1 nn.Sequential概述
1.1 nn.Sequential介绍
nn.Sequential是一个序列容器,用于搭建神经网络的模块被按照被传入构造器的顺序添加到容器中。除此之外,一个包含神经网络模块的OrderedDict也可以被传入nn.Sequential()容器中。利用nn.Sequential()搭建好模型架构,模型前向传播时调用forward()方法,模型接收的输入首先被传入nn.Sequential()包含的第一个网络模块中。然后,第一个网络模块的输出传入第二个网络模块作为输入,按照顺序依次计算并传播,直到nn.Sequential()里的最后一个模块输出结果。
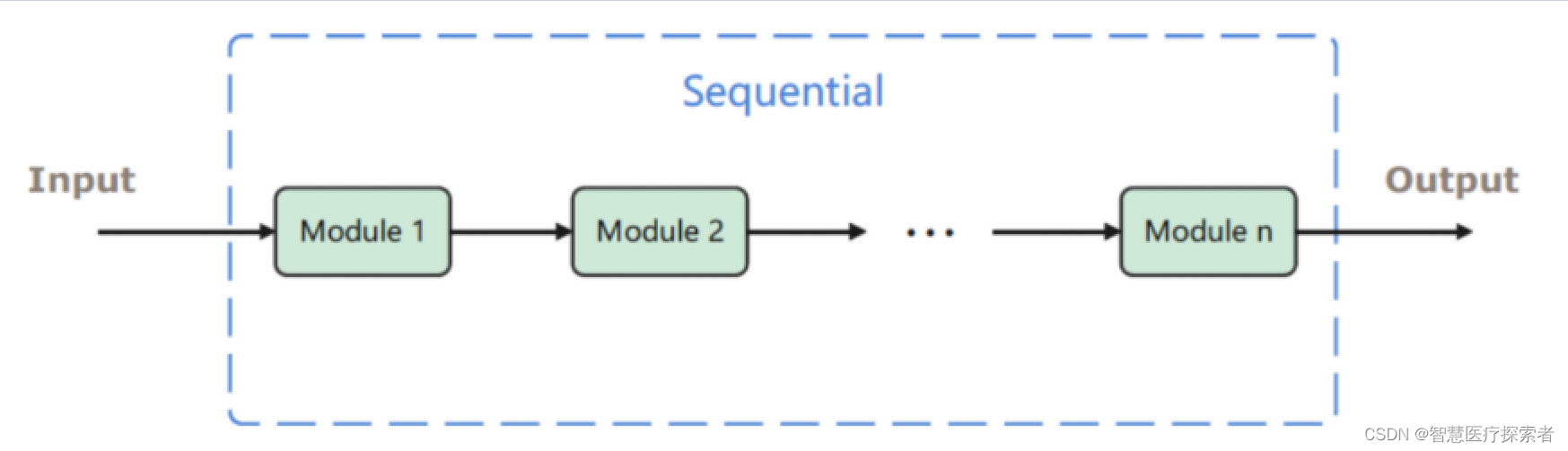
因此,Sequential可以看成是有多个函数运算对象,串联成的神经网络,其返回的是Module类型的神经网络对象。
1.2 nn.Sequential的本质作用
与一层一层的单独调用模块组成序列相比,nn.Sequential() 可以允许将整个容器视为单个模块(即相当于把多个模块封装成一个模块),forward()方法接收输入之后,nn.Sequential()按照内部模块的顺序自动依次计算并输出结果。这就意味着我们可以利用nn.Sequential() 自定义自己的网络层。
示例代码:
from torch import nn
class net(nn.Module):
def __init__(self, in_channel, out_channel):
super(net, self).__init__()
self.layer1 = nn.Sequential(nn.Conv2d(in_channel, in_channel / 4, kernel_size=1),
nn.BatchNorm2d(in_channel / 4),
nn.ReLU())
self.layer2 = nn.Sequential(nn.Conv2d(in_channel / 4, in_channel / 4),
nn.BatchNorm2d(in_channel / 4),
nn.ReLU())
self.layer3 = nn.Sequential(nn.Conv2d(in_channel / 4, out_channel, kernel_size=1),
nn.BatchNorm2d(out_channel),
nn.ReLU())
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x上边的代码,我们通过nn.Sequential()将卷积层,BN层和激活函数层封装在一个层中,输入x经过卷积、BN和ReLU后直接输出激活函数作用之后的结果。
1.3 nn.Sequential源码
def __init__(self, *args):
super(Sequential, self).__init__()
if len(args) == 1 and isinstance(args[0], OrderedDict):
for key, module in args[0].items():
self.add_module(key, module)
else:
for idx, module in enumerate(args):
self.add_module(str(idx), module)nn.Sequential()首先判断接收的参数是否为OrderedDict类型,如果是的话,分别取出OrderedDict内每个元素的key(自定义的网络模块名)和value(网络模块),然后将其通过add_module方法添加到nn.Sequrntial()中。
# NB: We can't really type check this function as the type of input
# may change dynamically (as is tested in
# TestScript.test_sequential_intermediary_types). Cannot annotate
# with Any as TorchScript expects a more precise type
def forward(self, input):
for module in self:
input = module(input)
return input调用forward()方法进行前向传播时,for循环按照顺序遍历nn.Sequential()中存储的网络模块,并以此计算输出结果,并返回最终的计算结果。
1.3 nn.Sequential与其它容器的区别
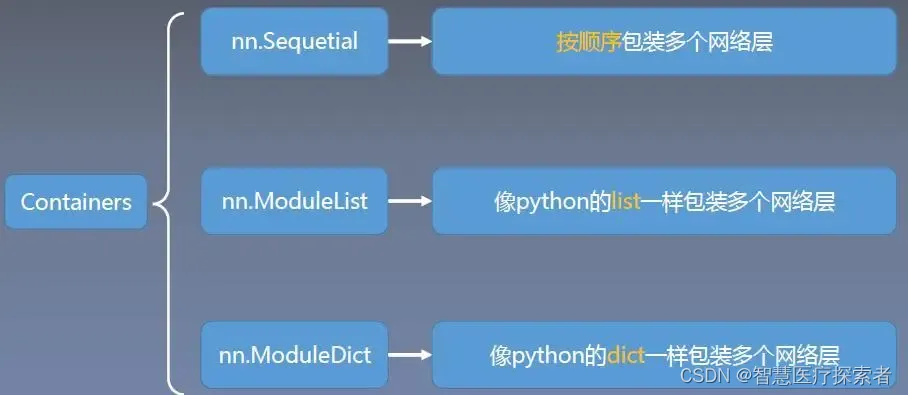
2 使用nn.Sequential定义网络
2.1 顺序添加网络模块到容器中
import torch
import torch.nn as nn
model = nn.Sequential(
nn.Linear(28 * 28, 32),
nn.ReLU(),
nn.Linear(32, 10),
nn.Softmax(dim=1)
)
print("model:", model)
print("model.parameters:", model.parameters)
x_input = torch.randn(2, 28, 28, 1)
print("x_input:", x_input)
print("x_input.shape:", x_input.shape)
y_pred = model.forward(x_input.view(x_input.size()[0], -1))
print("y_pred:", y_pred)运行代码显示:
model: Sequential(
(0): Linear(in_features=784, out_features=32, bias=True)
(1): ReLU()
(2): Linear(in_features=32, out_features=10, bias=True)
(3): Softmax(dim=1)
)
model.parameters: <bound method Module.parameters of Sequential(
(0): Linear(in_features=784, out_features=32, bias=True)
(1): ReLU()
(2): Linear(in_features=32, out_features=10, bias=True)
(3): Softmax(dim=1)
)>
x_input.shape: torch.Size([2, 28, 28, 1])
y_pred: tensor([[0.1127, 0.0652, 0.1399, 0.0973, 0.1085, 0.0859, 0.1193, 0.1048, 0.0865,
0.0800],
[0.0986, 0.0955, 0.0927, 0.0765, 0.0782, 0.1004, 0.1171, 0.1605, 0.0883,
0.0922]], grad_fn=<SoftmaxBackward0>)2.2 包含神经网络模块的OrderedDict传入容器中
import torch
import torch.nn as nn
from collections import OrderedDict
model = nn.Sequential(OrderedDict([('h1', nn.Linear(28*28, 32)),
('relu1', nn.ReLU()),
('out', nn.Linear(32, 10)),
('softmax', nn.Softmax(dim=1))]))
print("model:", model)
print("model.parameters:", model.parameters)
x_input = torch.randn(2, 28, 28, 1)
print("x_input.shape:", x_input.shape)
y_pred = model.forward(x_input.view(x_input.size()[0], -1))
print("y_pred:", y_pred)运行代码显示:
model: Sequential(
(h1): Linear(in_features=784, out_features=32, bias=True)
(relu1): ReLU()
(out): Linear(in_features=32, out_features=10, bias=True)
(softmax): Softmax(dim=1)
)
model.parameters: <bound method Module.parameters of Sequential(
(h1): Linear(in_features=784, out_features=32, bias=True)
(relu1): ReLU()
(out): Linear(in_features=32, out_features=10, bias=True)
(softmax): Softmax(dim=1)
)>
x_input.shape: torch.Size([2, 28, 28, 1])
y_pred: tensor([[0.0836, 0.1185, 0.1422, 0.0801, 0.0817, 0.0870, 0.0948, 0.1099, 0.1131,
0.0892],
[0.0772, 0.0933, 0.1312, 0.1135, 0.1214, 0.0736, 0.1461, 0.0711, 0.0908,
0.0818]], grad_fn=<SoftmaxBackward0>)3 nn.Sequential网络操作
3.1 索引查看子模块
import torch.nn as nn
from collections import OrderedDict
model = nn.Sequential(OrderedDict([('h1', nn.Linear(28*28, 32)),
('relu1', nn.ReLU()),
('out', nn.Linear(32, 10)),
('softmax', nn.Softmax(dim=1))]))
print("index0:", model[0])
print("index1:", model[1])
print("index2:", model[2])运行代码显示:
index0: Linear(in_features=784, out_features=32, bias=True)
index1: ReLU()
index2: Linear(in_features=32, out_features=10, bias=True)3.2 修改子模块
import torch.nn as nn
from collections import OrderedDict
model = nn.Sequential(OrderedDict([('h1', nn.Linear(28*28, 32)),
('relu1', nn.ReLU()),
('out', nn.Linear(32, 10)),
('softmax', nn.Softmax(dim=1))]))
model[1] = nn.Sigmoid()
print(model)
运行代码显示:
Sequential(
(h1): Linear(in_features=784, out_features=32, bias=True)
(relu1): Sigmoid()
(out): Linear(in_features=32, out_features=10, bias=True)
(softmax): Softmax(dim=1)
)3.3 添加子模块
import torch.nn as nn
from collections import OrderedDict
model = nn.Sequential(OrderedDict([('h1', nn.Linear(28*28, 32)),
('relu1', nn.ReLU()),
('out', nn.Linear(32, 10)),
('softmax', nn.Softmax(dim=1))]))
model.append(nn.Linear(10, 2))
print(model)运行代码显示:
Sequential(
(h1): Linear(in_features=784, out_features=32, bias=True)
(relu1): ReLU()
(out): Linear(in_features=32, out_features=10, bias=True)
(softmax): Softmax(dim=1)
(4): Linear(in_features=10, out_features=2, bias=True)
)3.4 删除子模块
import torch.nn as nn
from collections import OrderedDict
model = nn.Sequential(OrderedDict([('h1', nn.Linear(28*28, 32)),
('relu1', nn.ReLU()),
('out', nn.Linear(32, 10)),
('softmax', nn.Softmax(dim=1))]))
del model[2]
print(model)运行代码显示:
Sequential(
(h1): Linear(in_features=784, out_features=32, bias=True)
(relu1): ReLU()
(softmax): Softmax(dim=1)
)3.5 嵌套子模块
import torch.nn as nn
seq_1 = nn.Sequential(nn.Linear(15, 10), nn.ReLU(), nn.Linear(10, 5))
seq_2 = nn.Sequential(nn.Linear(25, 15), nn.Sigmoid(), nn.Linear(15, 10))
seq_3 = nn.Sequential(seq_1, seq_2)
print(seq_3)运行代码显示:
Sequential(
(0): Sequential(
(0): Linear(in_features=15, out_features=10, bias=True)
(1): ReLU()
(2): Linear(in_features=10, out_features=5, bias=True)
)
(1): Sequential(
(0): Linear(in_features=25, out_features=15, bias=True)
(1): Sigmoid()
(2): Linear(in_features=15, out_features=10, bias=True)
)
)



![[Win10系统] Win10 任务栏软件图标显示为空白 | 解决方案](https://img-blog.csdnimg.cn/direct/68a85086a06e411ea3f5408256bb1be7.jpeg#pic_left)

![[Verilog] 设计方法和设计流程](https://img-blog.csdnimg.cn/direct/086c99e34f6c4a909369db7a918f9c42.png)