前言
数据治理在当今信息时代变得至关重要。随着数据量的不断增长和多样化,组织需要有效地管理和利用这些数据,以支持业务决策和创新发展。不论是做数据分析还是数据解析,利用 Pipeline 可以帮助组织实现数据治理的自动化和规范化;为组织提供更清晰、更可操作的数据视图,从而有力支持数据治理。
Pipeline
Pipeline 是一个自然语言处理工具,可用于大规模数据下的文本处理,提供文本解析、处理、转换的能力,可以将格式各异的数据转换成可观测性数据。在观测云中,用户能够利用 Pipelines 进行数据解析,通过定义解析规则,将各种数据类型切割成符合我们要求的结构化数据,得到的字段可以作为属性字段,更方便进行数据查询及关联分析。
开启 Pipeline 巧用之旅
您可以在观测云工作空间管理 > Pipelines 统一管理或新建 Pipeline 文件;当然您也可以在指标、日志、用户访问、应用性能、基础设施、安全巡检功能目录快捷入口进行创建。
前提条件:安装 DataKit (版本 >= 1.5.0),详情参见:主机安装 - 观测云文档
步骤一:基础设置
观测云支持对丰富的数据类型进行 Pipeline 文本处理,包括日志、指标、用户访问监测、应用性能监测、基础对象、自定义对象、网络、安全巡检,并支持您多选数据来源。

当然,您可以自定义 Pipeline 文件名,并选择是否需要将该文件设置为默认 Pipeline,需要注意的是,每个数据类型只能设置一个「默认 Pipeline」,若当前数据类型在匹配 Pipeline 处理时,未匹配到其他的 Pipeline 脚本,则数据会按照默认 Pipeline 脚本的规则处理。
步骤二:定义解析规则
过滤出所需的数据范围后,您就可以基于观测云提供的 50+ 的脚本函数定义不同来源数据的解析规则。您可以通过页面的列表直接查看所有内置函数的语法格式、说明和示例,快速了解并取用。
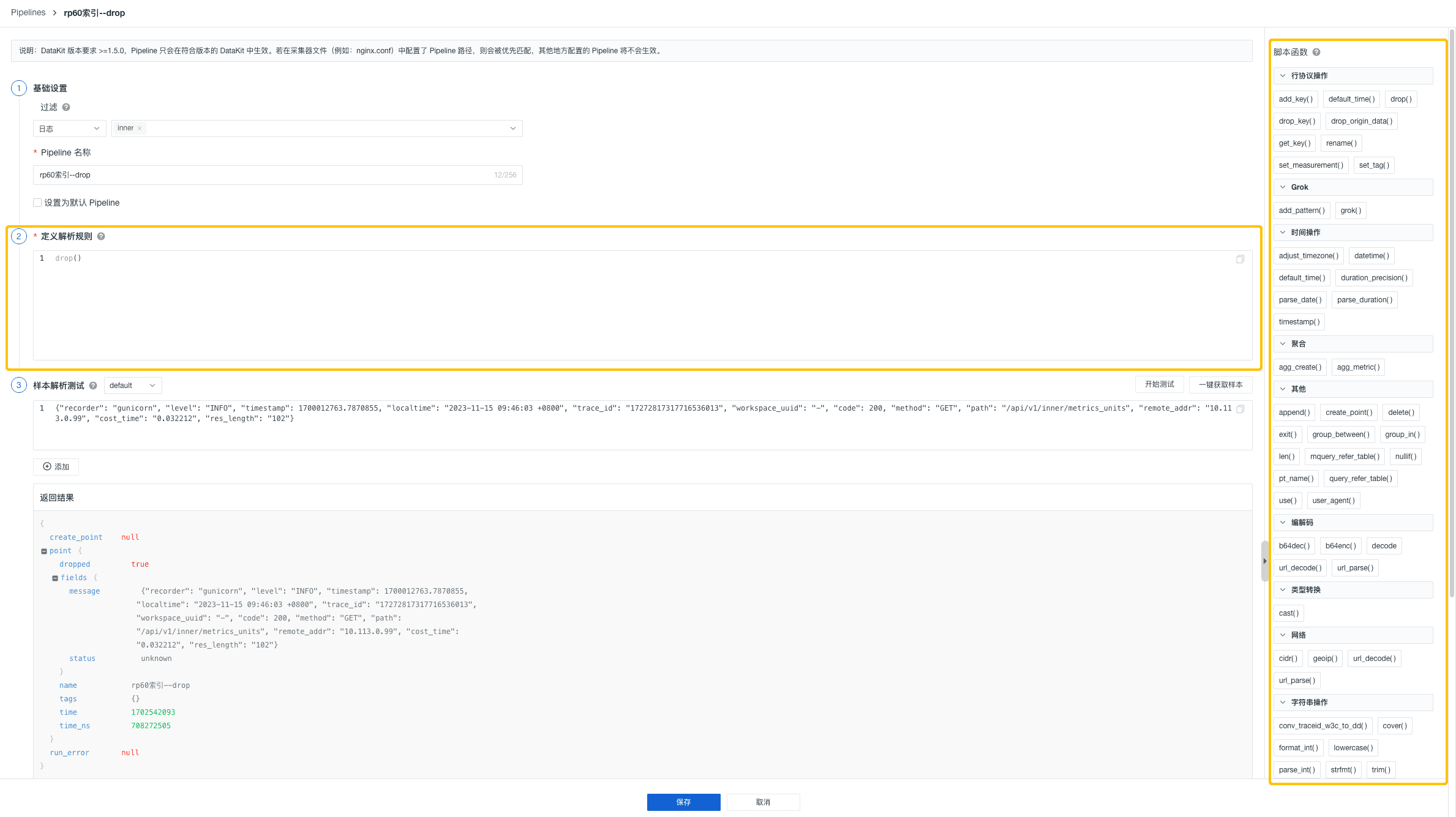
步骤三:样本解析测试
定义解析规则后,若您需要确定输入的解析规则是否正确有效,可以根据已选择的数据类型输入对应的数据,并基于配置的解析规则进行测试。

您可以自由选择一键获取样本测试和手动输入样本测试两种方式填入测试样本数据。
一键获取样本测试
点击「一键获取样本」,观测云会自动从已采集上报的数据中,按照筛选的数据范围选取最新的一条数据作为样本填入。需要注意的是,该方式每次只会查询最近6小时内的数据,若最近6小时无数据上报,则无法自动获取到。
手动输入样本测试
当您手动输入样本数据时,日志数据可在样本解析测试中直接输入 message 内容进行测试。但其他数据类型需要先将内容转换成“行协议”格式,示例如下图所示:

除此之外,您还可以通过终端编写 Pipeline 脚本来测试解析规则。
场景示例
以上我们详细介绍了创建配置 Pipeline 文件的过程,下面将以 DataWay 日志数据处理为例,帮助您更加充分理解使用 Pipeline 实现数据处理的高效性和必然性。
您可以通过 Pipeline 自定义切割出所需结构的日志数据,还可以将切割出来的字段作为属性使用。通过属性字段,我们可以快速筛选相关日志、进行数据关联分析,帮助我们快速去定位问题并解决问题。
Pipeline 官方库
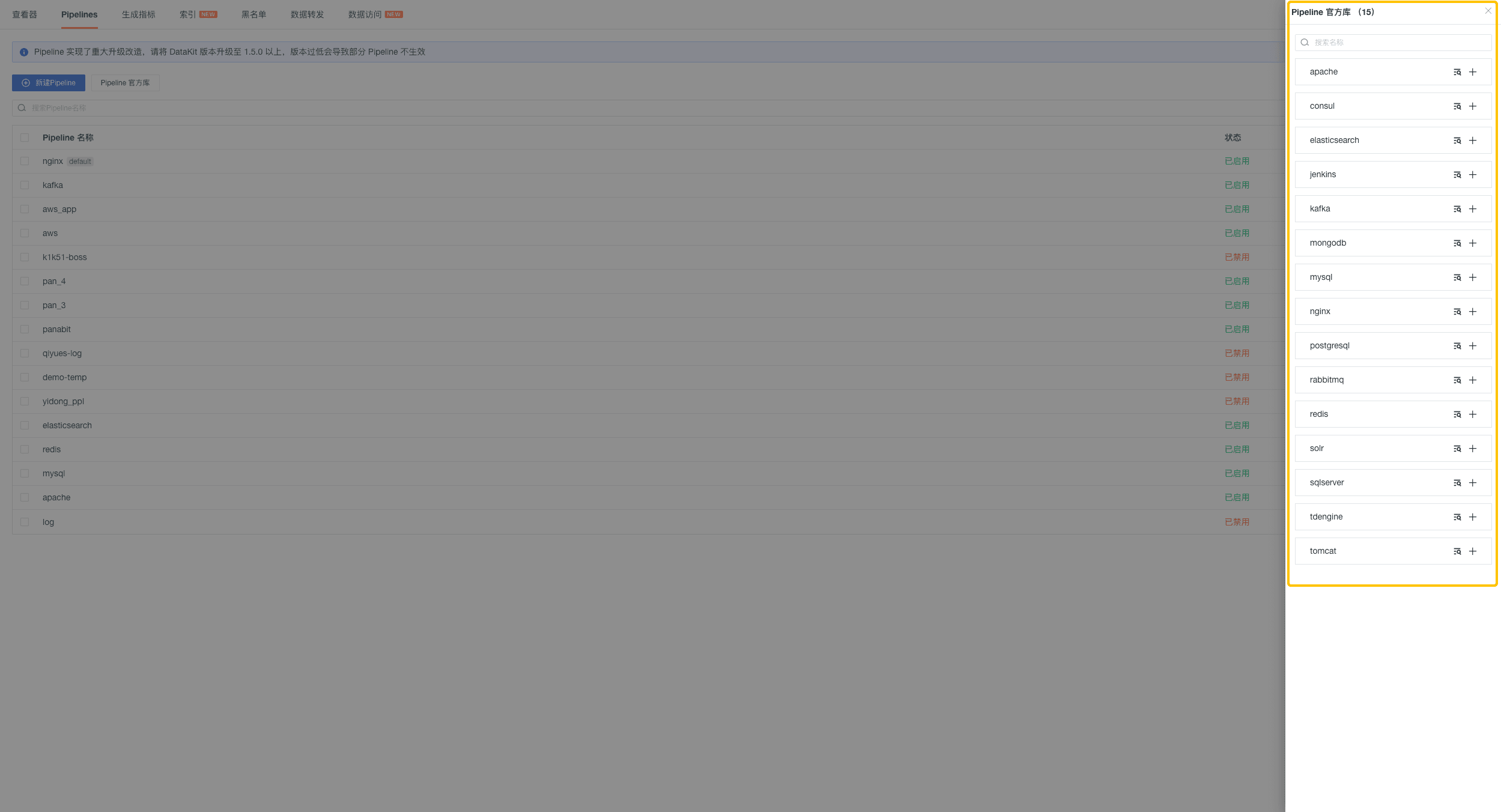
观测云为日志数据提供了标准的 Pipeline 官方库,帮助您快速结构化日志数据,从而高效进行数据检索和分析。
在观测云工作空间日志 > Pipelines 中,您可以查看「Pipeline 官方库」中内置标准的 Pipeline 文件,包括 nginx、apache、redis、elasticsearch、mysql 等。您可以直接克隆后,进行自定义修改解析规则再使用。
日志 Pipeline 使用示例
开启日志采集器后,我们就可以在观测云查看和分析 Dataway 日志,确定需要日志切割出的字段,如日志产生的时间、日志的生成地址、日志状态以及日志的内容等。

我们在观测云工作空间日志 > Pipelines,创建一个新的 Pipeline 文件。日志来源选择 “dataway”,根据所选日志来源自动生成同名 Pipeline。我们可以自定义解析规则,编写 Pipeline 脚本如下:
#%{YEAR}-%{MONTHNUM}-%{MONTHDAY}T%{HOUR}:%{MINUTE}:%{SECOND}%{INT}
#2021/10/25 - 06:48:07
#[GIN] 2021/10/25 - 06:48:07 | 200 | 30.890624ms | 114.215.200.73 | POST "/v1/write/logging?token=tkn_5c862af92c4f49289e775d49234255b4"
add_pattern("TOKEN", "tkn_\\w+")
add_pattern("GINTIME", "%{YEAR}/%{MONTHNUM}/%{MONTHDAY}%{SPACE}-%{SPACE}%{HOUR}:%{MINUTE}:%{SECOND}")
grok(_,"\\[GIN\\]%{SPACE}%{GINTIME:timestamp}%{SPACE}\\|%{SPACE}%{NUMBER:dataway_code}%{SPACE}\\|%{SPACE}%{NOTSPACE:cost_time}%{SPACE}\\|%{SPACE}%{NOTSPACE:client_ip}%{SPACE}\\|%{SPACE}%{NOTSPACE:method}%{SPACE}%{GREEDYDATA:http_url}")
# gin 日志
if cost_time != nil {
if http_url != nil {
grok(http_url, "%{TOKEN:token}")
cover(token, [5, 15])
replace(message, "tkn_\\w{0,5}\\w{6}", "****************$4")
replace(http_url, "tkn_\\w{0,5}\\w{6}", "****************$4")
}
group_between(dataway_code, [200,299], "info", status)
group_between(dataway_code, [300,399], "notice", status)
group_between(dataway_code, [400,499], "warning", status)
group_between(dataway_code, [500,599], "error", status)
if status == 'info' ||
dataway_code == '404' {
drop()
exit()
}
parse_duration(cost_time)
duration_precision(cost_time, "ns", "ms")
add_key(__type, "gin")
set_measurement(__type, true)
set_tag(service,"dataway")
exit()
}
# 非 gin 日志
if cost_time == nil {
# access log
grok(_,"%{TIMESTAMP_ISO8601:timestamp}%{SPACE}%{NOTSPACE:level}%{SPACE}%{NOTSPACE:module}%{SPACE}%{NOTSPACE:code}%{SPACE}%{GREEDYDATA:msg}")
if level == nil {
grok(message,"Error%{SPACE}%{DATA:errormsg}")
if errormsg != nil {
add_key(status,"error")
drop_key(errormsg)
}
}
lowercase(level)
group_in(level, ["error", "panic", "dpanic", "fatal","err","fat"], "error", status)
group_in(level, ["info", "debug", "inf", "bug"], "info", status)
group_in(level, ["warn", "war"], "warning", status)
if msg != nil {
grok(msg, "%{TOKEN:token}")
cover(token, [5, 15])
replace(message, "tkn_\\w{0,5}\\w{6}", "****************$4")
replace(msg, "tkn_\\w{0,5}\\w{6}", "****************$4")
}
add_key(__type, "dataway-log")
set_measurement(__type, true)
set_tag(service,"dataway-log")
exit()
}
现在我们可以输入日志样本进行解析规则测试,验证所配置的解析规则是否正确。可以输入样本为:

通过上述 Pipeline 脚本切割,返回结果为:

确定解析规则正确后,观测云将保存该 Pipeline 文件,您就可以在日志查看器中选择“ DataWay ”的日志,并在日志详情页中查看切割后的所有字段。

您可以利用切割后的字段信息在查看器做数据的快速筛选,也可以设置所需的显示列;不仅帮助您提高数据查询的效率,也让使用体验得到优化。

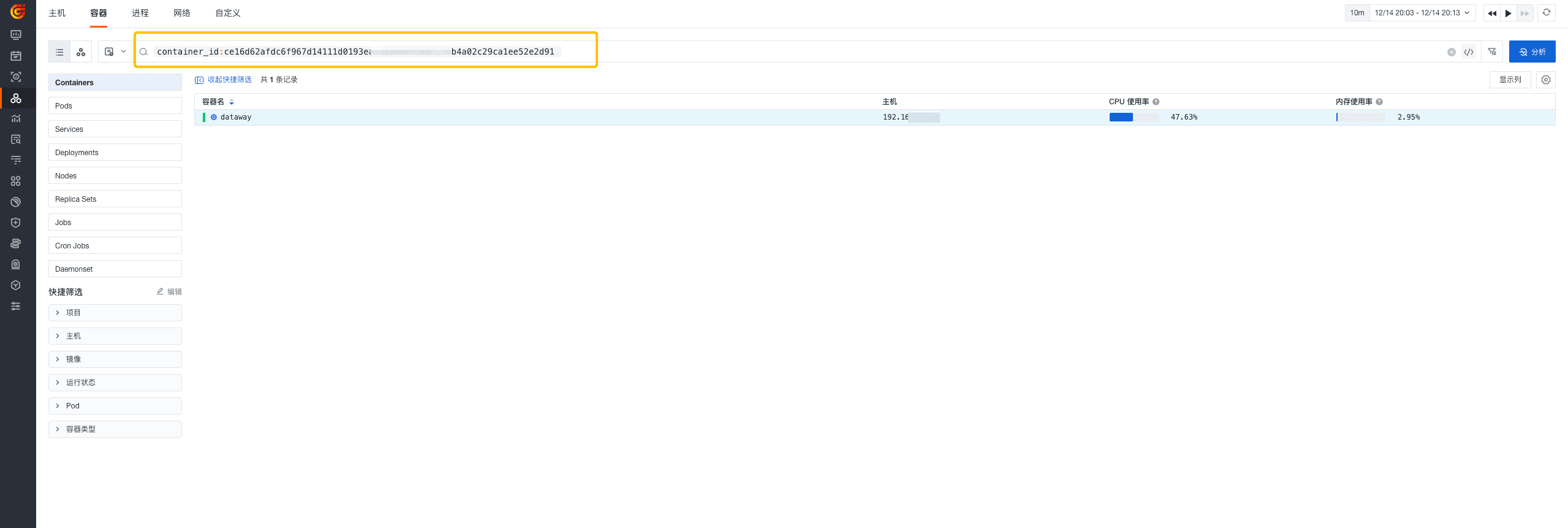
另外,生成的字段可以作为属性字段帮助您与其他模块进行联动,例如,利用上图中的 container_id 在基础设施 > 容器查看器中搜索该容器的相关数据并进行联动分析,帮助我们快速排障并解决。
当然,您也可以在管理 > Pipelines 统一管理所有 Pipeline 文件,进行批量导出、删除等操作,提高工作效率。

结语
本文深入探讨了如何利用 Pipeline 功能完成数据治理,并分享了实际案例展示如何通过定义解析规则实现数据的结构化和标签化,并高效进行更多数据查询和分析;从而帮助您更好地理解和应用 Pipeline 功能,轻松提升数据治理的效率和质量。