文章目录
- 变量
- 定义变量的几种方式
- 1)无引号
- 2)单引号
- 3)双引号
- 4)反引号
- export定义变量
- 变量的提取、修改与删除
- 1)变量的提取
- 2)变量的修改
- 3)变量的删除
- 特殊变量
- 1)位置参数
- 2)${#}获取传入参数的个数
- 3)\${$}获取当前进程ID
- 4)${*}和\${@}接收所有参数
- 5)${?}获取上一条命令执行结果
- 6)$()获取命令
- Shell脚本的两种执行方式
- 1)添加执行权限运行
- 2)无需执行权限,以解释器运行
- 1.bash、source和 . 运行的区别
- 2.什么是shebang
变量
其他编程语言中,例如C语言变量是具有多种类型的:整型、浮点型、字符型、逻辑类型等等
但是shell中的变量
一切皆为字符串
定义变量的几种方式
shell为变量赋值时,=左右两边不能有空格,例如a=1表示赋值关系,如果写成a = 1则表示等量关系测试
1)无引号
- 解析特殊符号
- 无法解析特殊命令
- 无法输入空格
age=18
2)单引号
- 不解析一切特殊符号、命令
- 可以输入空格
- 所见即所得
name='echo zhang san'
3)双引号
- 解析特殊符号
- 无法解析特殊命令
- 可以输入空格
phone_num="123 456"
4)反引号
- 解析特殊符号
- 解析特殊命令
- 可以输入空格
a='echo hello world!'
b=`${a}`
echo ${b}
上述代码最终会输出 hello world!,过程分为2步:
- 解析了特殊符号${a},把a中存储的字符串拿出来
- 发现字符串是特殊命令,再对该字符串进行解析,最终把打印的结果赋给b
export定义变量
如果变量a是在父bash中创建的,当进入子bash时,将无法访问变量a的内容
用export创建变量可以解决上述问题
export创建变量方法如下:
export a=1
变量的提取、修改与删除
1)变量的提取
变量提取的格式如下:
name="变量名"
${name} #推荐使用该方法
$name
上述方法中,为了减少bug并且增加代码的可读性,推荐使用${}的方法。
2)变量的修改
直接对变量重新赋值即可完成变量的修改
name="zhangsan"
name="lishi"
3)变量的删除
利用unset命令可以指删除指定变量,unset支持一次删除多个变量;如果有一系列特征相同的的变量,可以通过set | grep对变量进行查找,再根据查找的结果进行删除
name1="zhangsan"
name2="lisi"
name3="wangwu"
set | grep "^name"
其中:set表示查找所有变量,包括系统变量,|表示管道,gerp “^name”表示找到以name开头的变量
运行结果如下:
name1=zhangsan
name2=lisi
name3=wangwu
然后即可通过unset对变量进行删除
unset name1 name2 name3
特殊变量
特殊变量也遵循变量提取的基本语法,即${};为了方便书写,下列代码采取简写。
1)位置参数
在linux中,执行一条命令或脚本时,后面可以输入多个参数,这些参数统称位置参数;其中${0}表示执行的命令或脚本,${1}表示第一个位置参数,${2}表示第二个位置参数,依次往后。
编写一个脚本pos_param.sh
#!/bin/bash
echo "执行的脚本或命令是${0}"
echo "第一个位置参数是${1}"
echo "第二个位置参数是${2}"
echo "第三个位置参数是${3}"
echo "第四个位置参数是${4}"
echo "第五个位置参数是${5}"
运行脚本
bash pos_param.sh 1111 2222 3333 4444 5555
结果如下
执行的脚本或命令是pos_param.sh
第一个位置参数是1111
第二个位置参数是2222
第三个位置参数是3333
第四个位置参数是4444
第五个位置参数是5555
注:当位置参数的个数小于10时,{}可以省略,例:$0,$1,$2等;而10以上的位置参数则必须以${}的形式,例:${10}、${11}等
位置参数练习:创建新用户
cat > makeuser.sh << "EOF"
#!bin/bash
useradd ${1}
echo "${2}" | passwd --stdin ${1}
EOF
bash makeuser.sh lisi 1234
注:该方式修改用户密码的方式不适用于ubuntu
运行成果,会报如下提示:
Changing password for user lisi.
passwd: all authentication tokens updated successfully.
2)${#}获取传入参数的个数
echo 'echo "共传入$#个参数"' >> pos_param.sh
bash pos_param.sh 1111 2222 3333 4444 5555
在1)的基础上,继续在脚本中添加如下命令,再次运行1)中命令执行脚本,会打印如下内容:
共传入5个参数
显然,$#会获取传入脚本中所有参数的个数。
3)${$}获取当前进程ID
继续添加如下命令:
echo 'echo "当前进程ID是$$"' >> pos_param.sh
bash pos_param.sh 1111 2222 3333 4444 5555
打印内容下:
当前进程ID是14109
14109则是pos_param.sh的进程ID号
4)${*}和${@}接收所有参数
${*}和${@}均为接收所有参数,但二者又略有不同
执行下列代码:
cat >> pos_param.sh << "EOF"
echo "\$*接收的参数为:$*"
echo "\$@接收的参数为:$@"
echo "用for循环打印\$*接收的参数为:"
count=0;
for a in "$*"
do
let count++
echo "第${count}个位置参数是:${a}"
done
echo "用for循环打印\$@接收的参数为:"
count=0;
for b in "$@"
do
let count++
echo "第${count}个位置参数是:${b}"
done
EOF
bash pos_param.sh 111 222 333
运行结果如下:
$*接收的参数为:111 222 333
$@接收的参数为:111 222 333
用for循环打印$*接收的参数为:
第1个位置参数是:111 222 333
用for循环打印$@接收的参数为:
第1个位置参数是:111
第2个位置参数是:222
第3个位置参数是:333
显然:二者都能够接收传入的参数
- ${*}是将所有参数作为一个字符串进行整体存储,无法分开
- ${@}是将所有参数进行分开存储
5)${?}获取上一条命令执行结果
在平时写代码中,例如C语言:我们常常利用返回值来判断某个函数、程序的运行结果是否正确,shell脚本中也是如此
shell中如果返回值为0则表示运行正确,非0则表示出错
例如:
[wjj@why1472587 ~]$ ls 777
ls: cannot access 777: No such file or directory
[wjj@why1472587 ~]$ echo $?
2
[wjj@why1472587 ~]$ ls
study
[wjj@why1472587 ~]$ echo $?
0
6)$()获取命令
$()中()中的内容不再视为变量,而是作为命令进行处理。
例如:通过whoami命令可以查看当前用户,可以有如下用法:
echo "当前用户:$(whoami)"
Shell脚本的两种执行方式
首先编写一个打印Hello World!的脚本
cat > test1.sh << 'EOF'
#!/bin/bash
echo "Hello World!"
EOF
1)添加执行权限运行
chmod u+x test1.sh
./test1.sh
2)无需执行权限,以解释器运行
- 以
bash运行 - 以
source运行 - 以
.运行(需要文件开头有shebang)
#1
bash test1.sh
#2
source test1.sh
#3
. tesh1.sh #文件开头需要有shebang
1.bash、source和 . 运行的区别
- 使用
source和.运行时,是在当前bash环境中运行的 - 使用
bash运行时,会额外创建一个子bash环境
以pstree -p命令可打开当前linux系统运行的进程,并且查看PID进程号
1)以source和.运行:

2)以bash运行:
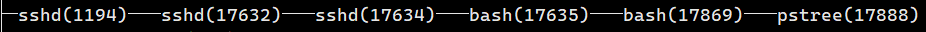
脚本运行结束后,会退出当前的子bash环境
2.什么是shebang
shebang是一个文本行,放在shell脚本的第一行,告诉计算机当前脚本采用什么解释器运行
#!/bin/bash
其中,#!表示这是一个shebang,/bin/bash为解释器路径。
上述shebang表示该脚本用bash解释器运行;如果是python脚本,则需要改为:
#!/bin/python
shell和python作为解释型语言可以通过加入shebang的方式,直接用解释器运行脚本;而其他编译型语言,例如:C/C++、Java等需要先编译才能运行,并且需要安装编译时所需要的环境。
如果脚本第一行中没有声明shebang,那么系统会默认以当前bash环境运行脚本。