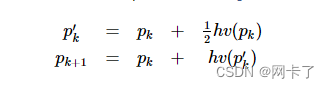简介
deadline调度是比rt调度更高优先级的调度,它没有依赖于优先级的概念,而是给了每个实时任务一定的调度时间,这样的好处是:使多个实时任务场景的时间分配更合理,不让一些实时任务因为优先级低而饿死。deadline调度不是说必须在这个deadline时间点前跑完任务,而是在一个调度周期内,期望在deadline之前调度一次这个任务。理论上这个任务跑的时间是有可能超过deadline时间点,甚至period时间点。
deadline调度策略
三个参数
关于rt调度中优先级是怎么起作用的可以参考之前的一个文章:https://blog.csdn.net/qq_37517281/article/details/134080158
deadline调度用三个额定参数来控制调度,dl_runtime(允许跑的时间) / dl_deadline(期望在一个调度周期内,等待不超过dl_deadline的时间内被调度一次) / dl_period(调度周期)。其中dl_runtime <= dl_deadline <= dl_period。它期望在一个dl_period时长内,任务只能跑dl_runtime的时长,如果没有跑完这个时长,且在同一时间周期内的下次再调度时,只能跑此时到deadline还剩的时间中dl_runtime/dl_deadline的时长;如果下次唤醒已经跳到下一个周期,则可以重新跑dl_runtime的时长;但如果上次跑的时间超过额定的dl_runtime,导致runtime<0,则从下一周期中可跑时长应减去超出的时长(new_runtime = dl_runtime+runtime,其中runtime<0)。一个例外是有太多deadline任务,导致某个不幸的deadline任务长时间没被调度,则下几个周期后,他能跑的时长还是重置为dl_runtime。
一个cpu上的task按deadline先到的顺序,组织为一个红黑树dl_rq->root,其中支持迁移的task还会额外组织成一个红黑树dl_rq->pushable_dl_tasks_root。
一个周期内实际可运行的时长用runtime表示,与dl_runtime都表示时长;但到达的时间点用deadline表示,是一个时间点,与dl_deadline表示一个周期内的时长相区别。
每个cpu运行队列的最早deadline组成了一个大顶堆(顶上的cpu的最早deadline最晚到达),当一个任务需要迁移时,在没有idle cpu的情况下,优先选最早deadline最晚到达的cpu做迁移(find_later_rq)
当一个任务执行了runtime后,会有timer让它不再执行(dl_throttled),它的下一次可重新被调度的时间点为deadline+(dl_period - dl_deadline)。(start_dl_timer)
bandwidth与density
有两个概念不易理解:bandwidth = runtime/period,density = runtime/deadline。
可以简单认为bandwidth是cpu与cpu负载之间的关系,density是一个cpu上任务与任务之间的关系。
bandwidth
bandwidth与utilization(runtime占整个周期的比例)的概念可以等同,每个cpu默认有global_rt_runtime(0.95e+9) / global_rt_period(1e+9) = 0.95 的bandwidth(init_dl_rq_bw_ratio)。当一个cpu的总bandwith(sum(runtime)/period)小时,有可能在运行deadline任务之后,将剩余的dl_period-dl_deadline的时长用于运行一些非deadline的任务(比如低级别的cfs任务,但grub_reclaim函数会尽可能减少这种可能,尽量让deadline任务先做)。
- total_bw:一个cpu调度域中所有cpu的deadline task的bandwidth。其中包含所有从其它调度类提升优先级而来的task。
- bw:(常量)一个cpu调度域的每个cpu的最大bandwidth,等于global_rt_runtime(0.95e+9) / global_rt_period(1e+9)=0.95
- extra_bw:一个cpu运行队列上可分摊到其它域内cpu的空闲bandwidth,最初没有任务时,extra_bw=max_bw。
- this_bw:一个cpu运行队列上active 与非active的task的bandwidth和。
- max_bw:(常量)一个cpu运行队列上的最大bandwidth,等于global_rt_runtime(0.95e+9) / global_rt_period(1e+9)=0.95。
- running_bw:一个cpu运行队列上非inactive任务的bandwidth,它的更新有延迟。wakeup任务时就可add,但任务block 要sub这个bandwidth要等到快到deadline时间点(称为zerolag_time)(更准确的讲是等到deadline前这个时长的时间点:(runtime/dl_runtime)×dl_period)。可以参考下面的图,图中有三种状态:
- active contending:唤醒状态,进入运行队列
- non contending:挂起任务,移出运行队列,但还没有到zerolag_time时间点
- inactive:挂起任务,移出运行队列,且本周期已结束
- 另外还有一个状态 throttled:当一个任务执行runtime后没执行完,要先睡至下个周期开始。或者任务主动yield也是throttled状态。两种情况都要移出运行队列。但其bw依然认为是在队列上且running的。可以认为还在active contending状态。
** +------------------+ * wakeup | ACTIVE | * +------------------>+ contending | * | add_running_bw | | * | +----+------+------+ * | | ^ * | dequeue | | * +--------+-------+ | | * | | t >= 0-lag | | wakeup * | INACTIVE |<---------------+ | * | | sub_running_bw | | * +--------+-------+ | | * ^ | | * | t < 0-lag | | * | | | * | V | * | +----+------+------+ * | sub_running_bw | ACTIVE | * +-------------------+ | * inactive timer | non contending | * fired +------------------+ *
当向一个调度域中加入一个task时,调度域的total_bw会增加,但要先校验是否overflow,即total_bw + new > bw * total_capacity(total_capacity指域内所有cpu的算力)。然后在每个cpu上均摊减掉extra_bw。
density
density是一个cpu上各deadline任务之间的一个平衡概念,期望每个deadline任务的density都不超过额定的dl_runtime/dl_deadline(CBS rule),当有任务在一个调度周期内,睡眠一定时间又被唤醒时,这个突发的唤醒可能导致它的density过高(因为这个周期的时间已经只剩一部分了,剩余runtime还按完整周期来算,当然会高),需要尝试减少它可执行时长,来平衡与其它任务的关系(Revised CBS rule),即 runtime = (deadline - now) * density。(update_dl_revised_wakeup)
其它名词
dl.overloaded与pushable_queue:overload不是说真的任务忙,而是说这个队列1有可在其它cpu执行的任务a,记在pushable_queue红黑树上。当这个任务a没有在运行时,允许其它队列2与任务a比较deadline的先后,如果比队列2的所有任务deadline都早,就尝试steal这个任务a去执行(特殊情况是,这个任务a比队列2的deadline都早,但任务a又在一些关键区,而被设置了无法迁移(migrate_disable),这时的策略是,给队列1一个信号,让它去检查,是否可以把在运行的任务b迁移出去,从而给这个不能迁移的任务a一个运行机会)。
task生命周期
通用调度过程
调度的大体过程为:
1、选下一个任务(__schedule->pick_next_task):这里会先pull一些其它队列的任务过来(dl_sched_class->balance->pull_dl_task),然后将前一个任务放下(dl_sched_class->put_prev_task),选下一个任务(dl_sched_class->pick_next_task),将它set到队列的next上(pick_next_task>set_next_task),同时注册push的callback(set_next_task->deadline_queue_push_tasks)
2、切换上下文(context_switch->switch_to)
3、切换之后,尝试调push callback将一些可迁移任务给其它cpu队列(finish_task_switch->finish_lock_switch->__balance_callbacks->push_dl_tasks)
deadline任务生命周期
一个任务被选中的开始是第一步中的set_next_task_dl,在这里开启一个计时器至可运行时长runtime结束(start_hrtick_dl),切换运行前,会将任务从迁移队列移出(dequeue_pushable_dl_task),然后运行一段时间后,可预见两种情况(其它情况,比如优先级提升,主要re):
1、runtime用完,高精计时器到达,触发task_tick_dl
2、主要yield让出cpu,触发yield_task_dl
这两种都会调用update_curr_dl更新剩余runtime。如果runtime用完了,队则任务退出运行列,和可迁移队列(__dequeue_task_dl),标记throtled,并启动计时至下个周期开始(start_dl_timer)才重新回到队列。如果runtime没有用完(比如set_next_task_dl->start_hrtick_dl开始计时后,被其它进程抢占,又回到这个进程执行,则runtime没有用完),这时如果它还是最先到deadline的task,则会对剩余的runtime重新调start_hrtick_dl计时。如果是主动sleep的情况,虽然退出队列了,但不会马上将bandwidth去掉,而是开启inactive_task_timer计时,到deadline时间点才将bandwidth去掉(实际是deadline - dl_period*(runtime/dl_runtime)的时间点)(task_non_contending)。
在中断恢复时,触发一次系统的schedule(),它会走pick_next_task的流程,根据deadline是否还是最先到达来决定是否换到其它任务。它可能会选中其它任务,这时将原任务放回可迁移队列(put_prev_task_dl->enqueue_pushable_dl_task)
当throtled到的下一个周期到达时,会将task重新加回运行队列(dl_task_timer->enqueue_task_dl(ENQUEUE_REPLENISH)),并标记resched_curr()来让调度器发现这个任务,重新做抉择。
剩余runtime的扣除
上面提到的更新剩余runtime的方法,在grub(Greedy Reclamation of Unused Bandwidth)算法中不是直接减去运行时长,而是
这个公式在扣除runtime时考虑了总体空闲的情况,将总体的非active的时长(not running 和 extra的时长)分一部分给这个task,让他能再多跑一会(可以看到runtime减去的时间一定小于真实duration),从而减少一个周期内deadline任务都被延迟到下一周期,而本周期中没有deadline任务可跑的情况。(参考的这个pdf:http://retis.santannapisa.it/luca/ospm-summit/2017/Downloads/deadline_reclaiming.pdf,不确定我的理解对不对)
代码注释
enqueue_task_dl
enqueue_task_dl():
// 如果task是从其它优先级提升到deadline的
// 则不需要throttled到下个周期,因为它只是个临时行为
//(比如一个cfs进程1拿了一个锁,而一个deadline进程2在等这个锁,
// 则进程1会临时提升为deadline调度级别)
if (is_dl_boosted() || !dl_prio(p->normal_prio)) {
p->dl.dl_throttled = 0;
}
// 如果一个task还没有throttled,且超过了deadline,则标记throttled,
// 并启动计时期至下个周期才解除throttled(deadline + (dl_period - dl_deadline))
// 和重新装填runtime 和 deadline并在deadline前合适的时候调度
if (!p->dl.dl_throttled && !dl_is_implicit(&p->dl))
dl_check_constrained_dl(&p->dl);
enqueue_dl_entity():
if (flags & ENQUEUE_WAKEUP) {
// 如果是一个从suspend状态激活的任务,且当前时间还没有超过deadline
// 由于这个周期的时间已经只剩一部分了,而原来的runtime是按完整周期来算,
// 算出的density(=runtime/deadline)会比额定的(dl_runtime/dl_period)要大。
// 所以要对可运行时间做修剪:
// runtime = (dl_runtime / dl_deadline) * (deadline - now())
//
// 对于超过deadline,说明这个周期内都没有调度机会
// 或已经用完了这个周期的运行时间后睡眠了dl_period-dl_deadline时长
// 这时可以直接重置 runtime = dl_runtime, deadline = now + dl_deadline
update_dl_entity();
} else if (flags & ENQUEUE_REPLENISH) {
// 通过优先级提升来的task,或主要释放cpu的task,
// 或时间已经超过一个周期的task可以重置runtime 与 deadline
// 而因为上个周期执行太久或cpu主频变化导致的执行时间超过可运行时间的场景
// runtime是负的,需要在下个周期中将多的可运行时间减掉 (runtime += dl_runtime)
replenish_dl_entity(dl_se);
} else if (flags & ENQUEUE_RESTORE) {
// 因修改task参数(比如修改优先级或可运行的cpu集合)
// 导致的dequeue和重新enqueue,强制重置runtime与deadline
setup_new_dl_entity()
}
__enqueue_dl_entity():
// task 加入 deadline 运行队列
rb_add_cached(&dl_se->rb_node, &dl_rq->root, __dl_less);
// 更新cpu队列上最早的deadline值
// 并更新这个cpu的最早deadline值在整个调度域中的排名
//(按从deadline晚到早排序,用堆结构来组织,
// 可用于为一个任务选择下个周期在哪个cpu上执行,优选deadline晚的执行)
inc_dl_tasks(dl_se, dl_rq);
// 如果这个任务支持在其它cpu上跑,则可以被别人拿走执行
// 按deadline先后进入pushable排序队列
enqueue_pushable_dl_task()dequeue_task_dl
dequeue_task_dl()
// 更新任务的runtime,如果runtime用完,则要throtle(退出队列,并在下个周期开始时回到队列)
update_curr_dl();
__dequeue_task_dl():
// 除去运行队列中的项,更新cpu的最先到达deadline
// 和在所有cpu最先到达deadline大顶堆中的位置
dequeue_dl_entity();
// 从可迁移队列移出,如果没有可迁移task,则清除overload标记
dequeue_pushable_dl_task();
// 对于 sleep 导致的出队,需要开启计时inactive_timer到deadline的时间点再更新bandwidth
task_non_contending();update_curr_dl
按grub算法扣除可运行时长,如果没有可运行时长了,则throttle至下个周期
// 在运行一段时间后中断中调用。
update_curr_dl()
// 更新执行时间
update_current_exec_runtime();
// 扣除时长为 dq = -(max{u, (Umax - Uinact - Uextra)} / Umax) dt
dl_se->runtime -= grub_reclaim();
// 如果剩余runtime小于0或主动让出cpu,则标记throttled,但这不会改变其bandwidth
if (dl_runtime_exceeded(dl_se) || dl_se->dl_yielded) {
dl_se->dl_throttled = 1;
// 将它移出队列
__dequeue_task_dl();
// 如果它是其它调度类通过优先级提升而来的任务(这种临时任务不用睡眠等待)
// 或dl任务启动计时失败,则再加回来
if (unlikely(is_dl_boosted(dl_se) || !start_dl_timer(curr)))
enqueue_task_dl(rq, curr, ENQUEUE_REPLENISH);
// 大概率它不在运行队列上了,所以,标记重调度
if (!is_leftmost(curr, &rq->dl))
resched_curr(rq);
pull_dl_task
从其它cpu的可迁移队列拉任务过来。
比如从deadline类型转为其它类型,发现没有deadline任务可以调度了(switched_from_dl)
pull_dl_task():
// 遍历每个有可迁移任务的cpu
for_each_cpu(cpu, this_rq->rd->dlo_mask) {
// 找到比当前cpu的deadline先到的task,从这些task中找到最早到deadline的
..
// 如果可在本cpu运行,则拿来。
deactivate_task(src_rq);
set_task_cpu(this_cpu);
activate_task(this_rq);
// 如果因为一些临时原因不能迁移,则尝试在它所在cpu上换掉正运行的
// (前提是正运行的task可迁移,为它找合适的迁移队列)
stop_one_cpu_nowait(push_cpu_stop);
}push_dl_tasks
将可迁移任务主动推到其它cpu执行
比如下一个task不能抢占当前task,且下一个可以迁移(task_woken_dl)
这里代码为纯逻辑顺序,没按原代码组织,原代码版本linux v6.6
push_dl_tasks():
// 尝试迁移每个pushable task,直到有一个迁移失败。
while (push_dl_task(rq)):
next_task = pick_next_pushable_dl_task(rq);
find_lock_later_rq(next_task):
// 为这个任务找合适的队列迁移过去
find_later_rq();
// 如果找到了下一个队列,则入那个队,并resched_curr那个队列。
deactivate_task(rq, next_task, 0);
set_task_cpu(next_task, later_rq->cpu);
activate_task(later_rq, next_task, 0);
resched_curr(later_rq);
// 如果没找到下一个队列,且没有新的pushable task加入,则不再尝试
if (!dl_task_is_earliest_deadline(task, later_rq)) break;
// 如果pushable task变了,则有可能有新task,重试最多三次。
..
find_later_rq():
// 找调度域中idle的cpu中bandwidth能满足这个task的cpu集合
// 如果bandwidth都不满足,则找算力最大的cpu
// 如果没有 free 的 cpu,则找最早deadline大顶堆中最晚到达deadline的那个cpu,
// 确认这个任务的deadline在那个cpu的最早deadline之前,并选中它
// 找到的cpu或cpu集合标记为A
cpudl_find(&task_rq(task)->rd->cpudl, task, later_mask);
// 从原cpu的domain里一层层向上找,与上面备选集合A的交集B
// 如果有cpu要求在唤醒过程中考虑亲和性(SD_WAKE_AFFINE标记)则优先考虑
for_each_domain(cpu, sd) {
// 如果当前cpu在这个B集合中,则用当前cpu是最好的,不做迁移
// 否则用round-robin方式在cpu集合B中找一个cpu
cpumask_any_and_distribute(later_mask, sd);
}
如果所有备选cpu都没有SD_WAKE_AFFINE标记,则用round-robin方式在备选集合A中找一个cpu
cpumask_any_distribute(later_mask);set_next_task_dl
标记即将运行的任务是这个任务
set_next_task_dl():
// 将要在本cpu运行的task,不再支持被其它cpu倫过去执行
dequeue_pushable_dl_task();
// 启动定时到可运行时长runtime耗尽
start_hrtick_dl();
// 更新load值
// 参考:https://blog.csdn.net/qq_37517281/article/details/134039766
update_dl_rq_load_avg非deadline调度类,load sum 累加0,load avg 累加1,
// 在切换至这个task后,尝试将下一个到deadline的进程迁移到其它cpu执行
deadline_queue_push_tasks(push_dl_tasks);wakeup_preempt_dl
判断是否可抢占当前task
wakeup_preempt_dl():
// 两任务deadline不同,选deadline先到的
// 两任务deadline相同,原则是尽可能不抢占,可抢占的条件:
// 运行中任务可移动且超过了deadline,且要换入的任务不可移动且deadline没到。put_prev_task_dl
将前一个任务从运行队列移除
put_prev_task_dl():
// 扣除运行时长
update_curr_dl();
// 累积load_sum/avg
update_dl_rq_load_avg();
// 如果任务可在其它cpu执行,则加入可迁移队列,并在下次调度时尝试迁移
enqueue_pushable_dl_task();switched_to_dl
从其它调度类型切至deadline调度
switched_to_dl():
// 如果这个任务在一个周期时间内迁走又迁回,则将计时器去掉
if (hrtimer_try_to_cancel(&p->dl.inactive_timer) == 1)
put_task_struct(p);
// 任务不是当前队列的任务
if (rq->curr != p) {
// 如果它可迁移,加入pushable队列
deadline_queue_push_tasks();
// 尝试抢当前在跑的task
wakeup_preempt_dl();
}
// 如果提升优先级变为deadline任务,或用户指定它调度类型变更
// 它的cpu没有变,还是之前运行的cpu,需要更新下load
update_dl_rq_load_avg();