Scrapy 框架中创建项目、查看配置信息,以及运行爬虫程序都是通过指令完成。
常用指令如下所示:
| 指令 | 格式 | 说明 |
|---|---|---|
| startproject | scrapy startproject <项目名> | 创建新项目 |
| genspider | scrapy genspider <爬虫文件名> <访问的域名> | 新建爬虫文件 |
| runspider | scrapy runspider <爬虫文件> | 运行一个爬虫文件,不需要创建项目 |
| crawl | scrapy crawl <爬虫项目名> | 运行一个爬虫项目,必须要创建项目 |
| list | scrapy list | 列出项目中所有爬虫文件 |
| view | scrapy view <url地址> | 从浏览器中打开 url 地址 |
| shell | csrapy shell <url地址> | 命令行交互模式 |
| settings | scrapy settings | 查看当前项目的配置信息 |
1、创建 Scrapy 爬虫项目
创建一个名为 scrapy_01 的 Scrapy 项目:
scrapy startproject scrapy_01
复制代码打开命令行,选择python项目路径,创建名为 scrapy_01 的爬虫项目(项目名称不能以数字开头,也不能包含中文):
E:\Python学习代码\爬虫>scrapy startproject scrapy_01
New Scrapy project 'scrapy_01', using template directory 'e:\environment\python3.7.0\lib\site-packages\scrapy\templates\project', created in:
E:\Python学习代码\爬虫\scrapy_01
You can start your first spider with:
cd scrapy_01
scrapy genspider example examle.com
复制代码创建成功,项目文件如下:Scrapy 框架将整个爬虫项目分成了不同的模块,其中每个模块负责处理不同的工作,而且模块之间紧密联系。
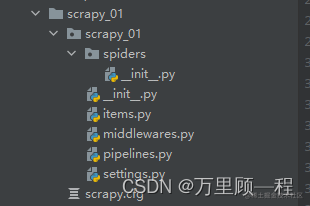
对上图中项目文件的描述:
- scrapy_01:项目文件夹
- scrapy_01:用来装载项目python模块的目录,将会从这里引用代码
- spiders文件夹:用来装载爬虫文件的目录,里面编写具体的爬虫程序,
- items.py:项目的目标文件,定义了数据结构,保存爬取到的数据,继承自Scrapy.Item类·
- middlewares.py:中间件,用来设置一些处理规则
- pipelines.py:项目的管道文件,里面设置保存数据的方法,可以保存到本地或数据库
- settings.py:全局配置文件
- scrapy.cfg:项目基本配置文件
- scrapy_01:用来装载项目python模块的目录,将会从这里引用代码
2、Scrapy—创建爬虫文件
进入在 spiders 目录,创建名为 baidu_test 的 python文件:
-
第一个参数是 python爬虫文件的名称
-
第二个参数是要访问的网站域名
# 域名 www.baidu.com 不用加http
scrapy genspider baidu_test www.baidu.com
复制代码创建完成:
E:\Python学习代码\爬虫\scrapy_01\scrapy_01\spiders>scrapy genspider baidu_test www.baidu.com
Created spider 'baidu_test' using template 'basic' in module:
scrapy_01.spiders.baidu_test
复制代码spiders 文件夹中多了一个 baidu_test .py,说明爬虫文件创建成功,查看 baidu_test.py 文件的内容 :
import scrapy
class BaiduTestSpider(scrapy.Spider):
name = 'baidu_test'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/']
def parse(self, response):
pass
复制代码爬虫文件里有三个属性:name、allowed_domains 和 start_urls,一个方法 parse()
-
name:爬虫文件的名字,必须是唯一的,用于运行爬虫和区分不同的爬虫
-
allowed_domains:允许访问的域名,如果后续请求中的域名不是这个域名或不是这个域名的子级域名,则请求会被过滤掉。
-
start_urls,初始的url地址,爬虫在启动时访问的域名
-
parse():解析的方法,解析返回的响应、提取数据或者进一步生成要处理的请求;每个start_urls 里面的链接完成爬取后,返回的响应对象response会作为唯一的参数传递给这个方法
3、Scrapy—运行爬虫文件
修改 settings.py
在使用 Scrapy 框架运行爬虫文件前,需要修改全局配置文件settings.py。
# 1、定义User-Agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
# 2、是否遵循robots协议(君子协议),一般设置为False,不遵守
ROBOTSTXT_OBEY = False
# 3、最大并发量,默认为16
CONCURRENT_REQUESTS = 32
# 4、下载延迟时间
DOWNLOAD_DELAY = 1
复制代码运行
baidu_test 爬虫文件:
import scrapy
class BaiduTestSpider(scrapy.Spider):
name = 'baidu_test'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/']
def parse(self, response):
print("scrapy框架之执行python爬虫文件")
复制代码执行名为 baidu_test 的爬虫文件指令:
scrapy crawl baidu_test
复制代码执行成功:

settings.py 中常用配置项介绍
# 设置日志级别,DEBUG < INFO < WARNING < ERROR < CRITICAL
LOG_LEVEL = ' '
# 将日志信息保存日志文件中,而不在终端输出
LOG_FILE = ''
# 设置导出数据的编码格式(主要针对于json文件)
FEED_EXPORT_ENCODING = ''
# 非结构化数据的存储路径
IMAGES_STORE = '路径'
# 请求头,此处可以添加User-Agent、cookies、referer等
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36',
}
# 项目管道,代表激活的优先级(1-1000) 越小越优先,默认是300
ITEM_PIPELINES={
'Baidu.pipelines.BaiduPipeline':300
}
# 添加下载器中间件
DOWNLOADER_MIDDLEWARES = {}