公众号「架构成长指南」,专注于生产实践、云原生、分布式系统、大数据技术分享。
前言
从零开始:使用Prometheus与Grafana搭建监控系统
克服网络障碍:Prometheus如何通过间接方式采集目标服务数据
在以上二节,我们介绍了如何使用Prometheus的Pull和Push模式来采集系统指标并在 Grafana进行展现,本节我们介绍如何使用Prometheus的AlertManager进行邮件告警通知。
AlertManager介绍
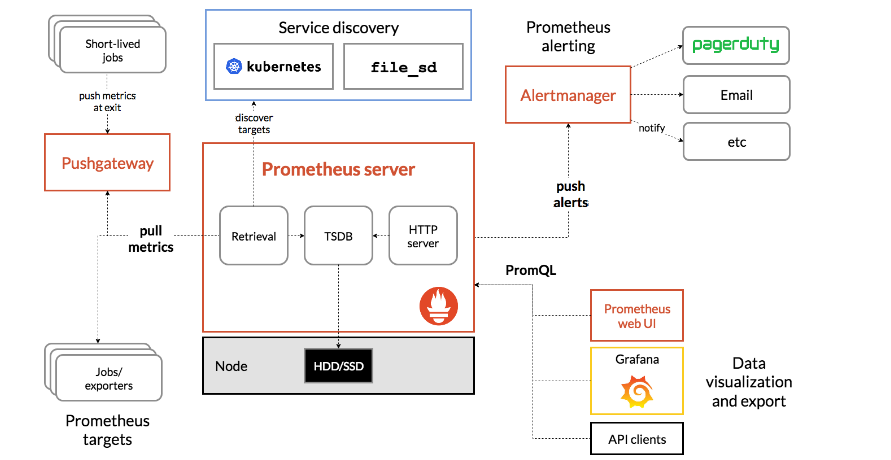
Prometheus是一种用于监控和告警的开源系统,而Alertmanager是Prometheus生态系统中的一个组件,主要用于告警通知。
Alertmanager的主要功能是接收来自Prometheus服务器的告警,并采取适当的操作来通知相关的团队或个人。它通过提供一个统一的接口来处理警报通知,从而简化了告警管理的过程。
下面是Alertmanager的一些关键功能和特点:
- 告警路由和抑制:Alertmanager允许您配置灵活的警报路由规则,以便根据警报的标签和属性将其发送给特定的接收者。
- 多种通知方式:Alertmanager支持多种通知方式,包括电子邮件、短信、PagerDuty、Slack、Webhook等,不过对国内的钉钉和飞书支持性不是特别好,不过好在有开源扩展实现,后续章节介绍。
- 去重和分组:Alertmanager可以对接收到的告警进行去重和分组,以避免发送重复的通知。
- 面向团队的协作:Alertmanager提供了团队协作的功能,可以将警报发送给多个接收者。
- 高可用性和故障转移:Alertmanager支持高可用性配置,可以运行多个实例并使用负载均衡器来分发警报。
AlertManager配置
下载
docker pull prom/alertmanager:v0.25.0

配置
在本地data/prometheus/alertmanager/目录创建alertmanager.yml配置文件
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
Alertmanager的配置主要包含两个部分:路由(route)以及接收器(receivers),所有的告警信息都会从配置中的顶级路由(route)进入路由树,根据路由规则将告警信息发送给相应的接收器。
在Alertmanager中定义一组接收器,比如可以按照角色(比如系统运维,数据库管理员)来划分多个接收器。接收器可以关联邮件、Slack以及其它方式接收告警信息。
启动
docker run --name alertmanager -d -p 9093:9093 -v /data/prometheus/alertmanager:/etc/alertmanager prom/alertmanager:v0.25.0
查看运行状态
Alertmanager启动后可以通过9093端口访问,http://127.0.0.1:9093

Alert菜单下可以查看Alertmanager接收到的告警内容,Silences菜单下则可以通过UI创建静默规则。
关联Prometheus与Alertmanager
在Prometheus的架构中被划分成两个独立的部分,Prometheus负责产生告警,而Alertmanager负责告警产生后的后续处理。因此Alertmanager部署完成后,需要在Prometheus中设置Alertmanager相关的信息。
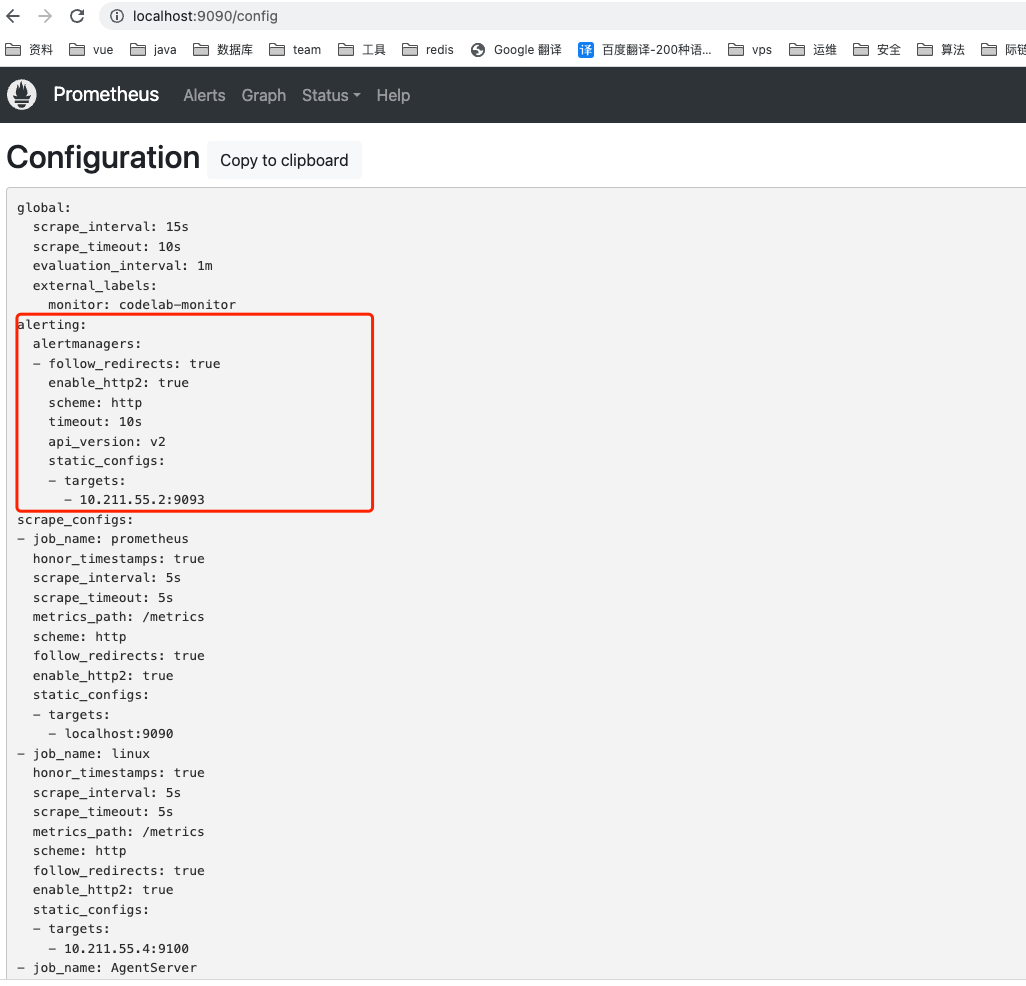
编辑Prometheus配置文件prometheus.yml,并添加以下内容,这里的10.211.55.2作者是本地IP
alerting:
alertmanagers:
- static_configs:
- targets: ['10.211.55.2:9093']

报警规则配置
在prometheus.yml增加如下内容
rule_files:
- /prometheus/rules/*.rules
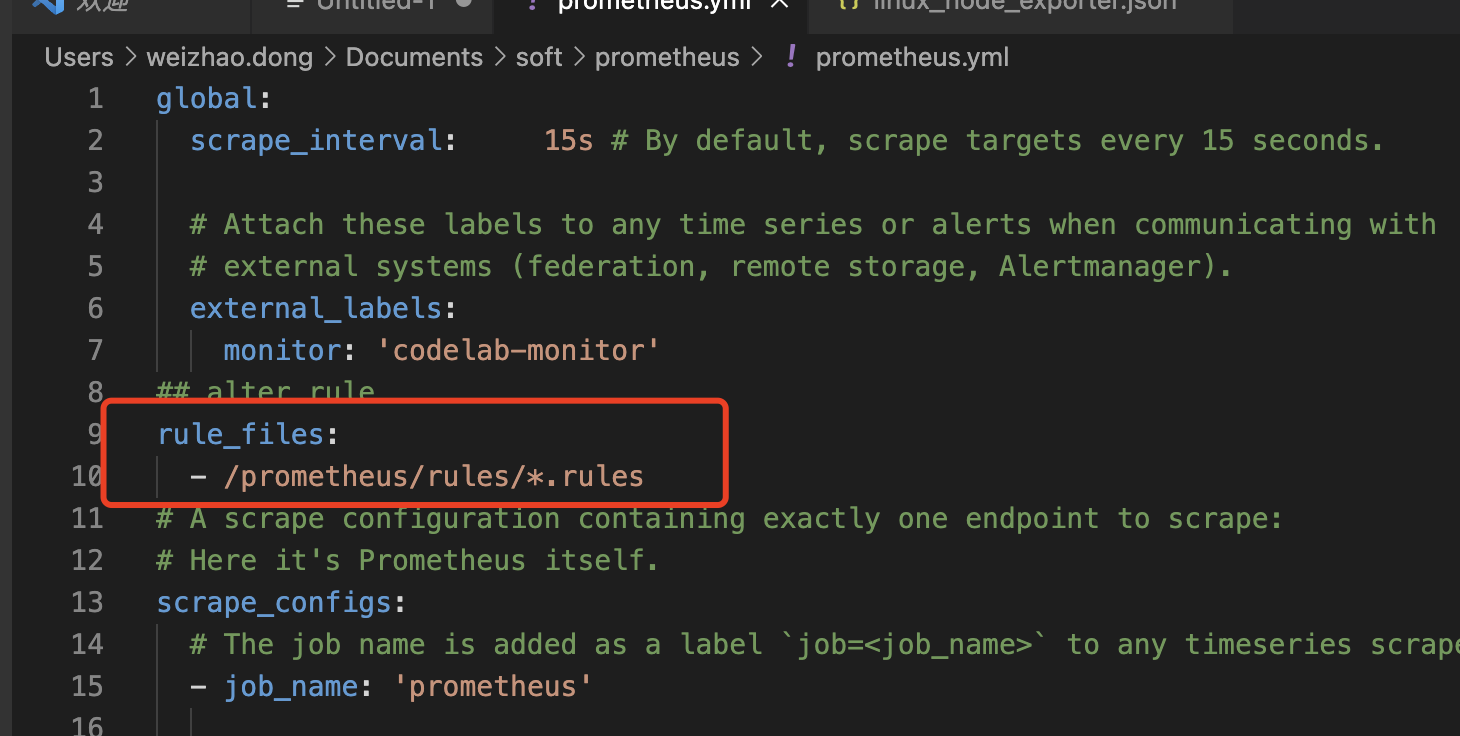
因为在容器启动时用主机的/data/prometheus目录映射到容器的/prometheus目录,因此在主机/data/prometheus/目录创建rules文件夹,并创建告警文件hoststats-alert.rules
mkdir /data/prometheus/rules && cat <<"EOF"> /data/prometheus/rules/hoststats-alert.rules
groups:
- name: hostStatsAlert
rules:
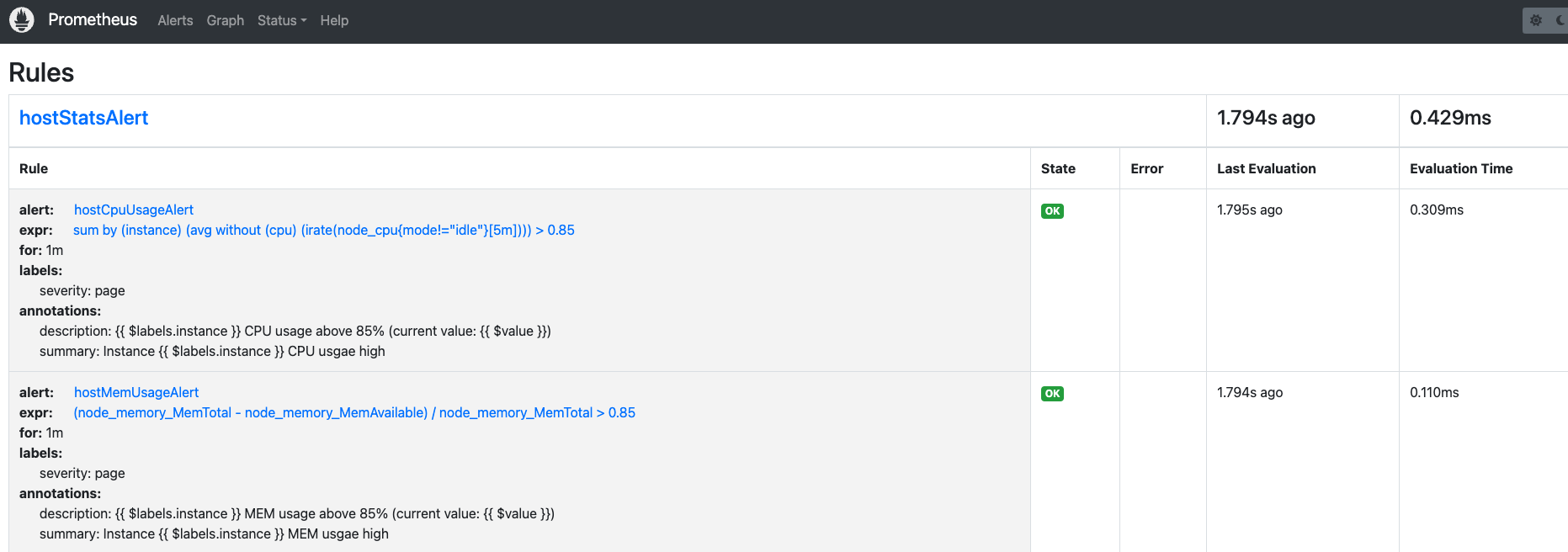
- alert: hostCpuUsageAlert
#报警规则,检测CPU使用率超过0.85,则进行告警
expr: sum(avg without (cpu)(irate(node_cpu_seconds_total{mode!='idle'}[5m]))) by (instance) > 0.85
#表示在满足警报条件后,要等待1分钟才能触发警报
for: 1m
labels:
severity: page
annotations:
#告警模板主题,$labels.instance,表示告警实例
summary: "Instance {{ $labels.instance }} CPU usgae high"
#告警内容
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: hostMemUsageAlert
#内存监控
expr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal > 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }})"
EOF
重启Prometheus
docker restart prometheus
重启完成之后,访问http://localhost:9090/config,查看altering配置是否生效,出现如下红色标识则表示生效
同时访问http://localhost:9090/rules,查看具体规则
邮件告警配置
在监控服务器执行以下命令,拉高cpu使用率,进行告警测试
cat /dev/zero>/dev/null
运行以下命令后查看CPU使用率情况,如下图所示:
sum(avg without (cpu)(irate(node_cpu_seconds_total{mode!='idle'}[5m]))) by (instance)

Prometheus首次检测到满足触发条件后,hostCpuUsageAlert显示有一条告警信息,状态为firing表示已经推送给了altermanager

访问http://127.0.0.1:9093查看告警信息
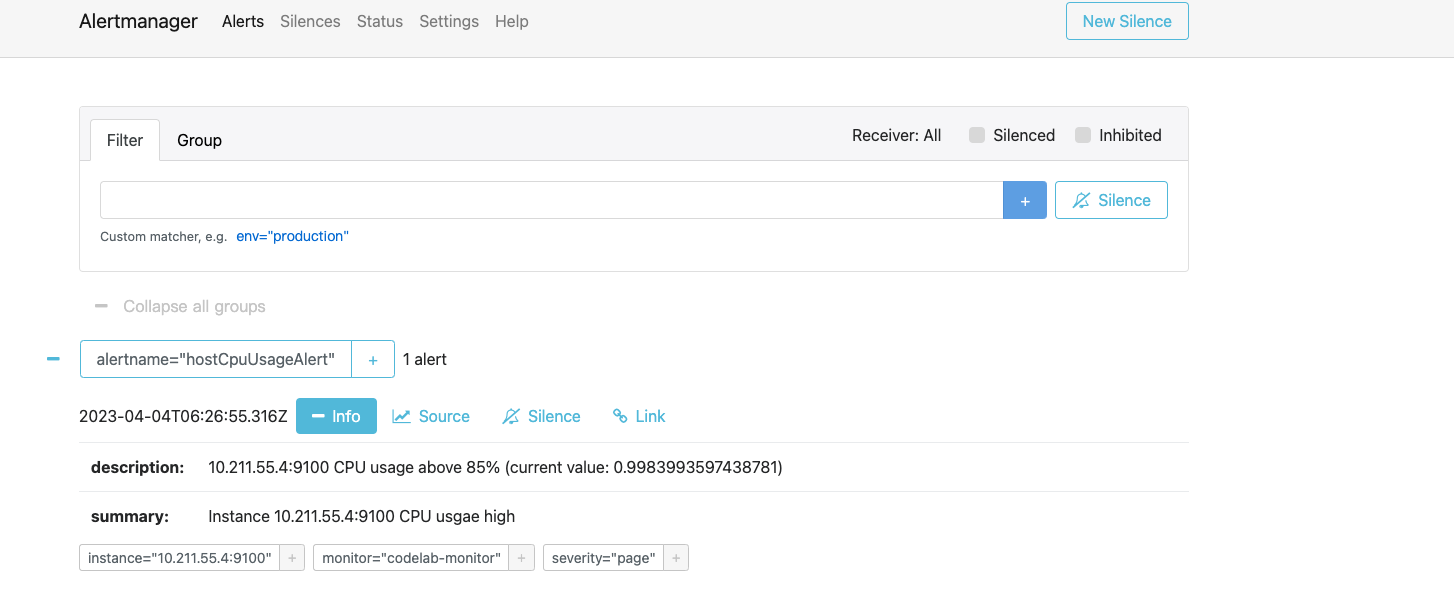
修改alertmanager.yml为以下内容,替换对应账号即可
global:
smtp_smarthost: smtp.qq.com:465
smtp_from: 9238223@qq.com
smtp_auth_username: 9238223@qq.com
smtp_auth_identity: 9238223@qq.com
smtp_auth_password: 123
smtp_require_tls: false
route:
group_by: ['alertname']
receiver: 'default-receiver'
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receivers:
- name: default-receiver
email_configs:
- to: abc123@foxmail.com
send_resolved: true
global: 这是一个全局配置部分,用于配置全局的Alertmanager设置。
smtp_smarthost: 这是SMTP服务器的地址和端口,用于发送邮件通知。smtp_from: 这是邮件发送方的邮件地址,即发送邮件的地址。
route: 用于配置警报的路由规则。
group_by: ['alertname']: 这是一个标签列表,用于按照警报名称(alertname)进行分组。receiver: 'default-receiver': 这是指定默认接收者的名称,即接收警报通知的收件人。group_wait: 30s: 在发送警报通知前等待的时间,以便将相同的警报分组在一起。group_interval: 5m: 这是发送同一组警报通知之间的最小时间间隔。repeat_interval: 1h: 这是在重复发送未解决的警报通知之前等待的时间间隔。
receivers: 接收者部分,用于配置接收告警通知的收件人。
name: default-receiver: 这是默认接收者的名称。email_configs: 用于指定接收邮件通知的收件人和其他相关设置。to: abc123@foxmail.com: 这是收件人的邮件地址,即接收警报通知的邮箱地址。send_resolved: true: 这是一个布尔值,指示是否发送已解决的警报通知。在这个例子中,设置为true,表示发送已解决的警报通知。
重启
docker restart alertmanager
重启完成,访问http://127.0.0.1:9093/#/status,查看配置是否生效

告警测试
在目录服务器执行以下命令,拉高cpu,如果前面已执行则忽略
cat /dev/zero>/dev/null

查看prometheus已收到告警信息
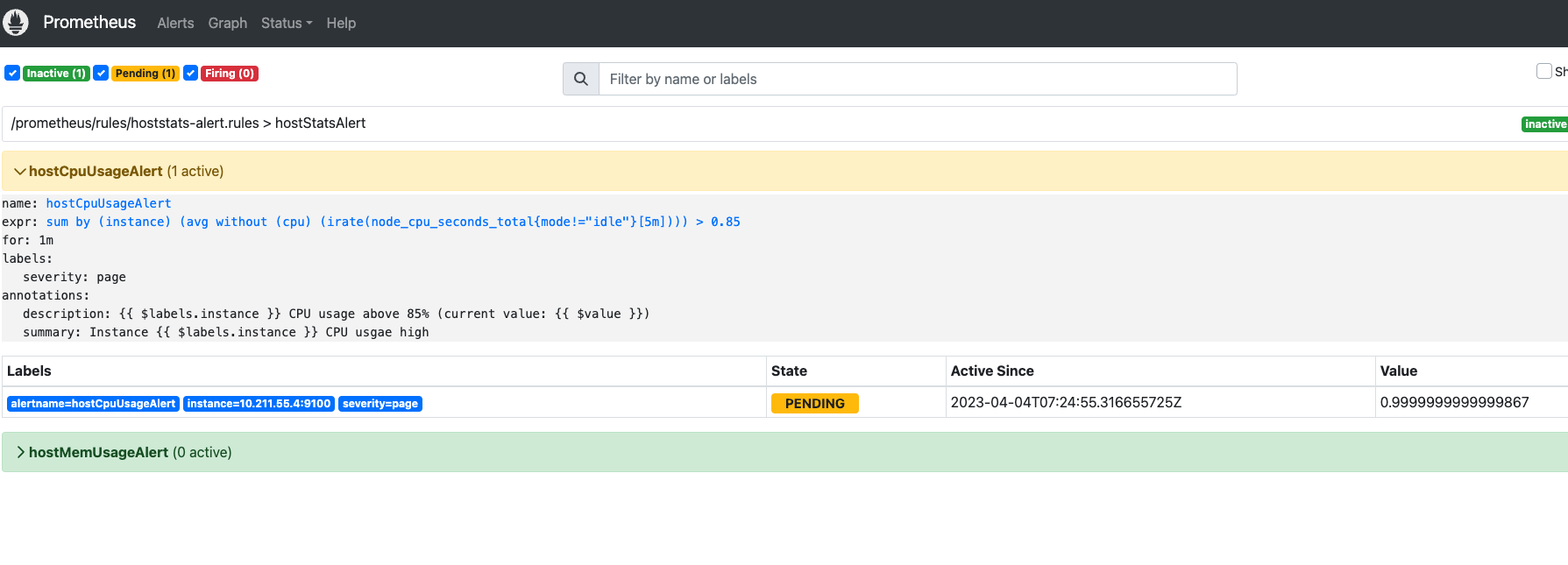 等待一分钟左右,会推送给altermanager,altermanager等待30s,会推送至对应的邮箱,如下图
等待一分钟左右,会推送给altermanager,altermanager等待30s,会推送至对应的邮箱,如下图

调整告警模版并测试
在/data/prometheus/alertmanager目录下创建模版文件,这里的2006-01-02 15:04:05是go语言的日志格式,固定值
cat > /data/prometheus/alertmanager/notify-template.tmpl <<EOF
{{ define "test.html" }}
{{ range .Alerts }}
=========start==========<br>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
=========end==========<br>
{{ end }}
{{ end }}
EOF
关联告警模版
global:
smtp_smarthost: smtp.qq.com:465
smtp_from: 9238223@qq.com
smtp_auth_username: 9238223@qq.com
smtp_auth_identity: 9238223@qq.com
smtp_auth_password: 123
smtp_require_tls: false
#添加模板
templates:
#指定路径
- '/etc/alertmanager/notify-template.tmpl'
route:
group_by: ['alertname']
receiver: 'default-receiver'
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receivers:
- name: default-receiver
email_configs:
- to: abc123@foxmail.com
html: '{{ template "test.html" . }}'
send_resolved: true
重启altermanager
docker restart alertmanager
最终结果

告警优化
观察以上告警有以下问题
- 触发时间不对,用的是UTC时间
- 无法区分告警与恢复邮件
- 邮件标题看起来可读性比较差
因此针对以上问题进行调整
增加自愈模板
在以下时间增加28800e9,转换为东八区时间,即北京时间
{{ define "test.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{ range .Alerts }}
<h1 align="left" style="color:red;">告警</h1>
<pre>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警时间:{{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
</pre>
{{ end }}
{{ end }}
#增加自愈模板
{{- if gt (len .Alerts.Resolved) 0 -}}
{{ range .Alerts }}
<h1 align="left" style="color:green;">恢复</h1>
<pre>
告警名称:{{ .Labels.alertname }}<br>
告警级别:{{ .Labels.severity }}<br>
告警机器:{{ .Labels.instance }}<br>
告警详情:{{ .Annotations.summary }}<br>
告警时间:{{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
恢复时间:{{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
</pre>
{{- end }}
{{- end }}
{{- end }}
邮件标题调整
在headers增加Subject则为邮件标题,这里我们进行判断如果告警邮件标题为:系统监控告警恢复后,标题改为:系统监控告警恢复
global:
smtp_smarthost: smtp.qq.com:465
smtp_from: 9238223@qq.com
smtp_auth_username: 9238223@qq.com
smtp_auth_identity: 9238223@qq.com
smtp_auth_password: 123
smtp_require_tls: false
templates: #添加模板
- '/etc/alertmanager/notify-template.tmpl' #指定路径
route:
group_by: ['alertname']
receiver: 'default-receiver'
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receivers:
- name: default-receiver
email_configs:
- to: abc123@foxmail.com
html: '{{ template "test.html" . }}'
send_resolved: true
headers: { Subject: "系统监控告警{{- if gt (len .Alerts.Resolved) 0 -}}恢复{{ end }}" }
再次测试
再次重启,拉高cpu进行测试,告警信息如下
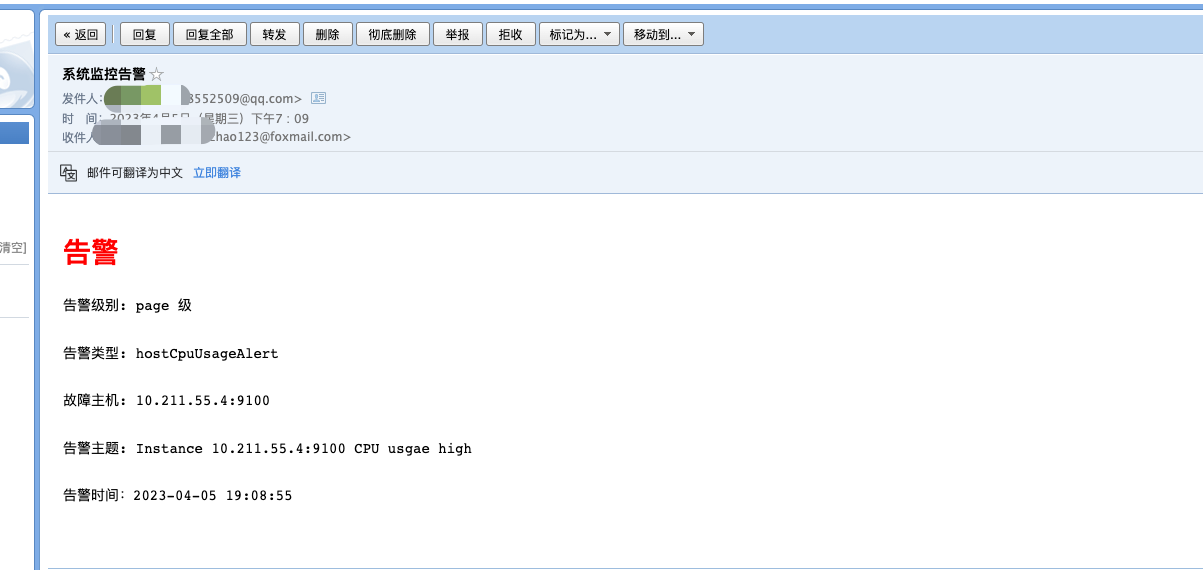
恢复通知邮件

总结
本节我们介绍了Prometheus的Alertmanager以及如何利用它对指标进行告警,同时我们还讨论了如何通过邮件通知来实现告警,并对邮件模板进行了优化。在接下来的章节中,我们将进一步探讨如何使用Prometheus监控业务系统的业务指标,并实现全面的监控和告警通知。