简介
这篇博客,主要给大家讲解我们在训练yolov5时生成的结果文件中各个图片及其中指标的含义,帮助大家更深入的理解,以及我们在评估模型时和发表论文时主要关注的参数有那些。本文通过举例训练过程中的某一时间的结果来帮助大家理解,大家阅读过程中如有任何问题可以在评论区提问出来,我会帮助大家解答。首先我们来看一个在一次训练完成之后都能生成多少个文件如下图所示,下面的文章讲解都会围绕这个结果文件来介绍。

评估用的数据集
上面的训练结果,是根据一个检测飞机的数据集训练得来,其中只有个标签就是飞机,对于这种单标签的数据集,其实我们可以将其理解为一个二分类任务,
一种情况->检测为飞机,另一种情况->不是飞机。
结果分析
我们可以从结果文件中看到其中共有文件22个,后9张图片是根据我们训练过程中的一些检测结果图片,用于我们可以观察检测结果,有哪些被检测出来了,那些没有被检测出来,其不作为指标评估的文件。
Weights文件夹
我们先从第一个weights文件夹来分析,其中有两个文件,分别是best.pt、last.pt,其分别为训练过程中的损失最低的结果和模型训练的最后一次结果保存的模型。

然后我来说两个比较不重要的yaml文件,其保存了我们训练过程中的一些参数如下->
hyp.yaml
第二个文件是args.yaml文件,其中主要保存一些我们训练时指定的参数,内容如下所示。
lr0: 0.01
lrf: 0.01
momentum: 0.937
weight_decay: 0.0005
warmup_epochs: 3.0
warmup_momentum: 0.8
warmup_bias_lr: 0.1
box: 0.05
cls: 0.5
cls_pw: 1.0
obj: 1.0
obj_pw: 1.0
iou_t: 0.2
anchor_t: 4.0
fl_gamma: 0.0
hsv_h: 0.015
hsv_s: 0.7
hsv_v: 0.4
degrees: 0.0
translate: 0.1
scale: 0.5
shear: 0.0
perspective: 0.0
flipud: 0.0
fliplr: 0.5
mosaic: 1.0
mixup: 0.0
copy_paste: 0.0
opt.yaml
这个文件里面包含了我们所有的参数,上面的yaml文件只包含了训练过程中的超参数,但是还有一些其他的参数类似于数据集的地址,权重地址,项目名称等一系列设置性参数,内容如下->
weights: yolov5n.pt
cfg: models/yolov5n.yaml
data: Construction Site Safety.v30-raw-images_latestversion.yolov8\data.yaml
hyp:
lr0: 0.01
lrf: 0.01
momentum: 0.937
weight_decay: 0.0005
warmup_epochs: 3.0
warmup_momentum: 0.8
warmup_bias_lr: 0.1
box: 0.05
cls: 0.5
cls_pw: 1.0
obj: 1.0
obj_pw: 1.0
iou_t: 0.2
anchor_t: 4.0
fl_gamma: 0.0
hsv_h: 0.015
hsv_s: 0.7
hsv_v: 0.4
degrees: 0.0
translate: 0.1
scale: 0.5
shear: 0.0
perspective: 0.0
flipud: 0.0
fliplr: 0.5
mosaic: 1.0
mixup: 0.0
copy_paste: 0.0
epochs: 200
batch_size: 16
imgsz: 640
rect: false
resume: false
nosave: false
noval: false
noautoanchor: false
noplots: false
evolve: null
bucket: ''
cache: null
image_weights: false
device: '0'
multi_scale: false
single_cls: false
optimizer: SGD
sync_bn: false
workers: 0
project: runs\train
name: exp
exist_ok: false
quad: false
cos_lr: false
label_smoothing: 0.0
patience: 100
freeze:
- 0
save_period: -1
seed: 0
local_rank: -1
entity: null
upload_dataset: false
bbox_interval: -1
artifact_alias: latest
save_dir: runs\train\exp45
events.out.tfevents.1702789209.WIN-4OLTEIJCBBM.13772.0文件
这个文件是一个TensorBoard日志文件。虽然TensorBoard起初是为TensorFlow设计的,但它也可以与PyTorch一起使用,因为PyTorch有一个叫 tensorboardX 的库,允许PyTorch生成TensorBoard兼容的事件文件。
这样的文件用于记录训练过程中的各种指标,比如损失、准确率、其他统计数据,可以通过TensorBoard来可视化这些指标,以监控和分析模型的训练进度和性能。
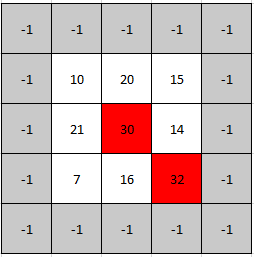
混淆矩阵(ConfusionMatrix)
第三个文件就是混淆矩阵,大家都应该听过这个名字,其是一种用于评估分类模型性能的表格形式。它以实际类别(真实值)和模型预测类别为基础,将样本分类结果进行统计和汇总。
对于二分类问题,混淆矩阵通常是一个2×2的矩阵,包括真阳性(True Positive, TP)、真阴性(True Negative, TN)、假阳性(False Positive, FP)和假阴性(False Negative, FN)四个元素。
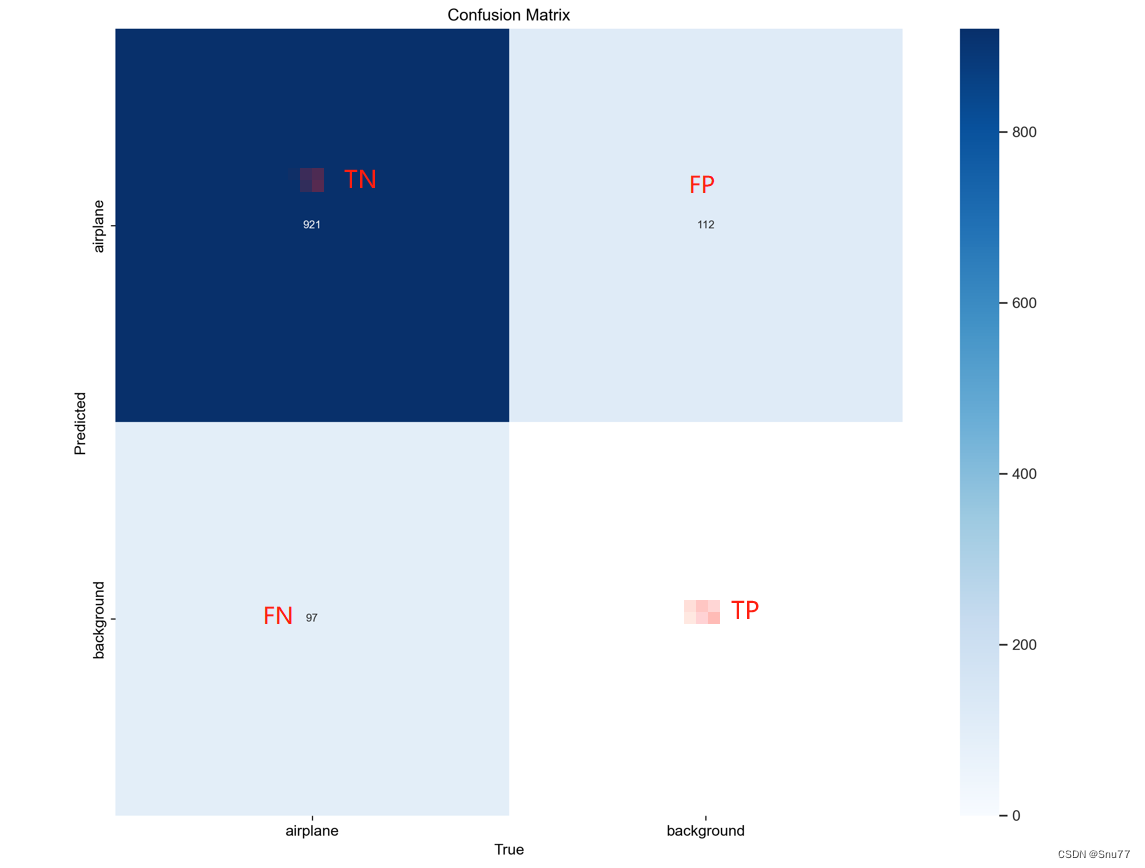
True_Label = [1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1 ,0, 1, 0 , 1 , 0, 0 , 1]
Predict_Label = [0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1 ,0 , 0 , 1 , 0, 0 , 1, 0]我们来分析这个图,其每个格子代表的含义我在图片上标注了出来,下面我们来拿一个例子来帮助大家来理解这个混淆矩阵。
假设我们的数据集预测为飞机标记为数字0、预测不为飞机标记为1,现在假设我们在模型的训练的某一批次种预测了20次其真实结果和预测结果如下所示。
其中True_Label代表真实的标签,Predict_Label代表我们用模型预测的标签。
那么我们可以进行对比产生如下分析
- 6个样本的真实标签和预测标签都是0(真阴性,True Negative)。
- 1个样本的真实标签是0,但预测标签是1(假阳性,False Positive)。
- 8个样本的真实标签是1,但预测标签是0(假阴性,False Negative)。
- 5个样本的真实标签和预测标签都是1(真阳性,True Positive)。
下面根据我们的分析结果,我们就能够画出这个预测的混淆矩阵,

由此我们就能得到那一批次的混淆矩阵,我们的最终结果生成的混淆矩阵可以理解为多个混淆矩阵的统计结果。
计算mAP、Precision、Recall
在讲解其它的图片之前我们需要来计算三个比较重要的参数,这是其它图片的基础,这里的计算还是利用上面的某一批次举例的分析结果。

-
精确度(Precision):预测为正的样本中有多少是正确的,Precision = TP / (TP + FP) = 5 / (5 + 1) = 5/6 ≈ 0.833
-
召回率(Recall):真实为正的样本中有多少被正确预测为正,Recall = TP / (TP + FN) = 5 / (5 + 8) ≈ 0.385
-
F1值(F1-Score):综合考虑精确度和召回率的指标,F1 = 2 * (Precision * Recall) / (Precision + Recall) = 2 * (0.833 * 0.385) / (0.833 + 0.385) ≈ 0.526
-
准确度(Accuracy):所有样本中模型正确预测的比例,Accuracy = (TP + TN) / (TP + TN + FP + FN) = (5 + 6) / (5 + 6 + 1 + 8) ≈ 0.565
-
平均精确度(Average Precision, AP):用于计算不同类别的平均精确度,对于二分类问题,AP等于精确度。AP = Precision = 0.833
-
平均精确度(Mean Average Precision, mAP):多类别问题的平均精确度,对于二分类问题,mAP等于AP(精确度),所以mAP = AP = 0.833
这里需要讲解的主要是AP和MAP如果是多分类的问题,AP和mAP怎么计算,首先我们要知道AP的全称就是Average Precision,平均精度所以我们AP的计算公式如下?

mAP就是Mean Average Precision,计算如下,计算每一个没别的AP进行求平均值处理就是mAP。

F1_Curve
F1_Curve这个文件,我们点击去的图片的标题是F1-Confidence Curve它显示了在不同分类阈值下的F1值变化情况。
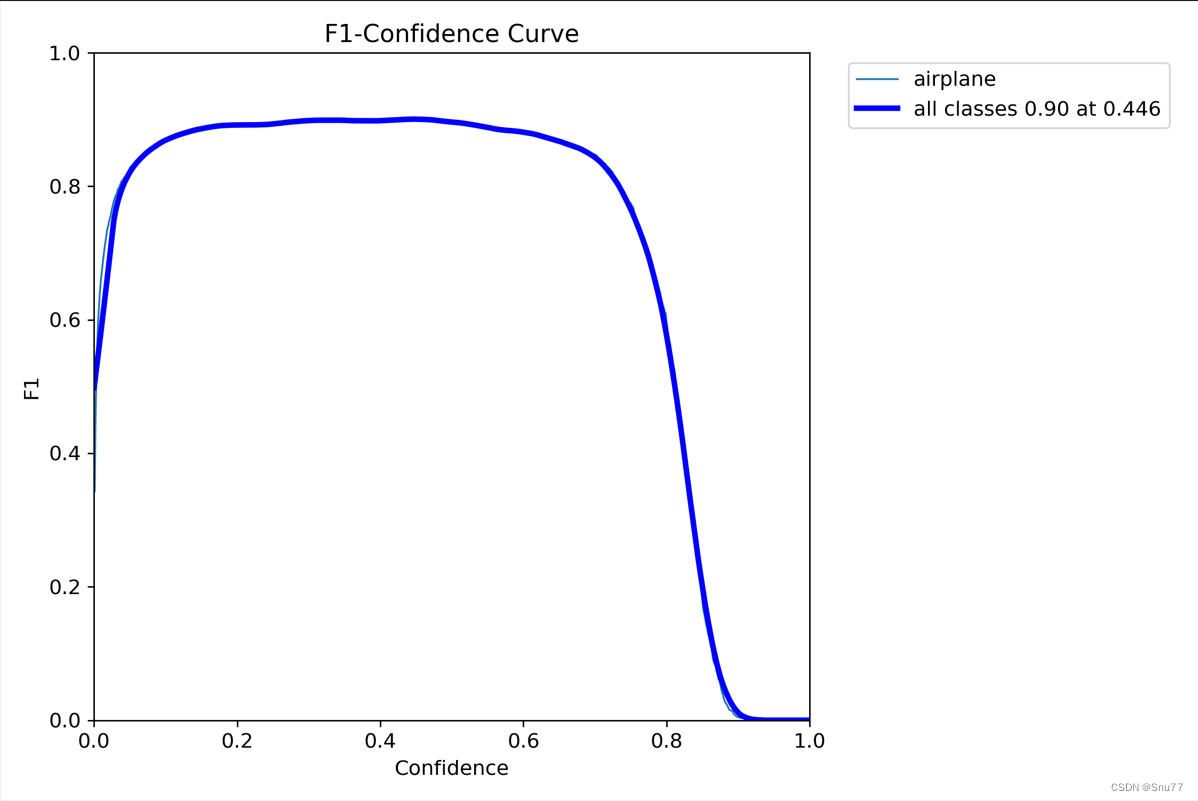
我们可以这么理解,先看它的横纵坐标,横坐标是置信度,纵坐标是F1-Score,F1-Score在前面我们以及讲解过了,那什么是置信度?
置信度(Confidence)->在我们模型的识别过程中会有一个概率,就是模型判定一个物体并不是百分百判定它是属于某一个分类,它会给予它以个概率,Confidence就是我们设置一个阈值,如果超过这个概率那么就确定为某一分类,假如我模型判定一个物体由0.7的概率属于飞机,此时我们设置的阈值如果为0.7以下那么模型就会输出该物体为飞机,如果我们设置的阈值大于0.7那么模型就不会输出该物体为飞机。
F1-Confidence Curve就是随着F1-Score随着Confience的逐渐增高而变化的一个曲线。
Labels
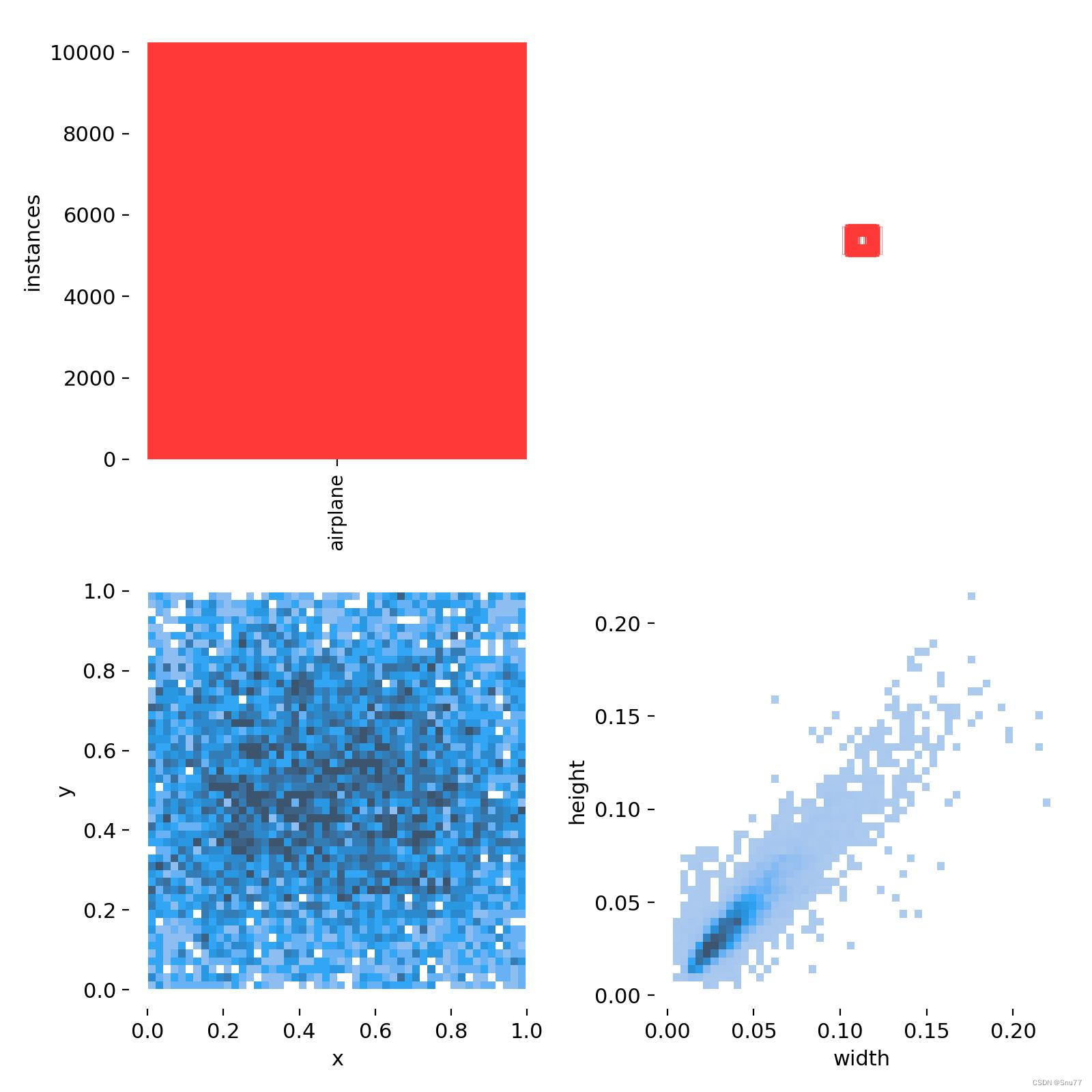
Labels图片代表每个检测到的目标的类别和边界框信息。每个目标都由一个矩形边界框和一个类别标签表示,我们逆时针来看这个图片!!!
- 目标类别:该像素点所检测到的目标类别,例如飞机等。
- 目标位置:该像素点所检测到的目标在图像中的位置,即该像素点在图像中的坐标。
- 目标大小:该像素点所检测到的目标的大小,即该像素点所覆盖的区域的大小。
- 其他信息:例如目标的旋转角度等其他相关信息。
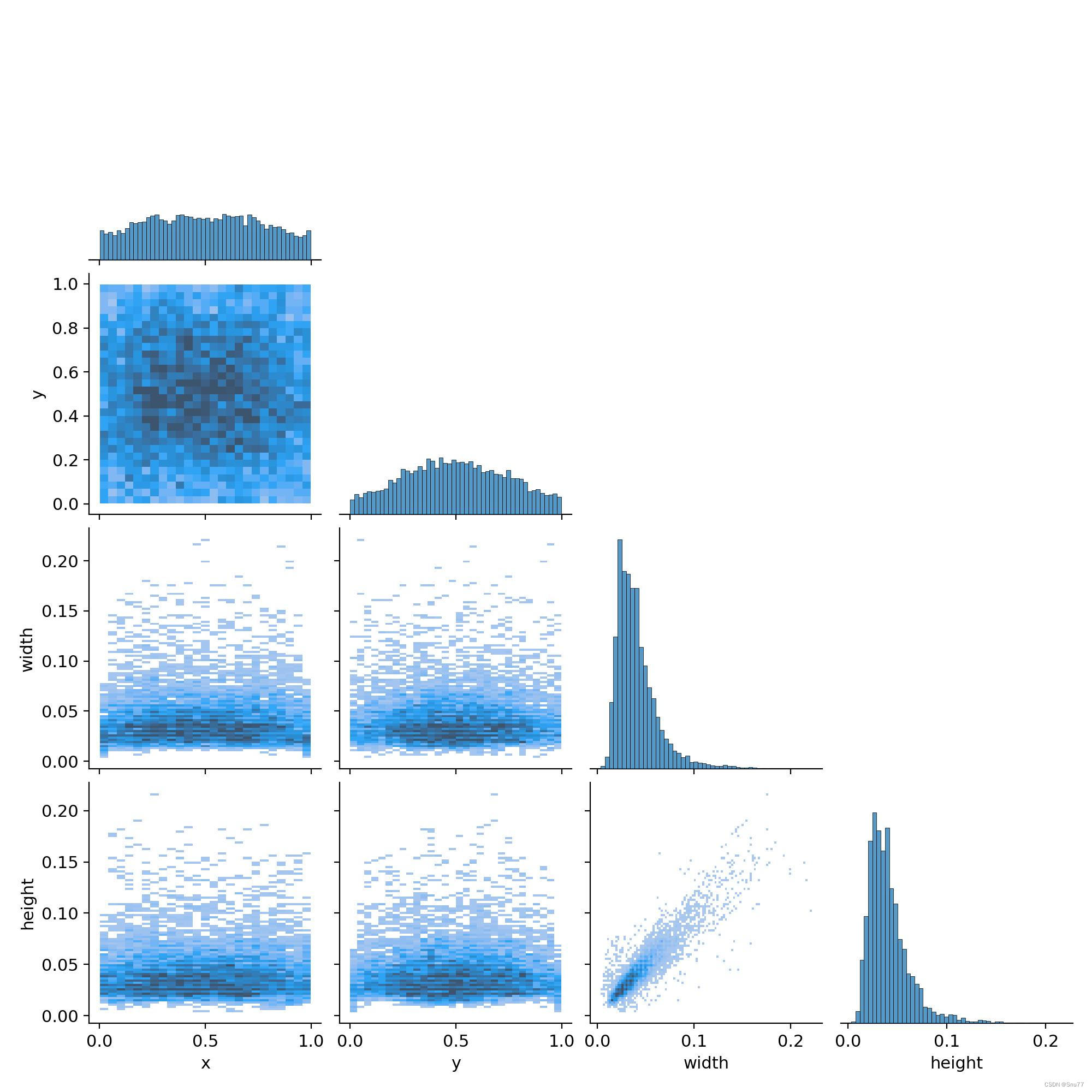
labels_correlogram
labels_correlogram是一个在机器学习领域中使用的术语,它指的是一种图形,用于显示目标检测算法在训练过程中预测标签之间的相关性。
具体来说,labels_correlogram是一张颜色矩阵图,它展示了训练集数据标签之间的相关性。它可以帮助我们理解目标检测算法在训练过程中的行为和表现,以及预测标签之间的相互影响。
通过观察labels_correlogram,我们可以了解到目标检测算法在不同类别之间的区分能力,以及对于不同类别的预测精度。此外,我们还可以通过比较不同算法或不同数据集labels_correlogram,来评估算法的性能和数据集的质量。
总之,labels_correlogram是一种有用的工具,可以帮助我们更好地理解目标检测算法在训练过程中的行为和表现,以及评估算法的性能和数据集的质量。
P_curve
这个图的分析和F1_Curve一样,不同的是关于的是Precision和Confidence之间的关系,可以看出我们随着置信度的越来越高检测的准确率按理来说是越来越高的。

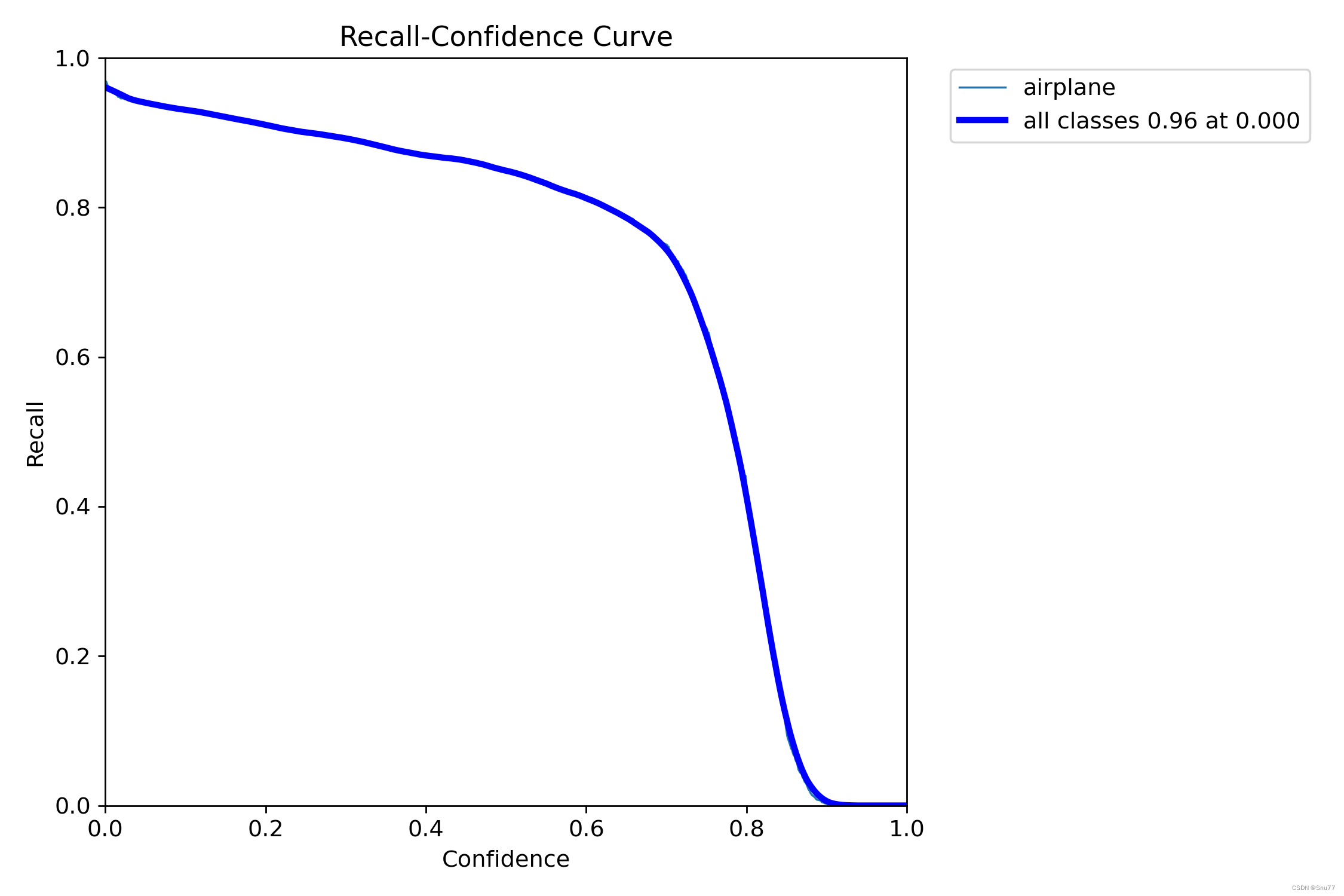
R_curve
这个图的分析和F1_Curve一样,不同的是关于的是Recall和Confidence之间的关系,可以看出我们随着置信度的越来越高召回率的准确率按理来说是越来越低的。
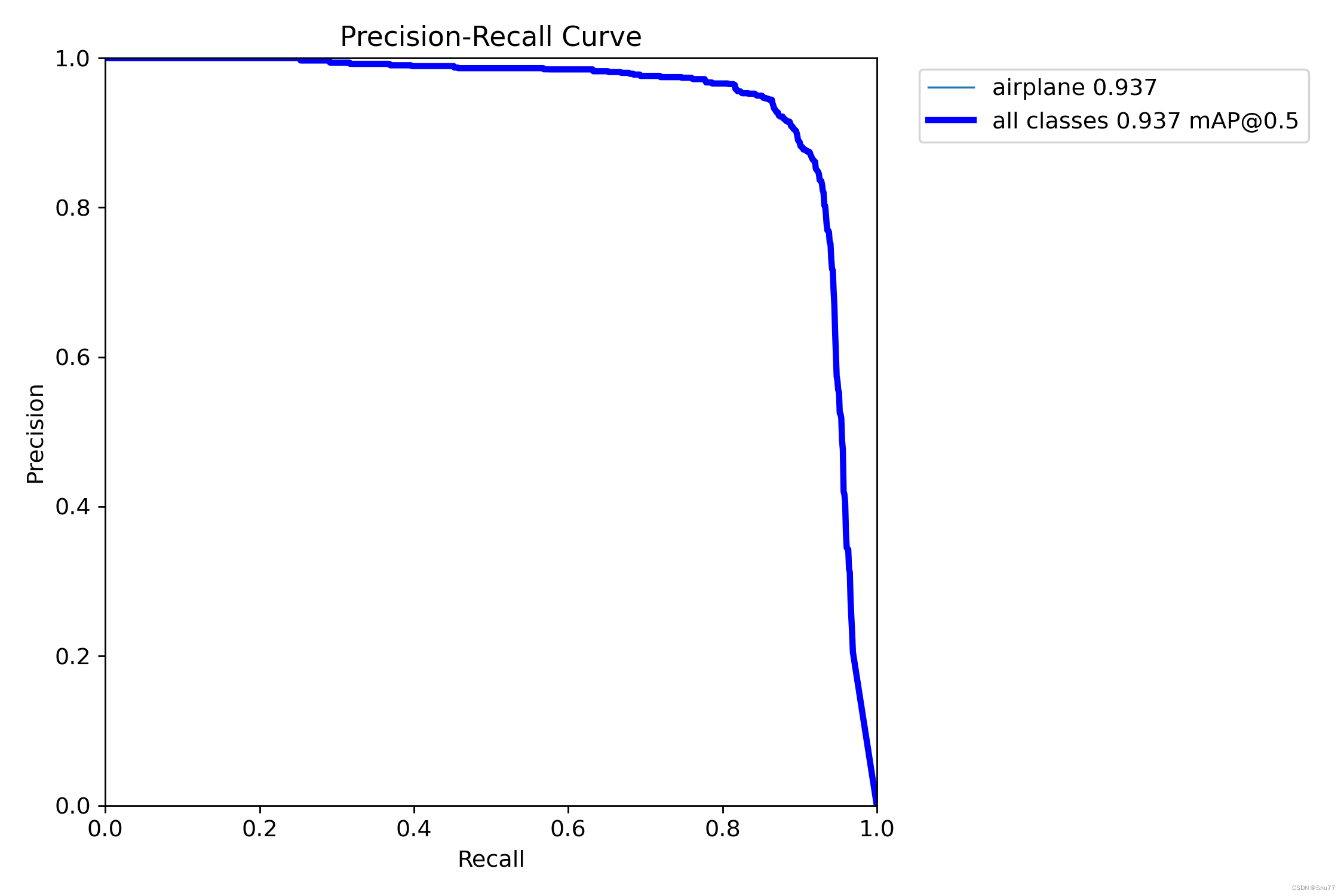
PR_curve
它显示了在不同分类阈值下模型的精确度(Precision)和召回率(Recall)之间的关系。
PR曲线越靠近坐标轴的左上角,模型性能越好,越能够正确识别正样本,正确分类正样本的Precision值越高,而靠近右侧则说明模型对正样本的识别能力较差,即召回能力较差。
PR曲线的特点是随着分类阈值的变化,精确度和召回率会有相应的改变。通常情况下,当分类模型能够同时保持较高的精确度和较高的召回率时,PR曲线处于较高的位置。当模型偏向于高精确度或高召回率时,曲线则相应地向低精确度或低召回率的方向移动。
PR曲线可以帮助我们评估模型在不同阈值下的性能,并选择适当的阈值来平衡精确度和召回率。对于模型比较或选择,我们可以通过比较PR曲线下方的面积(称为平均精确度均值,Average Precision, AP)来进行定量评估。AP值越大,模型的性能越好。
总结:PR曲线是一种展示分类模型精确度和召回率之间关系的可视化工具,通过绘制精确度-召回率曲线,我们可以评估和比较模型在不同分类阈值下的性能,并计算平均精确度均值(AP)来定量衡量模型的好坏。
results.csv
results.csv记录了一些我们训练过程中的参数信息,包括损失和学习率等,这里没有什么需要理解大家可以看一看,我们后面的results图片就是根据这个文件绘画出来的。
 results
results
这个图片就是生成结果的最后一个了,我们可以看出其中标注了许多小的图片包括训练过程在的各种损失,我们主要看的其实就是后面的四幅图mAP50、mAP50-95、metrics/precision、metrics/recall四张图片。
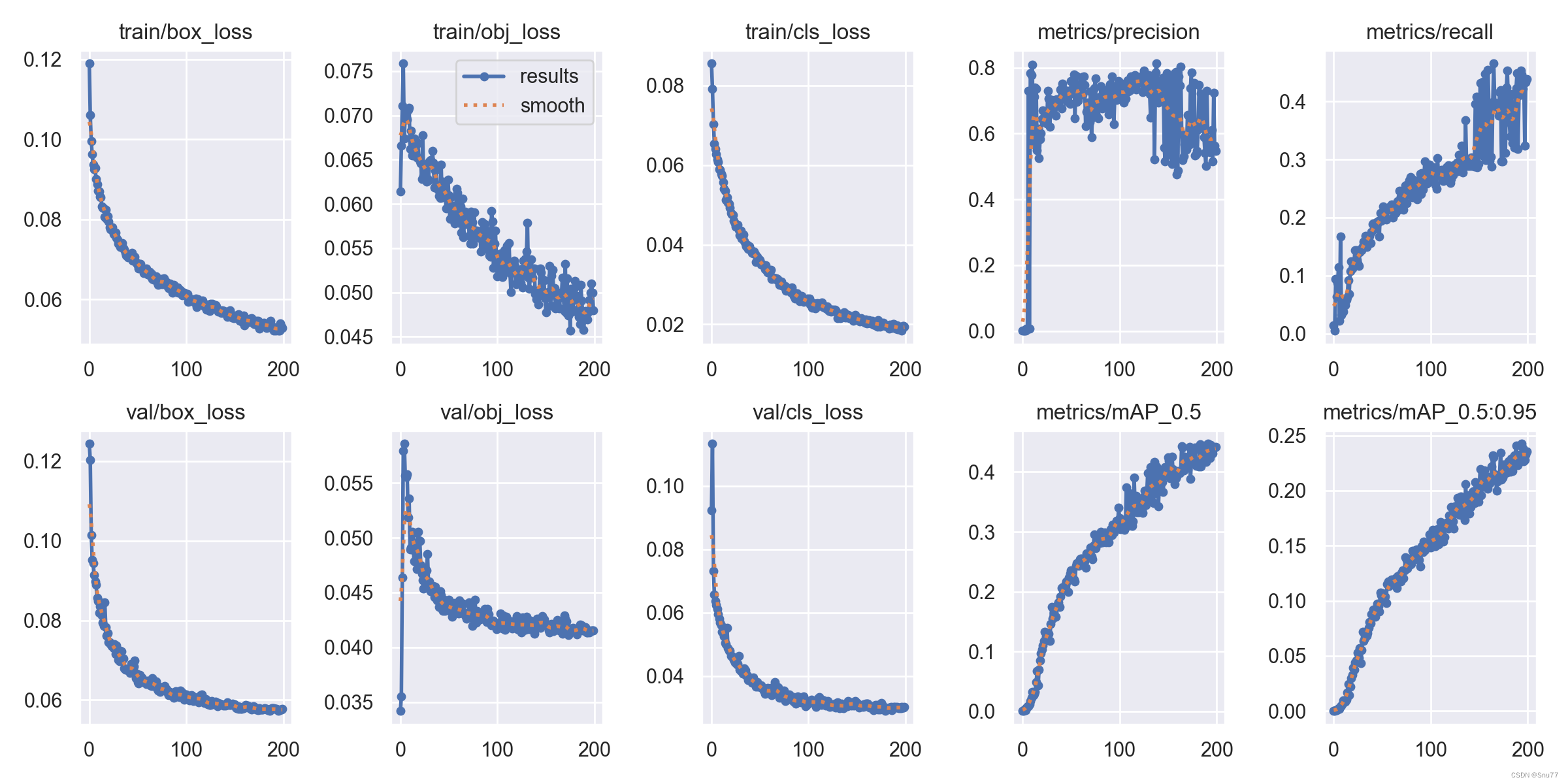
- mAP50:mAP是mean Average Precision的缩写,表示在多个类别上的平均精度。mAP50表示在50%的IoU阈值下的mAP值。
- mAP50-95:这是一个更严格的评价指标,它计算了在50-95%的IoU阈值范围内的mAP值,然后取平均。这能够更准确地评估模型在不同IoU阈值下的性能。
- metrics/precision:精度(Precision)是评估模型预测正确的正样本的比例。在目标检测中,如果模型预测的边界框与真实的边界框重合,则认为预测正确。
- metrics/recall:召回率(Recall)是评估模型能够找出所有真实正样本的比例。在目标检测中,如果真实的边界框与预测的边界框重合,则认为该样本被正确召回。
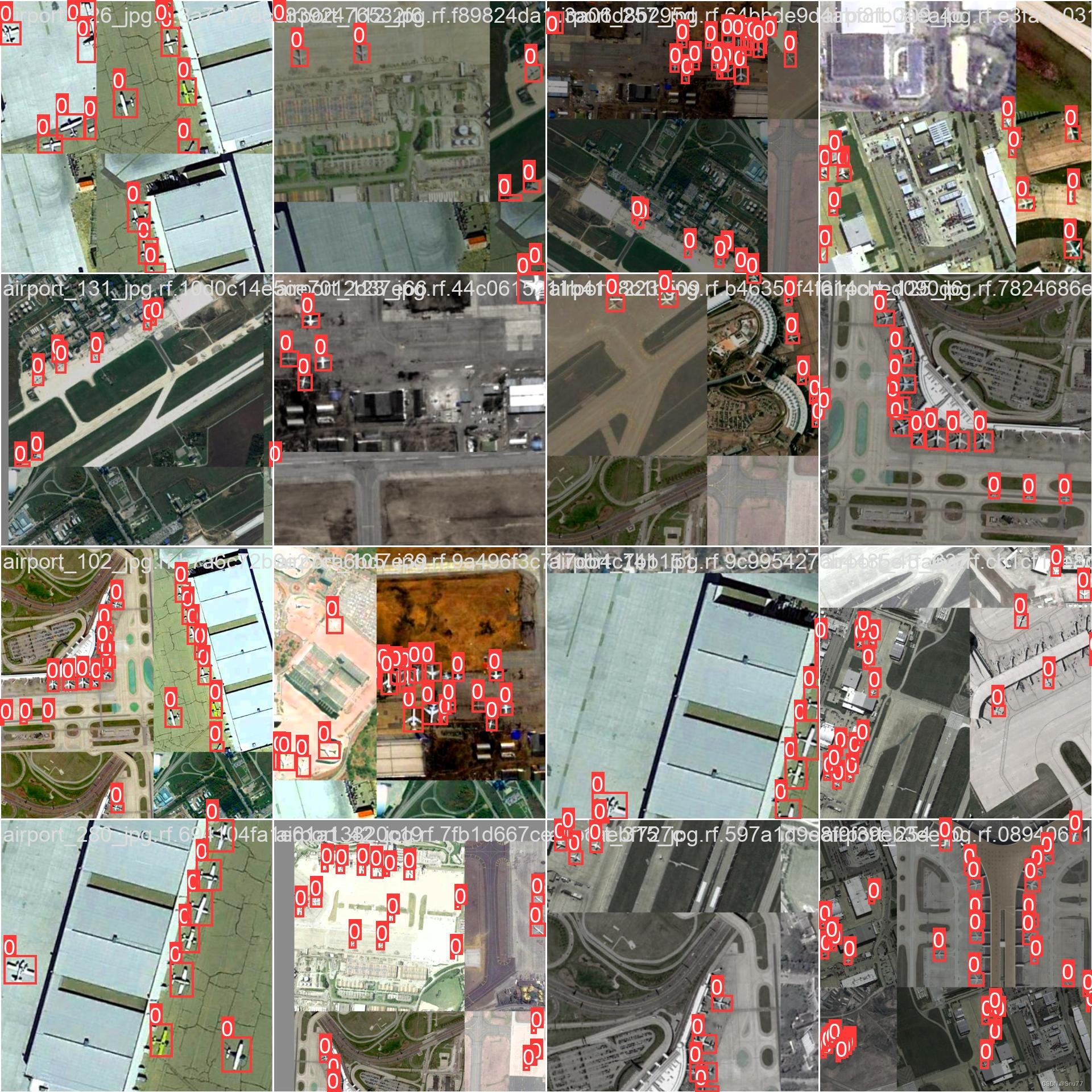
检测效果图
最后的十四张图片就是检测效果图了,给大家看一下这里没什么好讲解的了。
其它参数
FPS和IoU是目标检测领域中使用的两个重要指标,分别表示每秒处理的图片数量和交并比。
- FPS:全称为Frames Per Second,即每秒帧率。它用于评估模型在给定硬件上的处理速度,即每秒可以处理的图片数量。该指标对于实现实时检测非常重要,因为只有处理速度快,才能满足实时检测的需求(推理速度有关系等于nms时间 +预处理时间 然后用1000除以这三个数就是fps,现在轻量化提高FPS是一个比较流行的发论文方向且比较简单一些)。
- IoU:全称为Intersection over Union,表示交并比。在目标检测中,它用于衡量模型生成的候选框与原标记框之间的重叠程度。IoU值越大,表示两个框之间的相似性越高。通常,当IoU值大于0.5时,认为可以检测到目标物体。这个指标常用于评估模型在特定数据集上的检测准确度。
在目标检测领域中,处理速度和准确度是两个重要的性能指标。在实际应用中,我们需要根据具体需求来平衡这两个指标。
总结
到此为止本篇博客就完结了,大家如果有什么不理解的可以在评论区留言,我看到了会给大家进行解答,大家通过综合考虑这些指标的数值,可以评估YOLOv8模型在目标检测任务中的准确性、召回率、速度和边界框质量等性能表现。根据具体需求,我们可以选择更适合任务场景的模型和参数配置。
最后祝大家学习顺利,科研成功,多多论文!!