CBO优化
CBO是指Cost based Optimizer,即基于计算成本的优化。
在Hive中,计算成本模型考虑到了:数据的行数、CPU、本地IO、HDFS IO、网络IO等方面。Hive会计算同一SQL语句的不同执行计划的计算成本,并选出成本最低的执行计划。目前CBO在hive的MR引擎下主要用于join的优化,例如多表join的join顺序。
关闭CBO优化:
根据执行计划,可以看出,三张表的join顺序如下:
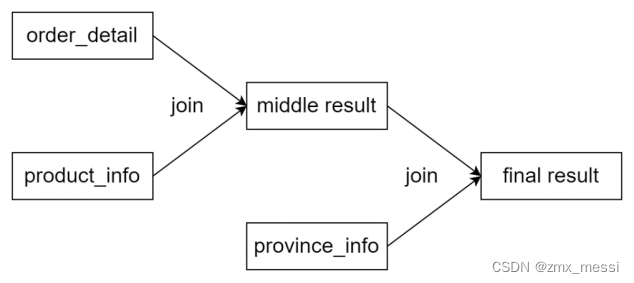
开启CBO优化
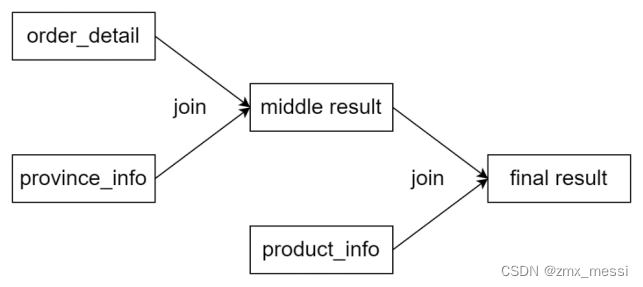
根据上述案例可以看出,CBO优化对于执行计划中join顺序是有影响的,其之所以会将province_info的join顺序提前,是因为province info的数据量较小,将其提前,会有更大的概率使得中间结果的数据量变小,从而使整个计算任务的数据量减小,也就是使计算成本变小。
Map端并行度
Map端的并行度,也就是Map的个数。是由输入文件的切片数决定的。一般情况下,Map端的并行度无需手动调整。
查询的表中存在大量小文件情况下:
按照Hadoop默认的切片策略,一个小文件会单独启动一个map task负责计算。若查询的表中存在大量小文件,则会启动大量map task,造成计算资源的浪费。这种情况下,可以使用Hive提供的CombineHiveInputFormat,多个小文件合并为一个切片,从而控制map task个数。
Reduce端并行度
Reduce端的并行度,也就是Reduce个数。相对来说,更需要关注。Reduce端的并行度,可由用户自己指定,也可由Hive自行根据该MR Job输入的文件大小进行估算。Hive自行估算Reduce并行度时,是以整个MR Job输入的文件大小作为依据的。因此,在某些情况下其估计的并行度很可能并不准确,此时就需要用户根据实际情况来指定Reduce并行度了。
小文件合并
小文件合并优化,分为两设置以下参数:个方面,分别是Map端输入的小文件合并,和Reduce端输出的小文件合并。
合并Map端输入的小文件,是指将多个小文件划分到一个切片中,进而由一个Map Task去处理。目的是防止为单个小文件启动一个Map Task,浪费计算资源。
相关参数为:
--可将多个小文件切片,合并为一个切片,进而由一个map任务处理
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; 合并Reduce端输出的小文件,是指将多个小文件合并成大文件。目的是减少HDFS小文件数量。其原理是根据计算任务输出文件的平均大小进行判断,若符合条件,则单独启动一个额外的任务进行合并。可设置以下参数:
--开启合并map reduce任务输出的小文件
set hive.merge.mapredfiles=true;
--合并后的文件大小
set hive.merge.size.per.task=256000000;
--触发小文件合并任务的阈值,若某计算任务输出的文件平均大小低于该值,则触发合并
set hive.merge.smallfiles.avgsize=16000000;