实验目的:掌握Scala开发工具消费Kafka数据,并将结果保存到关系型数据库中
实验方法:消费Kafka数据保存到MySQL中
实验步骤:
一、创建Job_ClickData_Process
代码如下:
package exams
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies, OffsetRange}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import java.sql.{Connection, DriverManager, PreparedStatement}
import scala.collection.mutable
/**
* @projectName sparkGNU2023
* @package exams
* @className exams.Job_ClickData_Process
* @description ${description}
* @author pblh123
* @date 2023/12/20 15:42
* @version 1.0
*
*/
object Job_ClickData_Process {
def main(args: Array[String]): Unit = {
// 1. 创建spark,sc,sparkstreaming对象
if (args.length != 3) {
println("您需要输入三个参数")
System.exit(5)
}
val musrl: String = args(0)
val conf = new SparkConf().setAppName(s"${this.getClass.getSimpleName}").setMaster(musrl)
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
val ckeckpointdir: String = args(1)
val ssc = new StreamingContext(sc, Seconds(5)) //连续流批次处理的大小
// 2. 代码主体
// 设置ckeckpoint目录
ssc.checkpoint(ckeckpointdir)
//准备kafka的连接参数
val kfkbst: String = args(2)
val kafkaParams: Map[String, Object] = Map[String, Object](
"bootstrap.servers" -> kfkbst,
"group.id" -> "SparkKafka",
//latest表示如果记录了偏移量的位置,就从记录的位置开始消费,如果没有记录,就从最新/或最后的位置开始消费
//earliest表示如果记录了偏移量的位置,就从记录的位置开始消费,如果没有记录,就从最开始/最早的位置开始消费
//none示如果记录了偏移量的位置,就从记录的位置开始消费,如果没有记录,则报错
"auto.offset.reset" -> "latest", //偏移量的重置位置
"enable.auto.commit" -> (false: java.lang.Boolean), //是否自动提交偏移量
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer]
)
val topics: Array[String] = Array("RealDataTopic")
//从mysql中查询出offsets:Map[TopicPartition, Long]
val offsetsMap: mutable.Map[TopicPartition, Long] = OffsetUtils.getOffsetMap("SparkKafka", "RealDataTopic")
val kafkaDS: InputDStream[ConsumerRecord[String, String]] = if (offsetsMap.size > 0) {
println("MySql记录了offset信息,从offset处开始消费")
//连接kafka的消息
KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams, offsetsMap)
)
} else {
println("MySql没有记录了offset信息,从latest处开始消费")
//连接kafka的消息
KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)
)
}
//实时处理数据并手动维护offset
val valueDS = kafkaDS.map(_.value()) //_表示从kafka中消费出来的每一条数据
valueDS.print()
kafkaDS.map(_.value())
valueDS.foreachRDD(rdd => {
rdd.foreachPartition(lines => {
//将处理分析的结果存入mysql
/*
DROP TABLE IF EXISTS `job_real_time`;
CREATE TABLE `job_real_time` (
`datetime` varchar(8) DEFAULT NULL COMMENT '日期',
`job_type` int(2) DEFAULT NULL COMMENT '1代表新招聘岗位,0代表找工作的人',
`job_id` int(8) DEFAULT NULL COMMENT '岗位ID,匹配岗位名称',
`count` int(8) DEFAULT NULL COMMENT '企业新增岗位数和找工作的人数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
*/
//1.开启连接
val conn: Connection = DriverManager.getConnection("jdbc:mysql://192.168.137.110:3306/bigdata19?characterEncoding=UTF-8&serverTimezone=UTC", "lh", "Lh123456!")
//2.编写sql并获取ps
val sql: String = "replace into job_real_time(datetime,job_type,job_id,count) values(?,?,?,?)"
val ps: PreparedStatement = conn.prepareStatement(sql)
//3.设置参数并执行
for (line <- lines) {
var item = line.split(" ")
ps.setString(1, item(0).toString)
ps.setInt(2, item(1).toInt)
ps.setInt(3, item(2).toInt)
ps.setInt(4, item(3).toInt)
ps.executeUpdate()
}
//4.关闭资源
ps.close()
conn.close()
})
})
//手动提交偏移量
kafkaDS.foreachRDD(rdd => {
if (rdd.count() > 0) {
//获取偏移量
val offsets: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
OffsetUtils.saveOffsets(groupId = "SparkKafka", offsets)
}
})
//开启sparkstreaming任务并等待结束,关闭ssc,sc
ssc.start()
ssc.awaitTermination()
ssc.stop()
sc.stop()
}
}

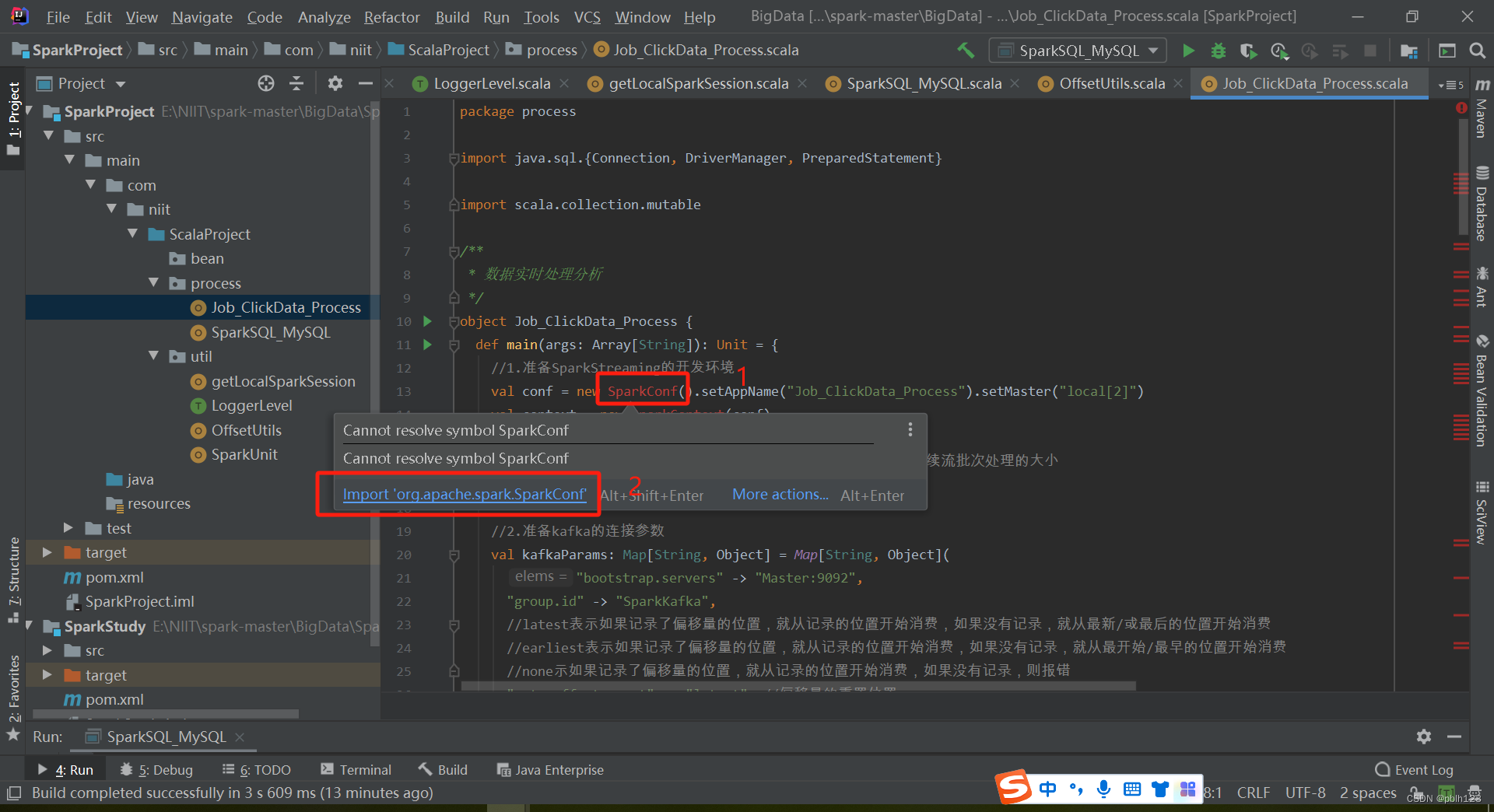


二、编写模拟点击量并消费Kafka数据
启动zookeeper集群
zk.sh start
启动kafka集群
kf.sh start
检查模拟的实时数据是否正常更新

不断正常更新的情况下,启动flume采集real-time-data.log的实时数据
启动flume

在mysql数据库中准备偏移表与实时数据表



启动Job_ClickData_Process方法消费kafka数据并保存到mysql中


检查mysql表是否存入数据

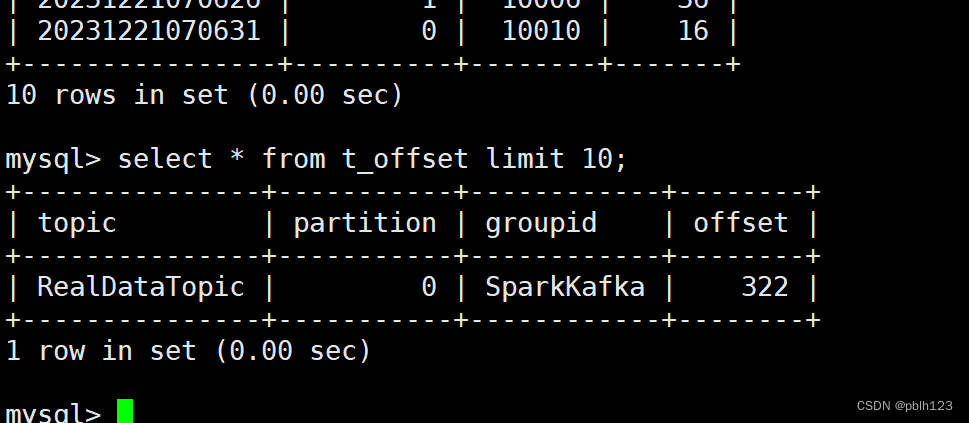
实验结果:通过scala开发spark代码实现消费kafka数据存储到MySQL中