前言
本文分享BEV感知方案中,具有代表性的方法:BEVFormer。
它基于Deformable Attention,实现了一种融合多视角相机空间特征和时序特征的端到端框架,适用于多种自动驾驶感知任务。
主要由3个关键模块组成:
- BEV Queries Q:用于查询得到BEV特征图
- Spatial Cross-Attention:用于融合多视角空间特征
- Temporal Self-Attention:用于融合时序BEV特征
基本思想:使用可学习的查询Queries表示BEV特征,查找图像中的空间特征和先前BEV地图中的时间特征。
采用3D到2D的方式,先在BEV空间初始化特征,通过在BEV高度维度“升维”形成3D特征。再通过映射关系,使用多层transformer与每个图像2D特征进行交互融合,最终再得到BEV特征。
论文地址:BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
代码地址:https://github.com/fundamentalvision/BEVFormer

一、框架思路
看看BEVFormer的设计思路,它使用可学习的查询Queries表示BEV特征。BEV Queries是一种栅格形状的可学习参数,它通过注意力机制在多视角图像中查询和聚合特征。
通过BEV Queries,查找图像中的空间特征和先前BEV地图中的时间特征,得到融合和更新后查询特征,也就是BEV特征。
一开始得到BEV特征并不准确,通过不断融合特征和更新后,得到的BEV Queries也就是准确的BEV特征了。
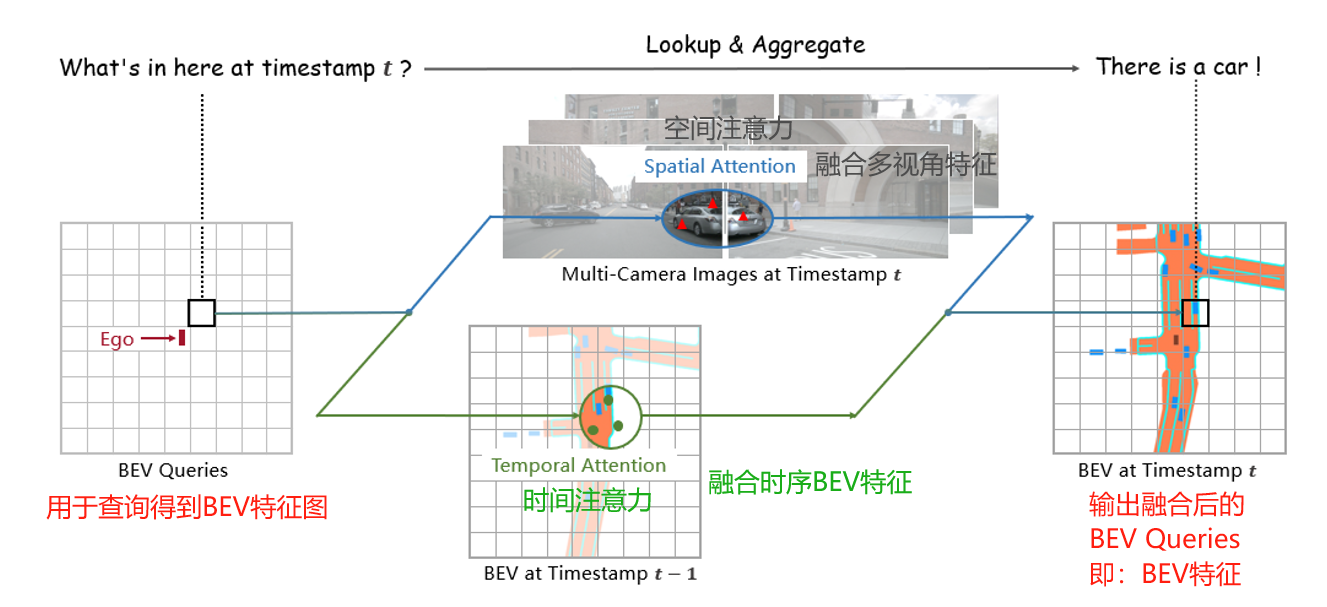
下面看看BEVFormer的框架思路,可以分为7步组成,如下图所示:
- 输入多视角图像,经过主干网络提取图像特征,形成多视角特征图。
- 通过BEV Queries,首先查询先前时序的BEV特征,融合对应的特征。再融合图像的空间特征。
- 融合了时间和空间特征的BEV Queries,也就是BEV特征。
- BEV特征后面接不同任务头,比如:3D检测、BEV分割、轨迹预测等等。
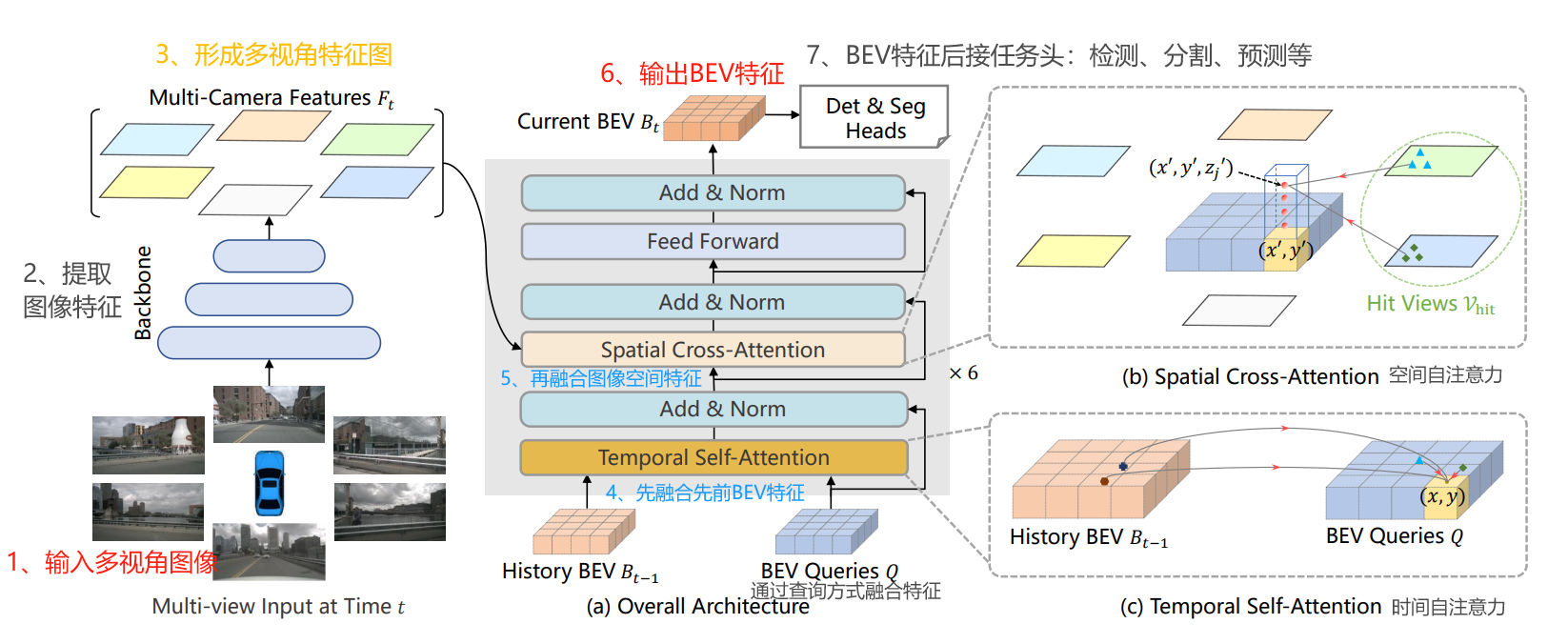
BEVFormer的主体由6层结构相同的编码器层组成,每一层都是基于:
- 时序自注意力(Temporal Self-attention)
- 加法(Add)标准化(Norm)
- 空间交叉注意力(Spatial Cross-attention)
- 加法(Add)标准化(Norm)
- 前馈网络(Feed Forward)
- 加法(Add)标准化(Norm)
详细分析模型前向推理过程:
-
在时间点t,将车辆上多个视角的相机图像输入到主干网络中,输出各图像的多尺度特征,表示为
,其中 i 是第i个视角相机的特征, n是相机视角的总数。同时,保留时间点t-1的BEV特征
。
-
在每个BEVFormer编码器层中,首先使用BEV Queries Q 通过时间自注意力(Temporal Self-attention, TSA)模块从
-
然后,对TSA修正过的BEV Queries Q′,通过空间交叉注意力(Spatial Cross-attention, SCA)模块从多摄像头特征
-
将经过两次修正的BEV Queries Q′′ 输入到前馈网络计算,然后输出,作为下一个编码器层的输入。
-
如此堆叠6层,即经过6轮微调,时间点t的统一BEV特征
就生成了。
-
最后,将BEV特征作为任务头的输入,比如:3D检测头和地图分割头。
二、关键设计——BEV Queries 查询得到BEV特征图
BEV平面(Bird's-Eye View,鸟瞰视图)是一个以车辆自身为中心的,被划分成许多小方格的二维平面。
这个平面的高度H和宽度W代表了:在x轴(横向)和y轴(纵向)上的栅格数量。
BEV平面直观地反映了车辆周围的物理空间,其中每个小方格代表现实世界中的一定面积,例如s米。
比如针对nuScenes数据集,可能会定义BEV平面的栅格尺寸为200x200,这意味着这个平面可以覆盖从车辆中心向各个方向延伸51.2米的区域。在这种情况下,每个小方格(栅格)代表的实际面积是0.512米。
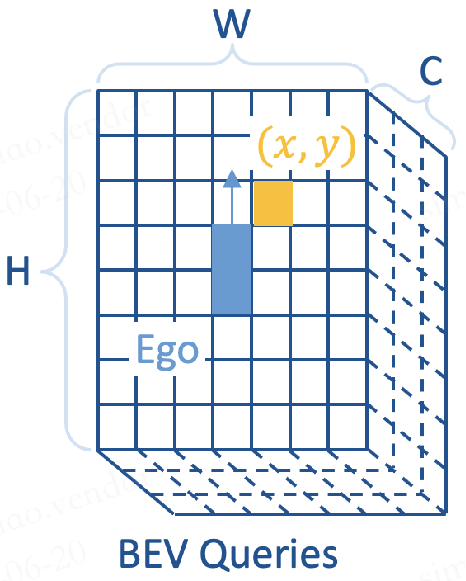
关键要的:
1、BEV Queries是一组预先定义的、具有栅格形状的可学习参数, 维度是H*W*C,用来捕获围绕自车的BEV特征。
简单来说,一旦学习完成,BEV Queries就会变成BEV features,即鸟瞰视图特征。
2、BEV Queries的高度H和宽度W,与BEV平面在x轴(横向)和y轴(纵向)的栅格尺寸保持一致,这意味着它们也具有与BEV平面类似的特性,即直观地映射车辆周围的物理空间。
然而,BEV Queries的C维,即在通道(channel)维度上的尺寸,并不直接对应于BEV平面z轴的物理空间尺寸。
3、每个位于(x, y)位置的query都仅负责表征其对应的小范围区域。轮番查询“空间信息”和“时间信息”,生成BEV特征图。
重点:BEV Queries在模型中经过连续的微调和转换,最终成为BEV features。
三、核心内容——Spatial Cross-Attention融合多视角空间特征
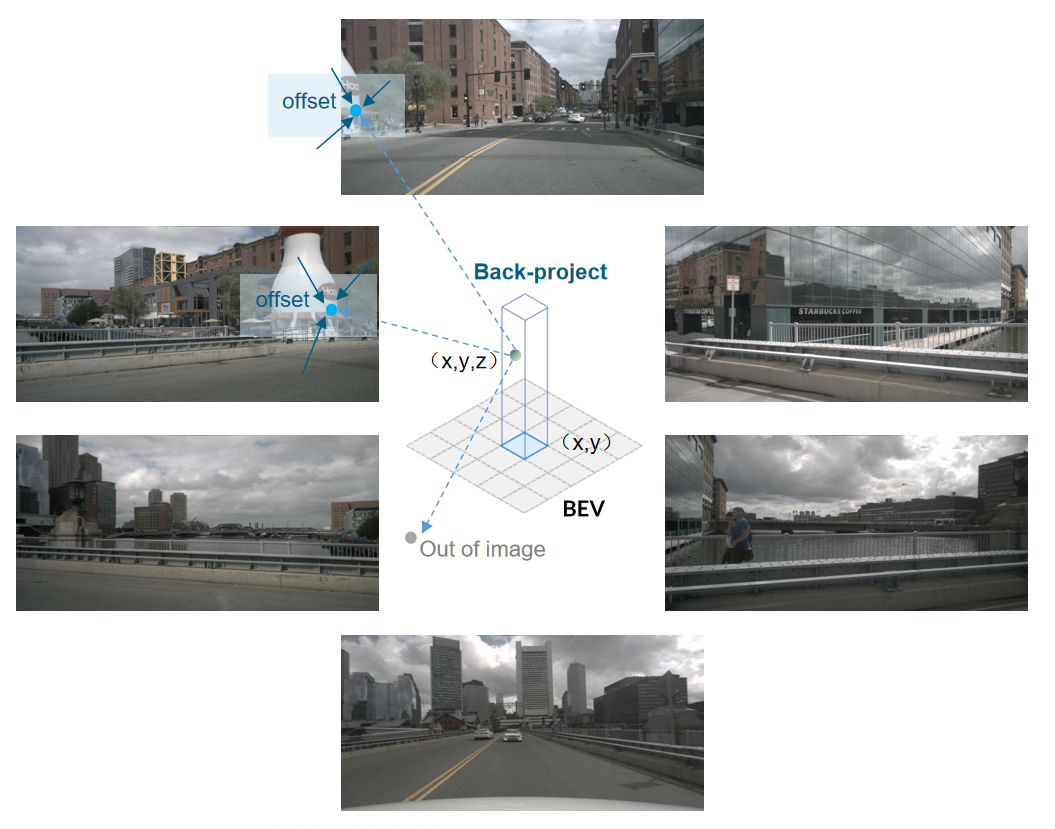
通过BEV Queries查询和融合空间信息,BEV Queries表示整幅栅格图,BEV Query表示其中一个网格,步骤如下:
- 将每个BEV Query拉升为一个支柱。在z方向进行lift操作,预测该网格的离散高度,形成N个高度值。预定义它们对应的高度范围是-5m到3m。结合该网格的x,y坐标,生成N个3D参考点。
- 通过相机内外参,将柱子中的3D参考点投影到视图中,得到2D点,数量记为V_num。正常一个3D参考点,对应1~2幅多视图,毕竟不能所有相机都看到同一个物体。
- 从命中视图中的区域中采样特征。采用Deformable Attention,把像平面上的这些投影点作为2D图像参考点,在其周围进行特征采样。
- 最后,每个3D参考点有V_num个特征图,进行加权求和。每个网格有N个3D参考点,形成的特征图,进行加权求和,最终输出多视角空间特征。

如下图所示,一个3D参考点(x, y, z),投影到多视角图中,只有2幅是对应的。这样很正常,毕竟相机是四周安装的,不可能所有相机都看到同一个物体。
四、核心内容——Temporal Self-Attention融合时序BEV特征
受到经典的循环神经网络(RNN)的启发,BEV特征 可以被视作一种能够传递序列信息的“记忆体”。
在这种框架下,每一个时刻生成的BEV特征 都是基于上一时刻的BEV特征
来获取所需的时序信息。
- 这种方法的优势在于,它能够动态地获取所需的时序特征,而不是像简单地堆叠不同时刻的BEV特征那样,仅能获取固定长度的时序信息。
- 这种动态获取时序特征的方式使得BEV特征能够更加有效地反映出环境的动态变化,比如车辆的移动或周围环境的变化。

融合时序BEV特征,通过BEV Queries 查询时间信息,步骤如下:
- 根据自我运动对齐两个时刻的BEV图。两个时刻是指上一时刻和当前时刻。目前是使得相同索引位置的栅格,对应于现实世界中的同一位置。
- 从过去时刻BEV图的和当前采样特征。
- 对过去和当前BEV图中采样的特征进行加权求和。
- 使用RNN风格迭代收集历史BEV图特征。
思路流程:
- 在给定时间点t-1的BEV特征
的情况下,首先需要根据自我运动(ego motion)将
- 这个对齐过程确保了
在相同索引位置的栅格对应于现实世界中的同一位置。这样对齐后的BEV特征记作
。
- 在时间点t,位于网格中A处的BEV query所代表的物体可能是静态的(不动的)或者是动态的(在移动中)。
- 这个物体在时间点t-1会出现在
通过这种方式,模型能够更加准确地捕捉到物体随时间的动态变化。
可变形注意力允许模型关注于相邻时刻在空间上对应但位置可能略有变化的特征,从而有效地捕捉动态物体的运动轨迹和静态物体的稳定性。
这种方法在处理时序数据时,特别是在动态和复杂的环境中,如自动驾驶场景下,显得尤为重要和有效。
五、任务头
得到的BEV特征用于后面的感知任务,具体以下特征。
- 多任务学习:3D目标检测和地图语义分割。
- 可迁移性:常用的2D检测头,都可以通过很小的修改迁移到3D检测上。
在3D目标检测方面,论文借鉴了2D目标检测器Deformable DETR(可变形的DEtection TRansformer)的设计思路,并发展出了一种端到端的3D目标检测头。这种检测头的修改和特点包括:
-
输入:使用单尺度的BEV特征 作为检测头的输入。这与Deformable DETR通常使用多尺度特征的做法不同。
-
预测输出:与预测2D边界框不同,3D目标检测头预测3D边界框和物体的速度。。
-
候选目标集合:继承DETR方法的优势,在预测时生成有限数量的候选目标集合。在开源工程中,这个集合的大小通常设置为300个目标。
-
无需NMS后处理:由于这种end-to-end的检测头直接预测目标集合,因此不需要传统的非极大值抑制(Non-Maximum Suppression, NMS)后处理。这是一个显著的优势,因为NMS通常是目标检测流程中的一个复杂且效率较低的步骤。
在地图分割方面,论文参考了2D分割方法Panoptic SegFormer来设计map segmentation head。
基于BEV的地图分割在本质上与常见的语义分割任务类似。作者采用了以下关键设计:
-
Mask Decoder:使用mask decoder,这是一种专门用于分割任务的解码器,能够有效地处理不同尺寸的特征图,并产生准确的分割mask。
-
Class-Fixed Queries:采用类别固定的查询(class-fixed queries)设计。这种设计方式允许模型为每个特定的语义类别(如汽车、车辆、道路可通行区域和车道线)生成特定的查询。这些查询随后被用于查找和分割图像中对应的对象或区域。
通过这种方式,map segmentation head可以有效地对各种道路和交通元素进行精确的分割,如区分车辆、道路、车道线等。这种方法的优势在于,它能够直接从BEV特征中提取出复杂的道路和交通场景信息,为自动驾驶车辆提供准确的环境理解和导航信息。
六、训练和推理设计
训练设计:
-
时间选择:对于给定的时间点t,在过去2秒内随机选择3个时刻,分别是t-3、t-2和t-1。
-
BEV特征生成:在这3个初始时刻,循环生成BEV特征集 {
,
,
-
Temporal Self-Attention的特殊情况:在计算第一个时刻t-3的temporal self-attention输出时,由于它之前没有BEV特征,因此使用它自身的特征作为前序时刻的输入。在这种情况下,temporal self-attention暂时退化成了普通的self-attention。
推理设计:
-
时间序列处理:在推理过程中,按照时间顺序计算图像序列中的每一帧。
-
BEV特征的持续利用:前序时刻的BEV特征被保持并用于后续时刻的处理。这样,模型在每个时刻都能利用之前时刻的信息。
-
在线推理策略:这种按时间顺序处理并保留前序BEV特征的方法是一种在线(online)推理策略。这种策略在实际应用中通常更高效,因为它能够实时处理连续的输入数据,并持续更新对环境的理解。
七、实现测试与效果
在论文中,针对BEV模型的实现和实验,采取了以下关键的配置和设计决策:
Backbone的选择:
- ResNet101-DCN:使用了从FCOS3D训练得到的参数。
- VoVnet-99:采用了从DD3D训练得到的参数。
多尺度特征和FPN输出:
- 默认情况下,使用FPN(Feature Pyramid Network)输出的多尺度特征,其尺寸包含1/16、1/32、1/64。值得注意的是,在代码中实际上使用了1/8尺寸的特征,例如nuScenes数据集中的116x200的FPN输出。
- 同时,将维度C(通道数)设置为256。
BEV Queries的尺寸设置:
- 在nuScenes数据集实验中,BEV queries的尺寸设置为200x200,对应在x和y方向的感知范围均为[-51.2m, 51.2m],BEV Grid的尺寸精度为0.512m。
- 在Waymo数据集实验中,BEV queries的尺寸设置为300x220,x方向的感知范围为[-35.0m, 75.0m],y方向为[-75.0m, 75.0m],BEV Grid的尺寸精度为0.5m。自车中心位于BEV的(70,150)位置。
Spatial Cross-Attention模块:
- 对每个BEV query,在spatial cross-attention模块中设置 N 个3D参考点,预定义它们对应的高度范围是-5m到3m。
采样点的选择:
- 对每个2D图像参考点(即3D参考点在2D视图上的投影点),在其周围选取4个采样点送入Spatial Cross-Attention。
训练配置:
- 默认情况下,训练24个epoch,学习率设定为一个特定值。
Baselines的选择:
- 为了合理评估task heads的影响并与其他生成BEV方法进行公平比较,选择了VPN和Lift-Splat作为baselines。在这些baseline模型中,保留了原有的task heads和其他设置,但将它们head之前的部分替换为BEVFormer。
BEVFormer的静态版本:
- 在论文中,通过将temporal self-attention修改为普通的self-attention,从而将BEVFormer转变为一个静态模型,命名为BEVFormer-S。这个版本不使用历史BEV Features。
效果对比:



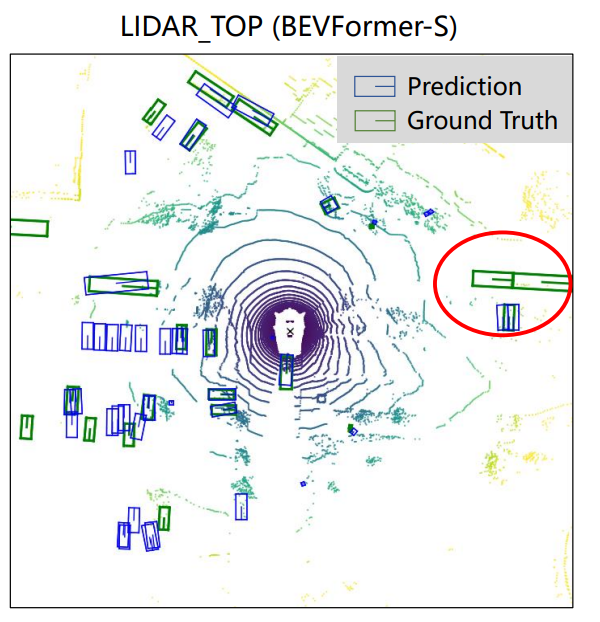
分享完成~