大型语言模型(LLM)通过利用庞大的训练语料和强大的计算资源,在众多 NLP 任务中表现卓越。然而,在理解和进行推理方面,这些模型仍显得相对薄弱,仅依靠增加模型的大小无法解决这一问题。
然而,现在广泛研究的思维链(CoT)和自纠正方法仅基于模型对问题的内部理解和观点。在没有外部反馈的情况下,LLM 难以修正其回复,因为模型完全依赖内部表示来生成回复,这使得克服固有的能力限制变得困难。

▲图1 CoT、自纠正和 EoT 的比较
在人类社会中,即使真理只掌握在少数人手中,但通过清晰而有说服力的沟通,也能获得广泛的接受和认可。他人正确的推理可以作为高质量的外部知识,丰富大家对于事物的理解。因此,外部知识的重要性不言而喻,然而获取高质量的外部知识仍是一个极具挑战性的任务。
复旦大学的研究团队提出了思维交流(EoT),该框架实现了在解决问题的过程中跨模型通信。与自纠正方法进行对比,凸显了该模型在整合外部观点方面的独特能力。EoT 促进了思想和思维链在模型间的交流,通过引入丰富的知识来丰富问题解决过程。
论文题目:
CoLLiE: Collaborative Training of Large Language Models in an Efficient Way
论文链接:
https://arxiv.org/abs/2312.01823
背景:什么是 Chain-of-Thought(CoT)
CoT,即“Chain-of-Thought”(思维链),是一种推理链的引导方法。其核心理念是通过生成多个思维链来激发语言模型进行更深入的推理和思考,以提升模型的性能。每个思维链代表了模型在解决问题时可能采用的不同思考路径。在 CoT 方法中,通过引导模型生成一系列中间推理步骤,在获得最终答案之前促使模型进行更深入的推理和思考。
具体而言,CoT 包含两个主要步骤:
-
生成思维链(Chain-of-Thought Generation): 首先,模型根据输入的问题和上下文生成多个可能的思维链。每个思维链都由一系列与问题相关的语句组成,代表了模型在解决问题时的思考过程。
-
选择和生成答案(Answer Selection and Generation): 然后,模型从生成的思维链中选择一条或多条,并基于这些思维链生成最终的答案。这一方法的目的是通过引入多样的推理路径来提高模型的鲁棒性和推理能力。
CoT 是在语言模型中引入多样性和深度推理的方法,有助于模型更全面地理解和回答复杂的问题。
背景:自纠正方法
自纠正方法是指通过利用模型对先前输出的反馈信息,以迭代的方式提高模型生成答案的质量。模型会不断地调整其输出,根据先前的错误或不确定性进行修正,以期望获得更准确、一致的结果。
通常,自纠正方法包括以下步骤:
-
生成初始答案: 模型首先生成对于给定输入问题或任务的初始答案。
-
获取反馈: 通过比较生成的答案与真实标签或其他参考答案,模型获取关于答案的反馈信息。这可以包括确定哪些部分是正确的,哪些部分是错误的,或者哪些方面存在不确定性。
-
调整答案: 模型根据反馈信息调整先前生成的答案,试图更好地匹配预期的正确结果。
-
重复迭代: 上述步骤可能会进行多次迭代,每次都尝试进一步优化答案,直至达到满意的性能水平。
这种方法的目标是通过模型对自身产生的错误进行学习和修正,从而提高其在特定任务或领域中的准确性和鲁棒性。
本文方法:EoT
作者提出的思维交流(Exchange-of-Thought,EoT),通过促进跨模型交流,实现对外部反馈的整合。该方法充分利用了 LLM 的通信能力,鼓励参与模型之间理性和答案的共享,从而建立起一个协同思考和分析的环境。EoT 面临着三个主要挑战:
-
如何确定模型之间通信的适当对应关系?
-
什么条件会使通信终止?
-
如何在通信过程中最小化错误推理对结果的影响?
通信范式
作者提出了四种通信范式,以确定模型之间的适当对应关系。如图 3 所示,有了记忆、报告、中继和辩论的通信范式,分别对应总线、星型、环形和树状网络拓扑。
假设在第 轮交流中,给定一组 LLM ,模型 基于 生成相应的理性 和答案 ,其中 是模型 可以收集推理过程的集合。在第一轮中,使用 CoT 方法生成 。
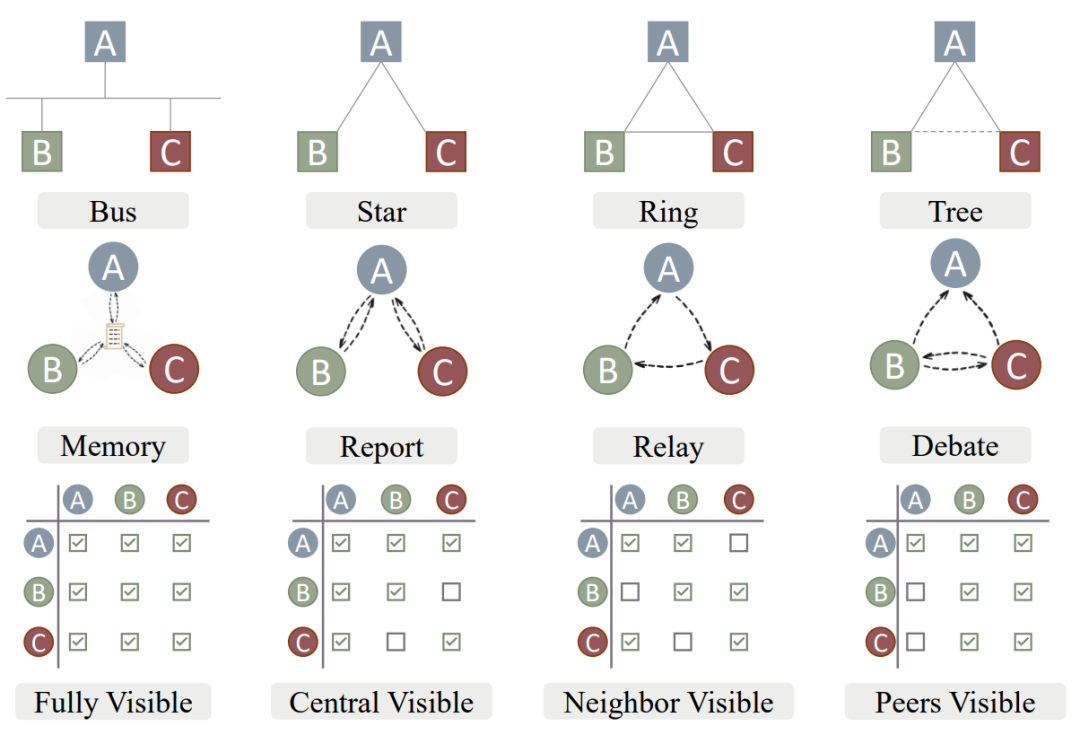
▲图3 通信范式与网络拓扑之间的对应关系
这四种通信范式分别是:
-
记忆(Memory): 采用总线拓扑,其中一个中央节点将信息传递给所有其他节点。在 EoT 中,每个模型在推理过程中生成的信息被集中存储,其他模型可以随时访问。
-
报告(Report): 采用星型拓扑,其中一个中心节点(中心模型)收集所有其他节点的信息。每个模型向中心模型报告其生成的推理和答案,由中心模型进行综合。
-
中继(Relay): 采用环形拓扑,信息通过相邻的节点依次传递。在 EoT 中,模型之间以循环的方式传递推理信息,允许信息在模型之间传递和融合。
-
辩论(Debate): 采用树状拓扑,一个中心节点与多个子节点相连。在 EoT 中,中心模型与其他模型展开辩论,各自提出不同的推理和答案,最终达成共识或者根据多数意见选择答案。
通信量
通信量是通过接收的消息数量来衡量的,假设有 n 个模型参与交流,每个节点将其信息从上一轮传输到下一轮。在不同通信范式下的通信量计算方法如下:
-
记忆范式: 每个节点都接收来自所有其他节点的信息,导致总通信量为 。每个节点都能够获得其他所有节点的信息,但也导致了较高的通信成本。
-
报告范式: 中心节点接收来自 个非中心节点的信息,而每个非中心节点都从中心节点接收信息。每个节点还可以从其上一轮接收信息。总体通信量为 。这种范式下,平均通信量计算为 。
-
中继范式: 每个节点从前一节点接收信息以及自己的上一轮信息,导致通信量为 。信息在模型之间传递,但不像记忆范式那样全局传播。节点之间的通信速度为 。
-
辩论范式: 每对子节点的通信量为 4,而对于父节点为 3。通信速度 的计算涉及到完全二叉树结构中父节点和子节点之间的信息传递。考虑到节点形成一个高度为 的完全二叉树,总通信量为 。
终止条件
利用模型本轮输出和以前轮的答案,作者制定了两个终止通信的标准:一致输出和多数共识。
-
一致输出终止: 当模型 在第 轮的输出与第 轮的输出相同时,终止条件触发。在这种情况下, 将停止接收或发送信息并退出当前通信。这种终止条件基于个体模型在连续轮次中达到一致的输出。
-
多数共识终止: 在辩论几轮后,大型语言模型(LLMs)可能会收敛于共识,表明通过人类反馈进行强化学习调整的 LLM 更有可能达成一致。受到这一发现的启发,EoT 提出了多数规则的终止条件,即一旦大多数 LLM 达成一致,它们就停止相互通信。这种方法充当全局终止条件,与一致输出终止不同,后者作为个体模型基础上的停止标准。
这两个终止条件有助于确保在通信过程中达到合适的结束点,以提高效率并避免不必要的通信。
置信度评估
当人们对自己的答案感到自信时,他们犯错的可能性较小,而当他们对自己的答案感到不确定时,他们更容易受到他人意见的影响。在大模型中亦然,随着生成结果变得更加矛盾,答案正确的可能性降低。因此,如果模型在通信过程中的答案经常变化,那么这些答案很可能是不正确的。
为了评估模型的置信度,作者提出了一种基于回复变化的方法,有助于接收信息的一方验证其可靠性,从而保护问题解决过程免受错误信息的干扰。在通信的每一轮中,模型生成一组答案。计算最常出现的答案的数量 ,得到了模型 在本轮的置信度水平 。
如图 4 所示,这种方法通过观察模型在多轮通信中生成的答案的一致性,为模型的每一轮输出提供了一个置信水平,从而使接收信息的一方能够更好地了解模型对问题的把握程度。
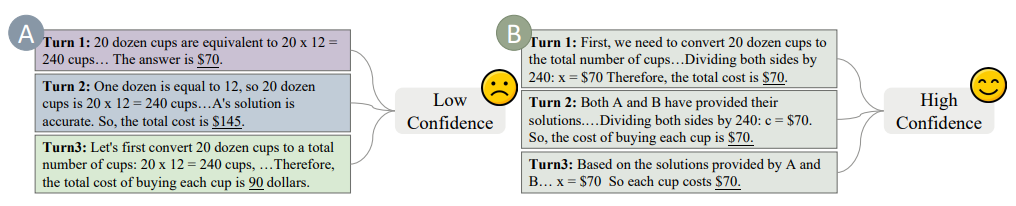
▲图4 高置信度模型和低置信度模型之间的示例对比
实验
实验评估了 EoT 在数学推理、常识推理和符号推理三个复杂推理任务中的性能。
性能比较
如表 1 所示,在数学推理任务中,EoT 的四种通信范式相较于 baseline 都显著改进了性能。这突显了 EoT 通过引入外部反馈弥补彼此的不足,来提升模型能力、解决固有缺陷的潜力。
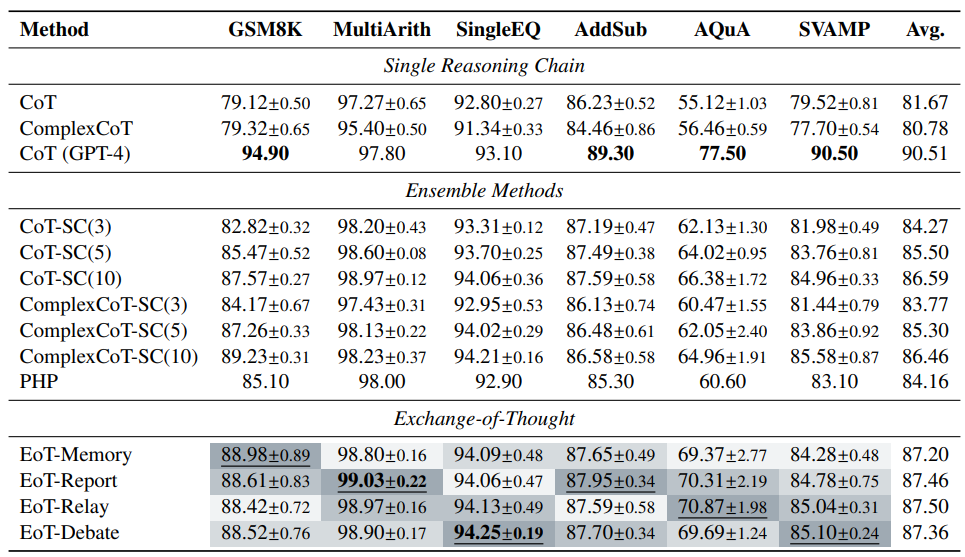
▲表1 EoT 在数学推理任务中的性能比较
通过图 5a 和 5b 的比较,EoT 在常识推理任务上相较于 CoT 和 CoT-SC 方法有明显的性能优势。
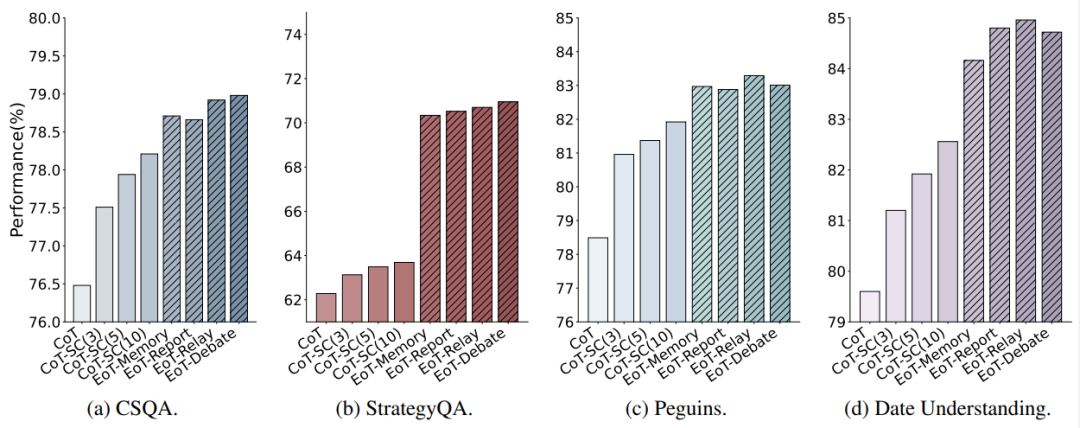
▲图5 EoT 在常识推理和符号推理任务中的比较
根据图 5c 和 5d 的比较结果,EoT 在符号推理任务中相较于 CoT 和 CoT-SC 方法有着更好的性能表现。
进一步讨论
根据表 1 的比较,我们观察到不同的通信范式具有各自的优势,这表明不同的通信范式适用于不同的场景。
根据图 6 终止条件的分析结果,缺乏集体协商机制的一致输出终止导致个体模型可能因为退化而过早退出。因此,在涉及多模型通信的情境中,多数共识终止性能提升更高。
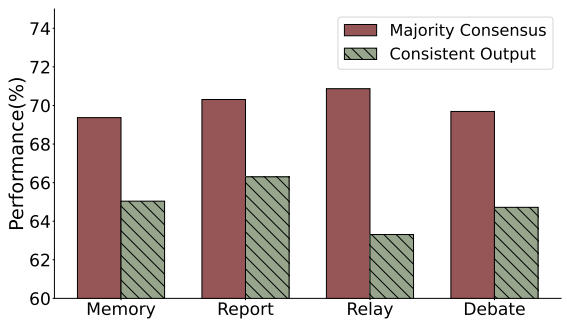
▲图6 在 AQuA 上一致输出终止和多数共识终止的比较
根据图 7 的消融实验,置信度评估的引入使模型在通信过程中能够考虑到其他模型的先验置信度,从而有助于在较早的阶段做出更明智的决策,有效减轻了错误思维链的干扰。
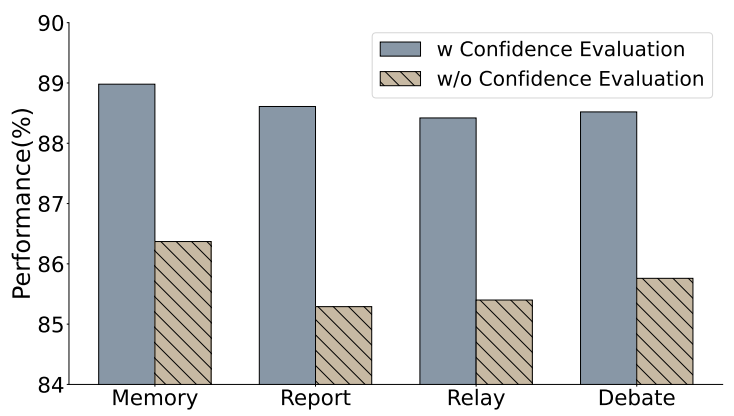
▲图7 在 GSM8K 数据集上采用置信度评估对准确性的影响
在图 8 中,对于大多数样本,模型能够在 3 轮通信内就答案达成共识。而 EoT 使模型能够在难以达成共识的问题上进行更多的交流。因此,在部分难题中,可能需要超过 5 轮通信才能达成共识。
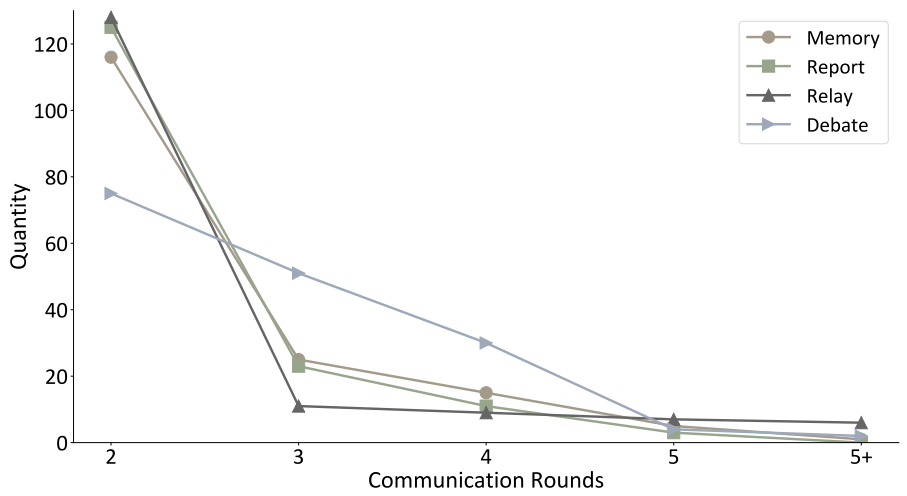
▲图8 在 SVAMP 上达到终止条件所需的通信轮次
根据图 9 的实验结果,可以看到通过促进模型之间的外部见解交流,让 EoT 有效提升模型性能,展现了其具有成本效益的优势。
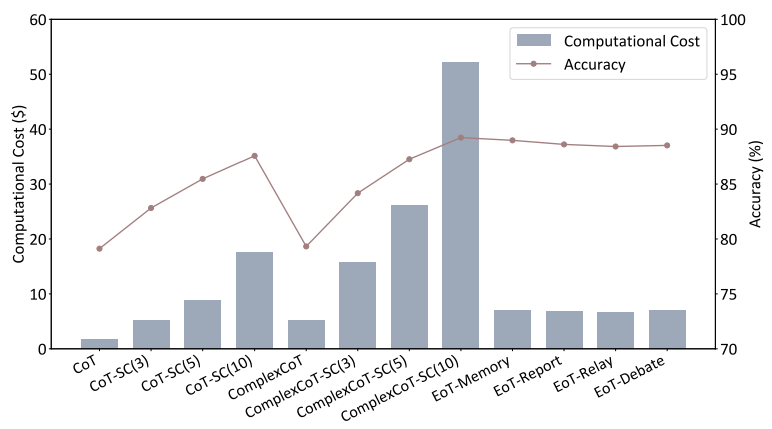
▲图9 在 GSM8K 数据集中的性能和相关成本
如图 10 所示,表明 EoT 在不同的 LLM 上都能够取得显著的性能提升。
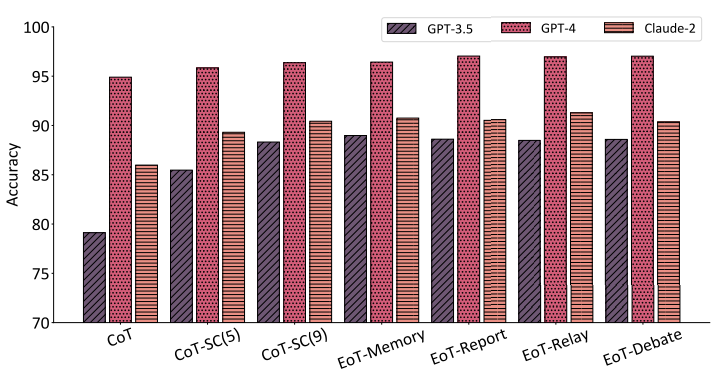
▲图10 在 GSM8K 上使用不同 LLM 作为基础的实验比较
通过图 11 探讨了不同 LLM 在不同节点位置对性能的影响。强调了整合更优越的模型和模型多样性能够有效地提高 EoT 的效果。
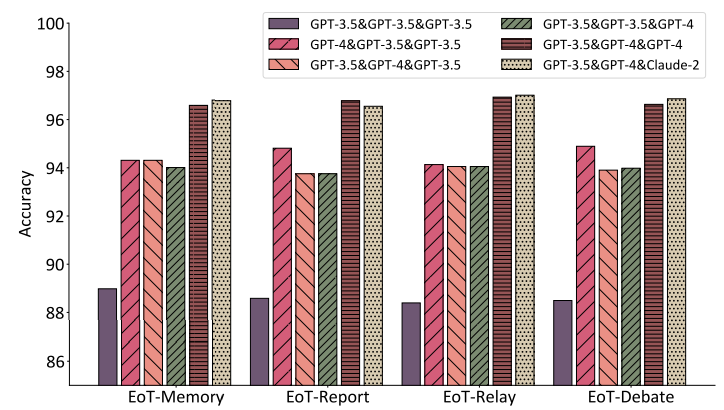
▲图11 不同 LLM 在 GSM8K 数据集上对准确性的影响
总结
在 CoT 的基础上,作者引入思维交流(EoT)框架,实现了不同模型之间的跨模型交流,从而使推理性能得到显著提升。
EoT的四种通信范式不仅在各种推理任务中展现出卓越的性能,而且相较于其他方法更节约计算成本。通过对外部反馈的整合,EoT 提供了一种新颖而高效的方式,使模型在解决复杂问题时能够更全面、深入地进行推理。
实验证明,EoT 在常识推理和符号推理任务上表现出更好的性能,充分发挥了多模型协作的潜力。我们的研究也强调了模型多样性的重要性,通过整合不同模型的优势,取得了比单一模型更出色的效果。