2),round(std,2)),fontsize=14,bbox=dict(facecolor='red', alpha=0.2))
# 添加水平辅助线plt.axhline,添加垂直辅助线plt.axvline(轴位置,线形,标签))
plt.axhline(left,linestyle = '--',label="{} sigma low".format(threshold))
plt.axhline(right,linestyle = '--',label="{} sigma up".format(threshold))
plt.xlabel('Index',size=18)
plt.ylabel('Value',size=18)
plt.grid(True)
plt.legend(loc='best')
plt.show()
fig.savefig('Outlier_visualization_line.png',dpi=600)
data = np.random.randn(100)*100
Outlier_visualization_line(data,threshold=1.5)
"""
传入一个list,以及几倍的sigma参数threshold,可以将数据中的正常值及离群值用不同颜色展示出来
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
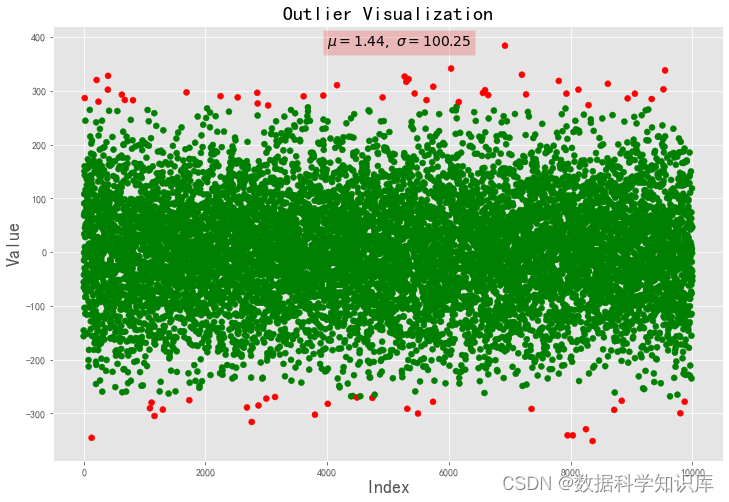
def Outlier_visualization_scatter(data,threshold):
plt.style.use('ggplot')
data = pd.Series(data)
mean = data.mean()
std = data.std()
#筛选出离群值
left = mean - threshold * std
right = mean + threshold * std
error = data[(data<left)|(data>right)]
data_c = data[(data>=left)&(data<=right)]
#不同着色,正常绿色,离群值红色
sp = np.where(data.isin(data_c),'g','r')
# 可视化
fig = plt.figure(figsize=(12,8))
plt.scatter(data.index,data.values,marker='o',c=sp)
plt.title('Outlier Visualization',size=20)
plt.text(len(data)*0.4,data.values.max(),
r'$\mu={},\ \sigma={}$'.format(round(mean,2),round(std,2)),fontsize=14,bbox=dict(facecolor='red', alpha=0.2))
plt.xlabel('Index',size=18)
plt.ylabel('Value',size=18)
plt.grid(True)
plt.show()
fig.savefig('Outlier_visualization_scatter.png',dpi=600)
data = np.random.randn(10000)*100
Outlier_visualization_scatter(data,threshold=2.7)
友情提示:如果你觉得这个博客对你有帮助,请点赞、评论和分享吧!如果你有任何问题或建议,也欢迎在评论区留言哦!!!