简介:
今天开启深度学习另一板块。就是计算机视觉方向,这里主要讨论图像分类任务–垃圾分类系统。其实这个项目早在19年的时候,我就写好了一个版本了。之前使用的是python搭建深度学习网络,然后前后端交互的采用的是java spring MVC来写的。之前感觉还挺好的,但是使用起来还比较困难的。不光光需要有python的基础,同时还需要有一定的java的基础。尤其是搭建java的环境,还是很烦的。最近刚好有空,就给这个项目拿了过来优化了一下,本次优化主要涉及前后端界面交互的优化,另外一条就是在模型的识别性能上的优化,提高模型的识别速度。
展示:
下面是项目的初始化界面:

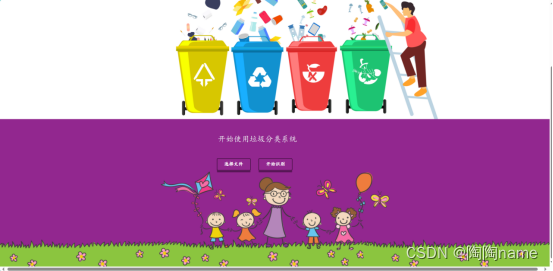
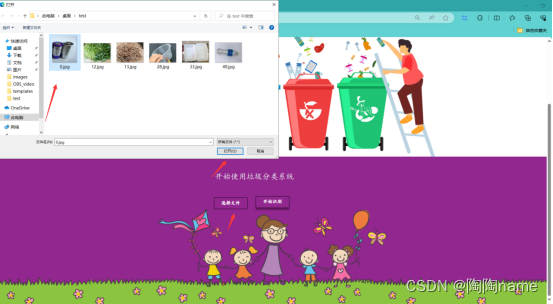
使用本系统的话也是比较简单的,点击选择文件按钮选择需要识别的图片数据。然后再点击开始识别就可以识别了
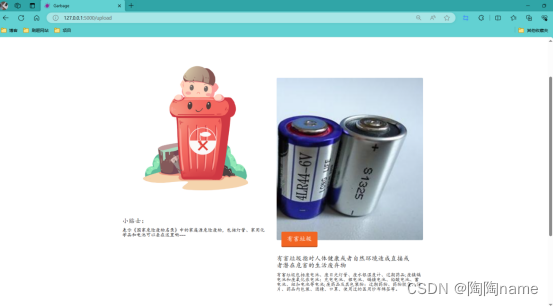
识别结果如下:
实际的使用请看下面的视频:
深度学习项目实战:垃圾分类系统
项目实现思路:
项目主要分为两块,第一块是深度学习模块,另一块呢就是系统的使用界面了。
1、深度学习模块
先说第一个模块,也就是深度学习模块,这块的主体呢其实就是深度学习的网络的搭建以及模型的训练,还有就是模型的使用了。
深度学习网络的我主要使用的是ResNet的网络结构,使用这个网络结构来实现四分类的垃圾分类的任务肯定是可以的。同时呢在训练模型的时候,我这里又使用了一些调参的手法–迁移学习。为什么要使用迁移学习呢?由于ResNet在图像任务上表现的是比较出色的,同时我们的任务也是图像分类,所以呢是可以使用ResNet来进行迁移学习的。
下面是相关代码:
import torch
from torch import nn
from torch.nn import functional as F
class ResBlk(nn.Module):
def __init__(self, ch_in, ch_out, stride=1):
super(ResBlk, self).__init__()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out != ch_in:
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out = self.extra(x) + out
out = F.relu(out)
return out
class ResNet18(nn.Module):
def __init__(self, num_class):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(16)
)
self.blk1 = ResBlk(16, 32, stride=3)
self.blk2 = ResBlk(32, 64, stride=3)
self.blk3 = ResBlk(64, 128, stride=2)
self.blk4 = ResBlk(128, 256, stride=2)
self.outlayer = nn.Linear(256*3*3, num_class)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
# print(x.shape)
x = x.view(x.size(0), -1)
x = self.outlayer(x)
return x
def main():
blk = ResBlk(64, 128)
tmp = torch.randn(2, 64, 224, 224)
out = blk(tmp)
print('block:', out.shape)
model = ResNet18(5)
tmp = torch.randn(2, 3, 224, 224)
out = model(tmp)
print('resnet:', out.shape)
p = sum(map(lambda p:p.numel(), model.parameters()))
print('parameters size:', p)
if __name__ == '__main__':
main()
下面是迁移学习的主要代码:
trained_model=resnet18(pretrained=True)
model = nn.Sequential(*list(trained_model.children())[:-1],
Flatten(),
nn.Linear(512,4)
).to(device)
这部分代码将预训练模型的所有层(除了最后一层)复制到新模型中。Flatten()是将最后一层的输出展平,以便可以输入到全连接层(nn.Linear(512,4))。nn.Linear(512,4)是一个全连接层,有512个输入节点和4个输出节点,对应于任务中的类别数。
最后,.to(device)将模型移动到指定的设备上(例如GPU或CPU)。如果你没有指定设备,那么默认会使用CPU。
之后呢设置batchsize、learning rate、优化器就可以进行模型的训练了
参数设置如下:
batchsz = 64
lr = 1e-4
epochs = 5
2、使用界面
接下来呢,就是关于使用界面的实现思路介绍了。使用界面就是为了方便对模型使用不是很了解的小伙伴使用的。如下所示,可以看到我们只需要点击两个按钮就可以使用了。
这里的实现呢,主要采用的是Flask进行开发的,以前的版本是采用java的方式开的,使用起来不但笨重,同时模型识别的速度还比较的慢。最要命的是,搭建环境也是让人头疼的一件事。所以这次我给整个项目做了优化。主要就是提高模型的识别速度,同时让使用者拥有良好的使用体验。
系统主要架构如下图所示:
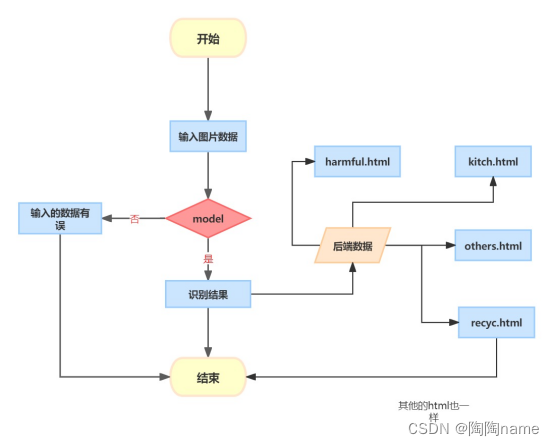
其实比较简单,其实也就4步:
第一步:就是给通过使用端选择需要识别的图片数据
第二步:给数据传到指定目录下,然后给模型识别使用
第三步:模型进行识别
第四步:给识别结果以网页的方式进行展示,这里做的是四分类的任务,所以主要设计了四个网页。还有一个就是出现意外状况的test.html
我举一个例子:比如我们输入的图片是厨房的垃圾图片,那么模型识别以后给识别结果交给Flask代码,Flask代码会根据对应的识别结果给跳转到kitch.html界面中,最后的结果如下所示,可以看到的有识别结果还有识别的图片,以及对于相应的垃圾的分类的定义还有一些小贴士。
Flask的主要代码如下:
uploaded_file = request.files['file']
file_name = uploaded_file.filename
if not os.path.exists(UPLOAD_FOLDER):
os.makedirs(UPLOAD_FOLDER)
# get file path
file_path = os.path.join(UPLOAD_FOLDER, file_name)
# write image to UPLOAD_FOLDER
with open(file_path, 'wb') as f:
f.write(uploaded_file.read())
下面的代码主要就是获取到form传递过来的图片数据,然后整个代码就会给数据上传到指定的文件夹下面。
最后说明:
由于笔者能力有限,所以在描述的过程中难免会有不准确的地方,还请多多包含!
更多NLP和CV文章以及完整代码请到"陶陶name"获取。
项目实战持续更新,大家加油!!!!