原型模式
原型模式(Prototype模式)是指:用原型实例指定创建对象的种类,并且通过拷贝这些原型,创建新的对象。
原型模式是一种创建型设计模式,允许一个对象再创建另外一个可定制的对象,无需知道如何创建的细节。
工作原理是:通过将一个原型对象传给那个要发动创建的对象,这个要发动创建的对象通过请求原型对象拷贝它们自己来实施创建,即对象.clone
克隆羊问题
现有一只羊,姓名:tom,年龄:1,颜色:白色。克隆5只属性完全相同的羊
传统方式实例 这里使用lombok简化代码
优点: 好理解,无脑操作,啪啪啪。
缺点:
在创建新对象时,总是需要重新获取原始对象的属性,如果创建的对象属性比较多时就贼麻烦。
总是重新初始化对象,而不是动态获取对象运行时的状态,不灵活。
改进思路:
Java中Object类是所有类的根类,Object类提供了一个clone()方法,该方法可以将一个Java对象复制一份,但是需要实现clone的Java类必须实现一个接口Cloneable,改接口表示该类能够复制且具有复制的能力,即原型模式。
/**
* @author LionLi
*/
@Data
public class Sheep {
private String name;
private int age;
private String color;
public Sheep(String name, int age, String color) {
this.name = name;
this.age = age;
this.color = color;
}
}
/**
* @author LionLi
*/
public class Test {
public static void main(String[] args) {
//传统的方法
Sheep sheep1 = new Sheep("tom", 1, "白色");
Sheep sheep2 = new Sheep(sheep1.getName(), sheep1.getAge(), sheep1.getColor());
Sheep sheep3 = new Sheep(sheep1.getName(), sheep1.getAge(), sheep1.getColor());
Sheep sheep4 = new Sheep(sheep1.getName(), sheep1.getAge(), sheep1.getColor());
Sheep sheep5 = new Sheep(sheep1.getName(), sheep1.getAge(), sheep1.getColor());
System.out.println("sheep1:" + sheep1);
System.out.println("sheep2:" + sheep2);
System.out.println("sheep3:" + sheep3);
System.out.println("sheep4:" + sheep4);
System.out.println("sheep5:" + sheep5);
}
}
浅拷贝与深拷贝
浅拷贝
对于数据类型是基本数据类型的成员变量,浅拷贝会直接进行值传递,也就是将该属性值复制一份给新的对象。
对于数据类型是引用数据类型的成员变量,比如说成员变量是某个数组、某个类的对象等,那么浅拷贝会进行引用传递,也就是只是将该成员变量的引用值(内存地址)复制一份给新的对象。
因为实际上两个对象的该成员变量都指向同一个实例。在这种情况下,在一个对象中修改该成员变量会影响到另一个对象的该成员变量值。
浅拷贝是使用默认的clone()方法来实现的,即sheep = super.clone();
深拷贝
复制对象的所有基本数据类型的成员变量值,为所有引用数据类型的成员变量申请存储空间,并复制每个引用数据类型成员变量所引用的对象,直到该对象可达的所有对象。
也就是说,对象进行深拷贝要对整个对象(包括对象的引用类型)进行拷贝
深拷贝实现方式1:重写clone方法来实现深拷贝
深拷贝实现方式2:通过对象序列化实现深拷贝(推荐)
原型模式(浅拷贝)
/**
* 注意使用原型模式实现clone克隆方法必须实现 Cloneable 接口不然会报错
*
* @author LionLi
*/
@Data
public class Sheep implements Cloneable {
private String name;
private Integer age;
private String color;
public Sheep(String name, int age, String color) {
this.name = name;
this.age = age;
this.color = color;
}
@Override
protected Sheep clone() {
Sheep obj = null;
try {
obj = (Sheep) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return obj;
}
}
/**
* @author LionLi
*/
public class Test {
public static void main(String[] args) {
// 原型浅克隆
Sheep sheep1 = new Sheep("tom", 1, "白色");
Sheep sheep2 = sheep1.clone();
Sheep sheep3 = sheep1.clone();
Sheep sheep4 = sheep1.clone();
Sheep sheep5 = sheep1.clone();
System.out.println(sheep1 == sheep2);
System.out.println(sheep2 == sheep3);
System.out.println(sheep3 == sheep4);
System.out.println(sheep4 == sheep5);
System.out.println(sheep5 == sheep1);
}
}
运行结果 五个对象内存地址全都不一样 克隆成功
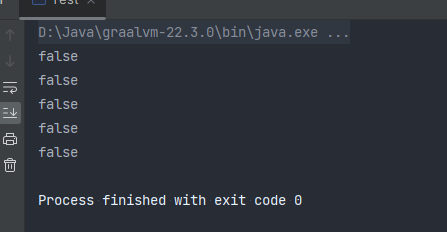
浅拷贝存在的问题
实体类中的对象 例如 Object List Map 等均为引用传递 浅拷贝是无法处理引用传递对象的
我们在Sheep中增加一个List对象 演示问题所在
/**
* 注意使用原型模式实现clone克隆方法必须实现 Cloneable 接口不然会报错
*
* @author LionLi
*/
@Data
public class Sheep implements Cloneable {
private String name;
private Integer age;
private String color;
private List<String> strList;
public Sheep(String name, int age, String color, List<String> strList) {
this.name = name;
this.age = age;
this.color = color;
this.strList = strList;
}
@Override
protected Sheep clone() {
Sheep obj = null;
try {
obj = (Sheep) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return obj;
}
}
/**
* @author LionLi
*/
public class Test {
public static void main(String[] args) {
// 原型浅克隆
List<String> list = new ArrayList<>();
list.add("测试1");
list.add("测试2");
Sheep sheep1 = new Sheep("tom", 1, "白色", list);
Sheep sheep2 = sheep1.clone();
System.out.println(sheep1 == sheep2);
System.out.println(sheep1.getStrList() == sheep2.getStrList());
}
}
测试结论 对于引用对象List的内存地址是想同的 克隆失败
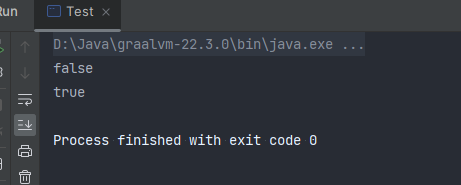
深拷贝 方法一 重写clone方法
弊端: 编码复杂 存在硬编码 不利于扩展 改动较大
@Override
protected Sheep clone() {
Sheep obj = null;
try {
obj = (Sheep) super.clone();
// 这里我们重新创建一个 List 对象 将所有数据 copy 到新对象内
obj.setStrList(new ArrayList<>(strList));
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return obj;
}
重新测试 发现引用对象List也克隆成功了
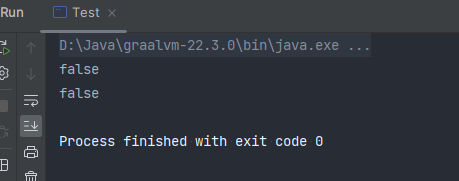
深拷贝 方法二 通过序列化/反序列化实现
首先 使用序列化需要实现JDK的序列化接口 Serializable 我们对实体类进行改造
这里我们讲述使用JDK自带方式进行序列化 也可以使用JSON工具进行序列化这里不多赘述
import java.io.Serializable;
import java.util.List;
/**
* @author LionLi
*/
@Data
public class Sheep implements Serializable {
private String name;
private Integer age;
private String color;
private List<String> strList;
public Sheep(String name, int age, String color, List<String> strList) {
this.name = name;
this.age = age;
this.color = color;
this.strList = strList;
}
}
然后对实体类增加serializableClone序列化克隆方法
protected Sheep serializableClone() {
// try-resources 写法 自动关闭流
try (
// 字节输出流
ByteArrayOutputStream bos = new ByteArrayOutputStream();
// 对象输出流
ObjectOutputStream oos = new ObjectOutputStream(bos)
) {
// 将当前对象序列化为二进制输出到对象流内
oos.writeObject(this);
try (
// 字节输入流
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
// 对象输入流
ObjectInputStream ois = new ObjectInputStream(bis)
) {
// 从对象流读取二进制反序列化为对象
return (Sheep) ois.readObject();
}
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
测试成功 Sheep对象与List对象均为不相等
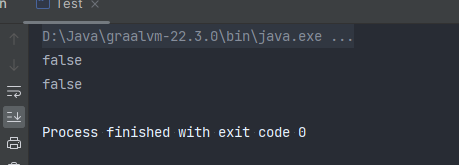
原型模式的注意事项和细节
- 创建新对象比较复杂是,可以利用原型模式简化对象的创建过程,同时也能提高效率
- 不用重新初始化对象,而是动态地获得对象运行时的状态
- 如果原始对象发生变化,其它克隆对象也会发生相应的变化,无需修改代码
- 在实现深克隆时可能需要比较复杂的代码
- 缺点:需要为每一个类配备一个克隆方法,这对全新的类来说不是很难。但对已有的类进行改造时,需要修改其源代码,违背了开闭原则(OCP)。
Spring中原型模式应用
在 Spring 中原型 bean 的创建,就是使用得原型设计模式
// @Scope("singleton") // 单例模式 默认单例
@Scope("prototype") // 原型模式 每次注入都会创建一个新的
@Bean()
public Object obj() {
return new Object();
}
找到 AbstractBeanFactory 这个是 BeanFactory Bean工厂的抽象工厂,我们找到 doGetBean 方法 这个是所有getBean的最终执行方法
不了解 BeanFactory 的请参考另一篇文章 Spring 的工厂模式 BeanFactory 是什么源码刨析

往下翻我们找到下方有个判断
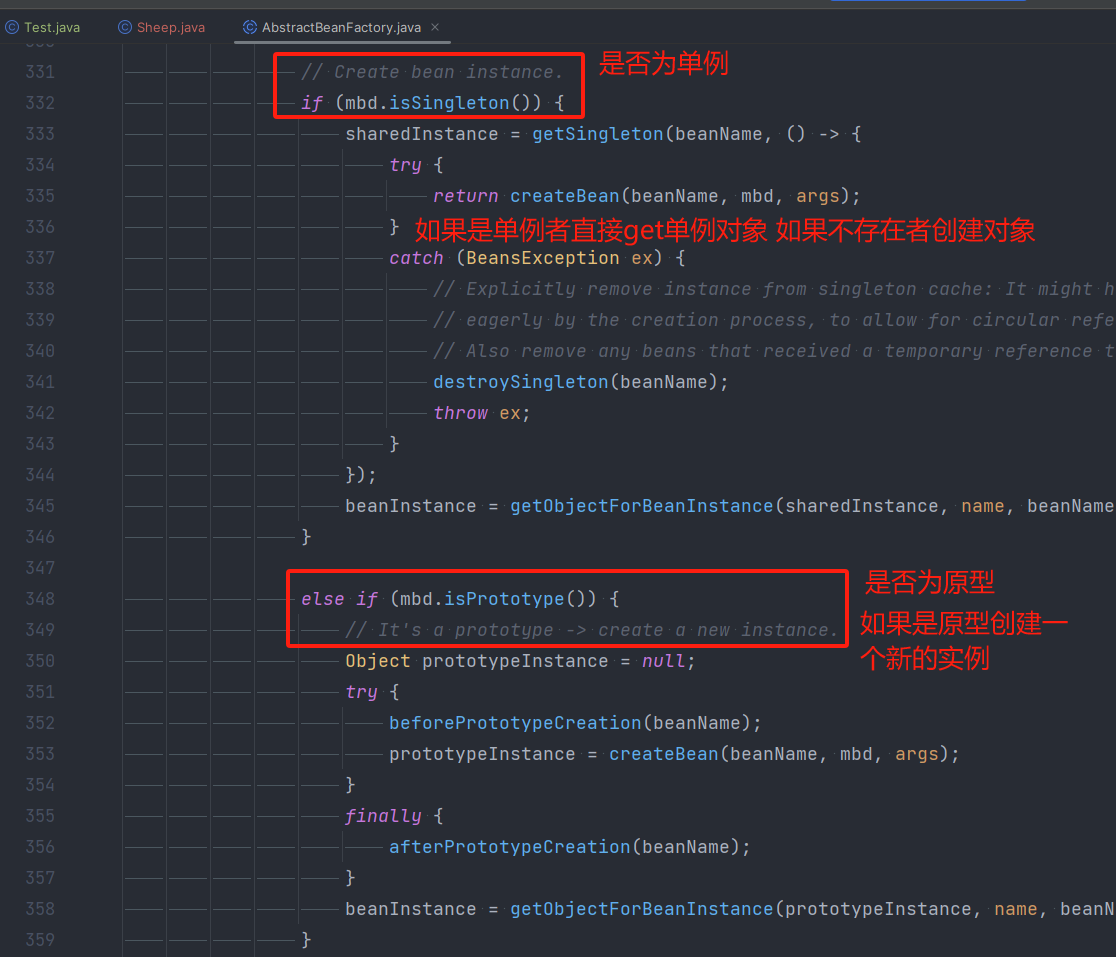
然后我们进入到 createBean 方法实现
找到 AbstractAutowireCapableBeanFactory 此类为 AbstractBeanFactory 的下层抽象工厂实现 用于在执行 @Autowire 自动注入时查找或创建bean实例
我们找到 doCreateBean 方法 此方法是所有 createBean 方法的最终执行方法

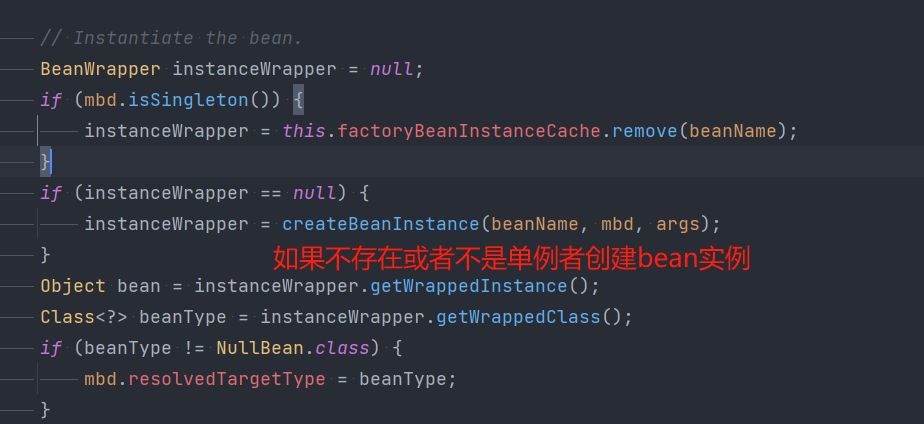
进入 createBeanInstance 创建bean实例方法
找到最后两行查看逻辑
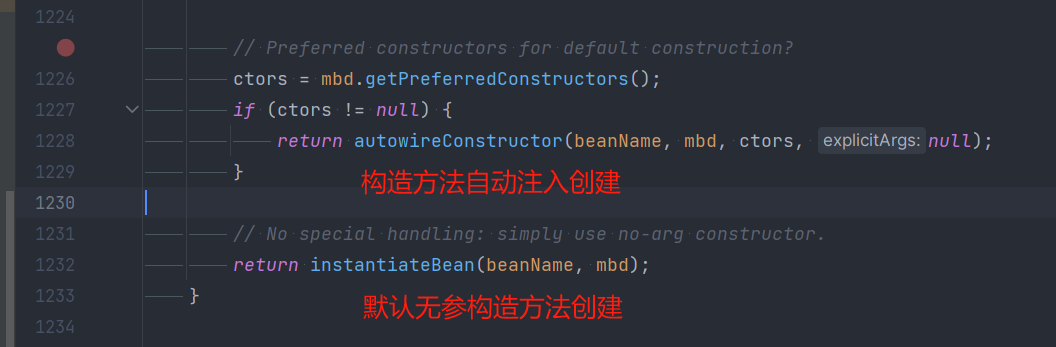
文章内容参考
Java设计模式——原型模式(实例)