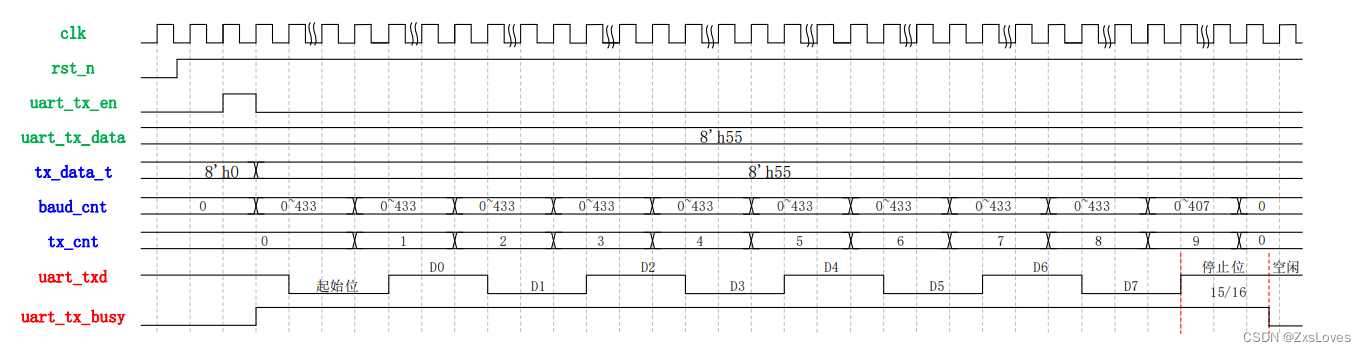
近期,越来越多研究在探索大型语言模型(LLM)在实际应用中的推理和生成能力。随着 ChatGPT 等模型的广泛研究与应用,如何在保留关键信息的同时,压缩较长的提示成为当前大模型研究的问题之一。
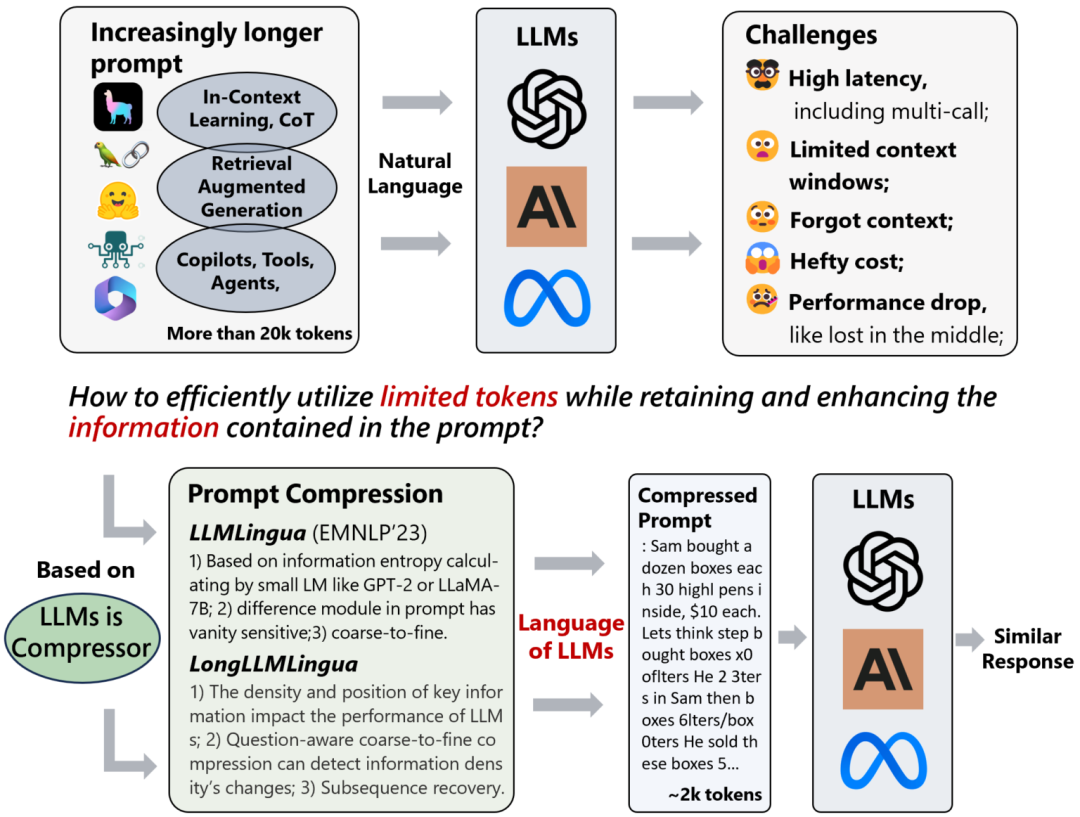
为了加速模型推理并降低成本,微软的新文章提出了一种粒度粗到细的提示压缩方法 LLMLingua,它在对齐后采用了经过良好训练的较小语言模型,通过给提示动态分配不同的压缩比率,在高压缩比率下保持语义完整性。虽然 token 级的压缩提示的格式难以被人类理解,但 LLM 可以很好地进行解释。

实验证明,这种方法在 20 倍的压缩下性能损失仍较小,这不仅能够降低计算成本,还为处理 LLM 中更长的上下文提供了潜在解决方案。
论文题目:
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
论文链接:
https://arxiv.org/abs/2310.05736
Demo 地址:
https://huggingface.co/spaces/microsoft/LLMLingua
代码地址:
https://aka.ms/LLMLingua
为了加速模型推理,有研究在尝试修改 LLM 的参数(如压缩),但在只能通过 API 访问 LLM 的情况下,这些方法可能并不适用,因此需要考虑从提示方面着手解决问题。
之前有工作指出,自然语言本质上是冗余的,并且 LLM 可以有效地从被压缩文本中还原源文本。因此,近期的一些方法将长提示压缩为短提示,旨在通过保留基本信息的同时减少原始提示的长度,来加速模型推理。
比如今年新提出的 Selective-Context 方法,首先使用小型语言模型计算原始提示中每个词汇单元(如句子、短语或 token)的自身信息,然后删除较少信息的内容来压缩提示。然而,它不仅忽视了被压缩内容之间的相互依赖关系,还忽略了目标 LLM 与用于提示压缩的较小语言模型之间的对应关系。
什么是困惑度(perplexity)?
通常指在自然语言处理中,对语言模型性能的一种度量。它衡量了语言模型在给定一段文本后对下一个词预测的不确定性或困惑程度。一般来说,困惑度越低,模型的性能越好,因为它表示模型对下一个词预测的自信程度。
在本文中,困惑度被用作衡量提示信息复杂度的标准。较低困惑度的 token 在语言模型的预测中贡献的不确定性较小,因此可能被认为是相对冗余的信息,在压缩中被删除也不太影响语义信息。
LLMLingua
整体来说,本文所提出的 LLMLingua 框架旨在通过更精细地控制压缩过程,确保在减小提示长度的同时有效保留原始提示信息。模型框架如图 1 所示。
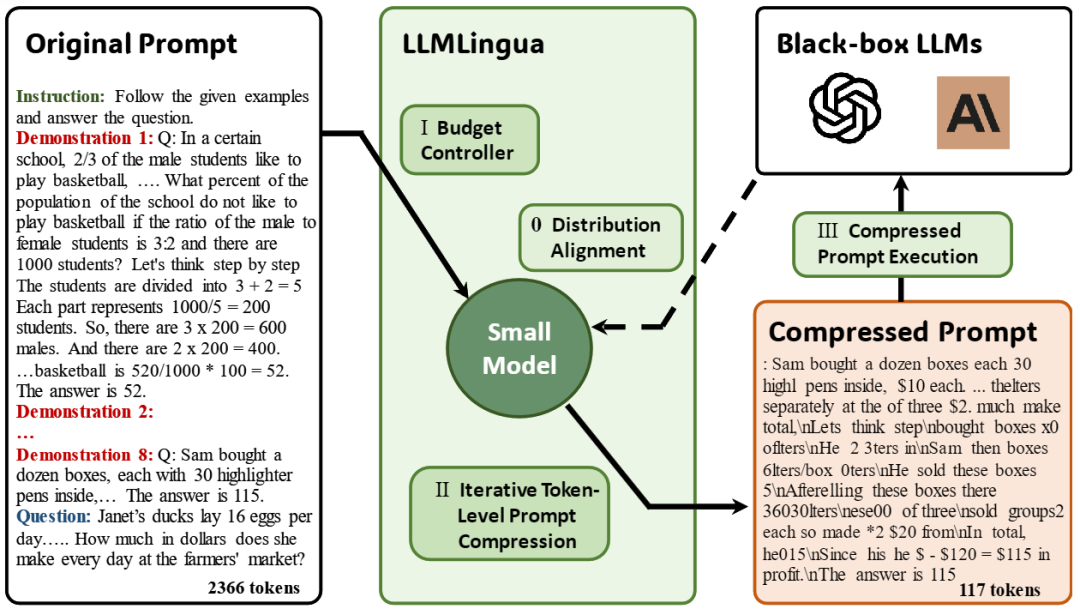
▲图1 LLMLingua 框架
-
压缩比例控制器:其主要作用是动态地为提示中的不同部分分配不同的压缩比例,同时在高度压缩的情况下保持语义的完整性。
-
迭代提示:旨在在进行压缩的同时保留提示中的知识。
-
对齐方法:用于解决小型语言模型与黑盒大型语言模型之间存在的概率分布差距。
压缩比例控制器
该模块用于给提示的不同部分动态地分配不同的压缩比例,从而实现在高度压缩的情况下保持语义完整性,有以下两个主要设计动机:
-
不同部分的影响力差异:提示中的指令和问题对生成的结果有直接影响,因为它们应包含生成下一个答案所需的所有必要信息。相反,如果提示中包含多个示例,传达的信息可能会冗余。因此,该模块根据提示中的不同部分,通过给示例动态分配更小的压缩比例,给指令和问题更大的压缩比例,以更好地实现信息保留。
-
压缩率与语言完整性的平衡:当需要更高压缩率时,使用 token 级的 dropout 可能使压缩后的提示过于简单,从而失去原始提示的重要信息。为了在高度压缩的情况下保持一定程度的语言完整性,该模块引入了句子级的丢弃,特别是在存在多个冗余示例的情况下,还可以执行示例级的控制,以满足压缩的需求。

▲算法1 压缩比例控制器
如算法 1 所示:
-
动态分配压缩比例:针对提示中的不同部分,根据某些标准动态地分配不同的压缩比例。这样,模型可以有选择地保留对语义贡献较大的部分,同时更好地压缩相对较不重要的部分。
-
示例级压缩:在动态分配的压缩比例下,进行粗粒度的示例级压缩。这意味着在高度压缩的情况下,模型仍然可以保持提示的整体语义完整性,而不仅仅是单个 token 的压缩。
迭代 token 级提示压缩(ITPC)
该模块用于在压缩提示的过程中迭代处理每个 token,更细粒度地压缩提示内容,以更准确地保留关键的上下文信息。

▲算法2 ITPC 算法
该算法的步骤可以描述为:
-
将提示分段: 首先,将目标提示分成多个段落或片段。每个段落通常包含不同部分的信息,如指令、演示和问题。
-
计算困惑度: 使用较小的语言模型计算每个段落的困惑度。困惑度反映了模型对段落中 token 序列的预测难度,即上下文的复杂性。
-
迭代压缩: 对每个段落执行迭代的 token 级压缩算法。在每次迭代中,将当前段落的压缩结果与下一段落连接起来,以更准确地估计条件概率。这有助于缓解条件独立性假设的局限性,使得压缩后的提示更接近原始提示。
-
概率估计与过滤: 利用计算到的条件概率估计每个 token 的重要性,并根据设定的阈值进行过滤。这一步旨在保留压缩提示中具有关键信息的 token,同时舍弃不太重要的 token。
分布对齐
该模块用于解决较小语言模型(LM)与黑盒 LLM 之间的概率分布差距,以提升对提示进行压缩的效果。以下是该模块的主要步骤和目标:
-
较小 LM 的优化:从预训练的小型语言模型 开始,通过在 LLM 生成的数据上进行指令微调来优化小型 LM,使其更好地模拟 LLM 的分布。
-
概率分布估计:使用优化后的小型 LM 生成提示的分布。这一步旨在通过小型 LM 更准确地估计原始提示和压缩提示的分布。
-
对齐处理:基于生成的分布,进行对齐处理,使小型 LM 生成的提示分布更加接近 LLM 的提示分布。这有助于缩小两者之间的分布差距,提升压缩质量。
实验
在四个不同领域的数据集上评估对提示压缩的性能。具体而言,评估使用了 GSM8K(推理和上下文学习)、BBH(推理和上下文学习)、ShareGPT(对话理解),以及 Arxiv-March23(摘要)。
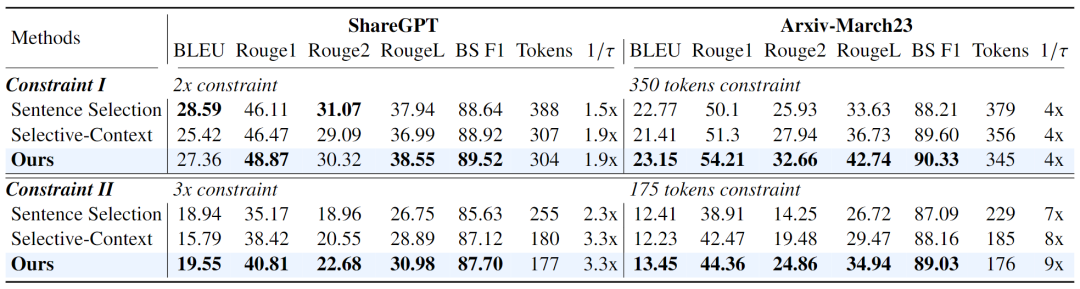
▲表1 不同目标压缩比下对话和摘要任务中的性能比较
实验结果如表 1 和表 2 所示,可以看出,在几乎所有实验中,我们提出的方法始终明显优于先前的方法。
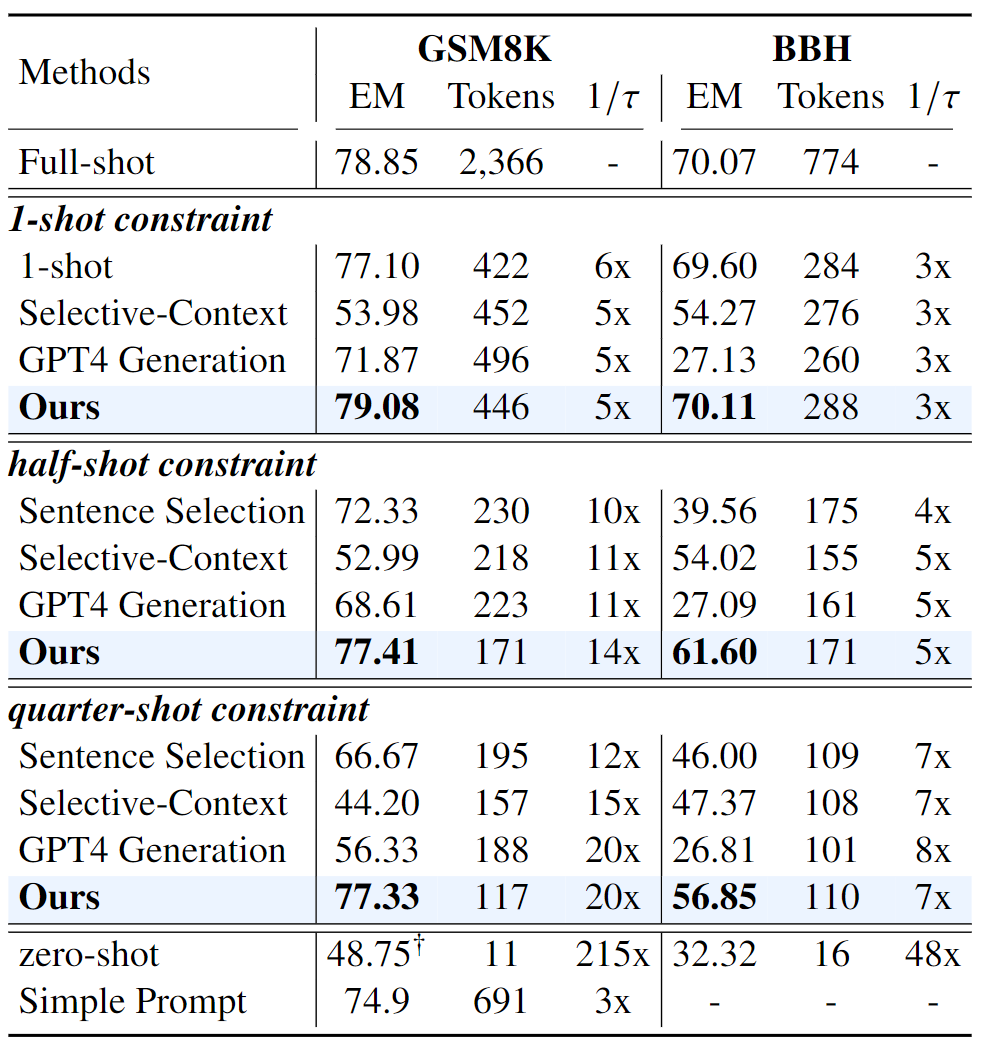
▲表2 在数学推理和上下文学习任务中的性能比较
-
在推理和上下文学习任务(GSM8K 和 BBH)中,本文方法在 1-shot 约束条件下表现略高于 full-shot 方法,同时在高压缩比(5 倍和 3 倍)下效果不错,有效地保留了原始提示的推理信息。在 half-shot 和 quarter-shot 约束下,性能略有下降,但也很不错。
-
在上下文理解任务(ShareGPT 和 Arxiv-March23)中,本文方法实现了 9 倍和 3.3 倍的加速比(acceleration ratios),同时保持高 BERTScore F1,成功地保留了初始提示的语义信息。
在具有一定难度的推理和 ICL 任务上,本文的方法相对于 Selective-Context 方法也有着显著的性能提升。尤其是在 GSM8K 上,也证明了能有效保留推理信息。
消融实验

▲表3 在 1-shot 约束下 GSM8K 数据集上的消融结果
结论
本研究通过从粗粒度到细粒度的策略,提出了一种名为 LLMLingua 的基于小型语言模型困惑度的提示压缩算法,它由三个关键模块组成:压缩比例控制器、迭代 token 级压缩以及对齐。作者在四个数据集上对其进行了大量实验,
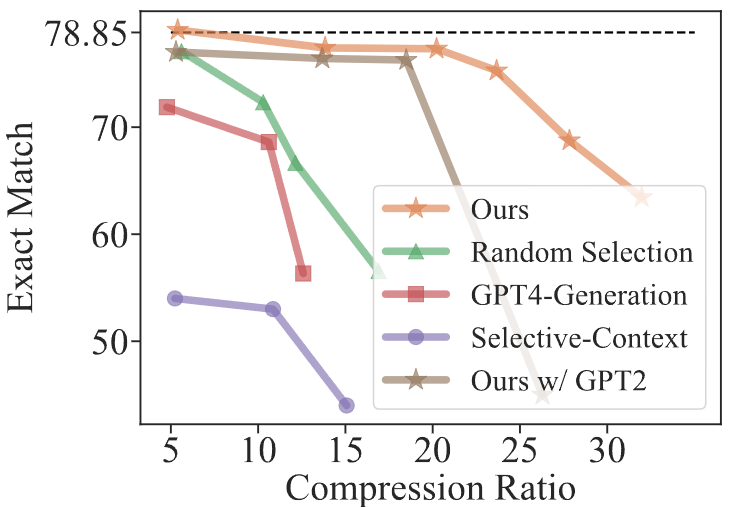
▲图3 在 GSM8K 上不同压缩比()下各种提示压缩方法的性能比较
如图 3 所示,随着压缩比例的提高,尤其是在 25 倍到 30 倍的范围内,所有方法在性能上都会明显下降。但与其他方法相比,本文的方法在导致性能下降时,明显更偏向于更高的压缩比,这可能受提示长度、任务类型和涉及句子数量等多种因素制约。
因此,即使在极端的压缩比例下,该方法仍然能够有效地保持原始提示的信息,这对于在实际应用中研究不同限制和资源约束下的提示至关重要。