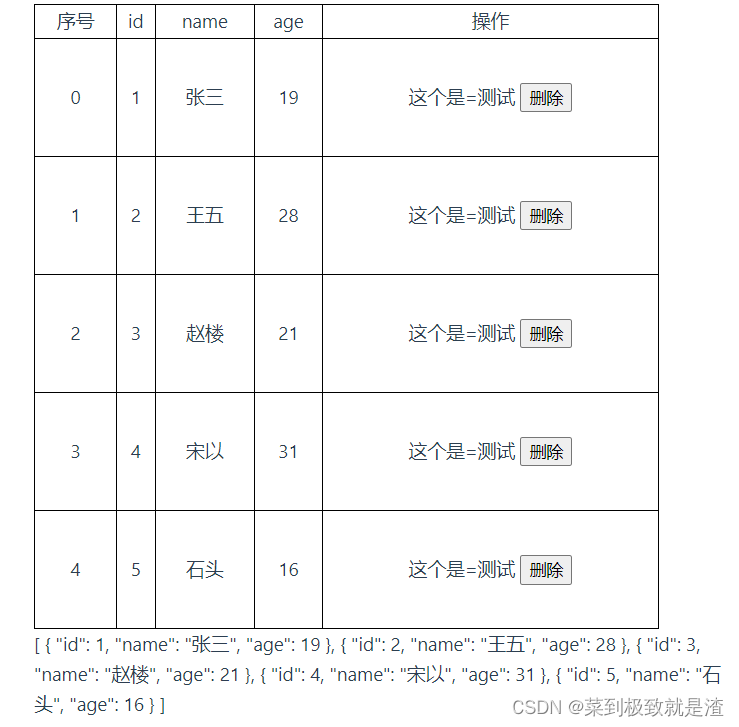
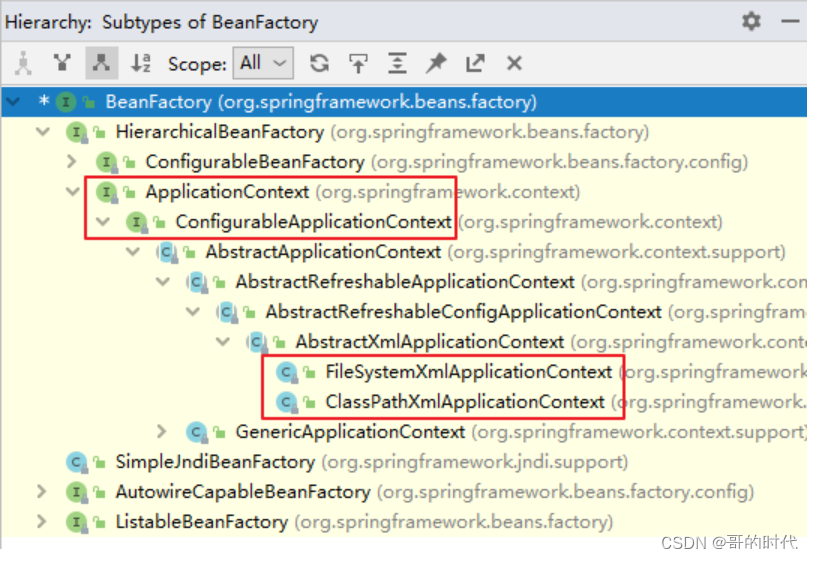
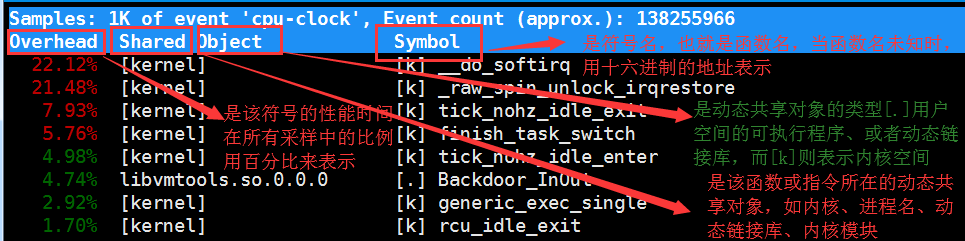
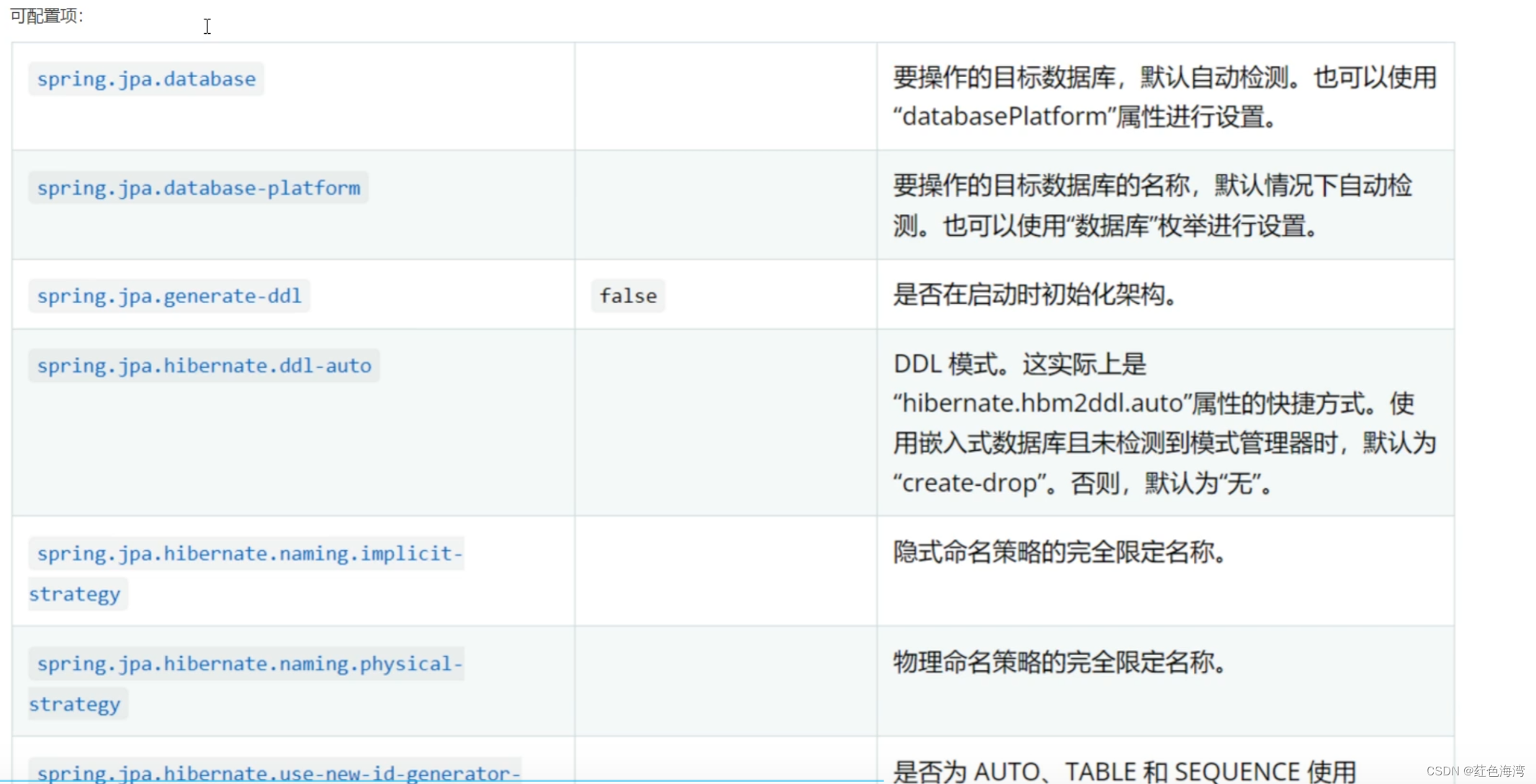
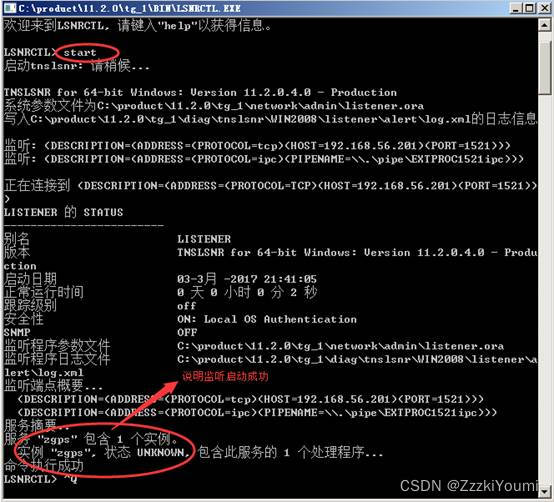
总结一下最近看的这篇结合神经网络的全局光照论文 这是一篇2013年TOG的论文。
总结一下最近看的这篇结合神经网络的全局光照论文 这是一篇2013年TOG的论文。
介绍
论文的主要思想是利用了神经网络的非线性特性去拟合全局光照中的间接光照部分,采用了基础的2层MLP去训练,最终能实现一些点光源、glossy材质的光照渲染。为了更好的理解、其输入输出表示如下。
首先是原文的介绍: 4个三维向量:着色点位置
x
p
x_p
xp,间接光照对应视角方向
v
v
v,点光源位置
l
l
l,点表面法线
n
n
n,再加上BRDF附带的albedo等参数
n
p
n_p
np。

我们在拥有了能预测间接光照的模型后,就可以在实时渲染中计算完直接光照后进行叠加即可。
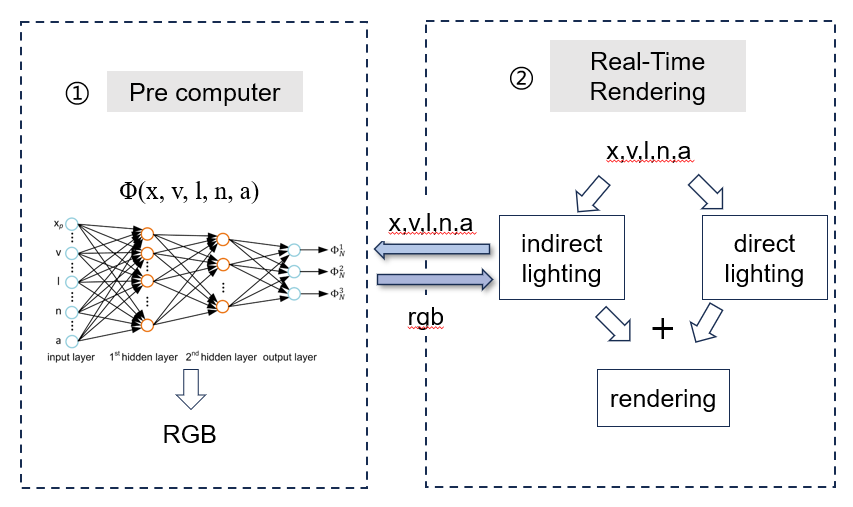
可以看出最主要的就是如何去训练出这个ML模型。接下去进一步讨论,
训练神经网络
首先是模型的训练损失计算
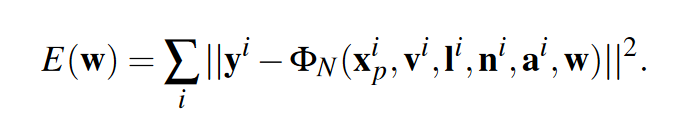 然后对整个训练模型训练过程的神经网络进行表示
然后对整个训练模型训练过程的神经网络进行表示
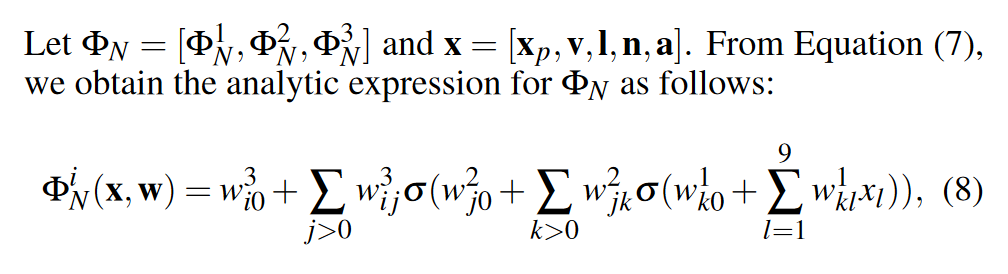
之后通过最小化
E
(
w
)
E(w)
E(w)进行训练
作者指出,在理论上一层的隐藏层神经网络可以拟合连续的方程,而由于间接光照s+包含了较多峰谷,两层能更好的拟合少量的这样节点,所以理论上都是可以实现,只是会增加神经网络参数或层数,太大的话不好训练。
渲染
渲染阶段主要通过将每个像素的相应值传入神经网络计算间接光照再和计算的直接光照相加。
其中
a
(
x
p
)
a(x_p)
a(xp)和
n
(
x
p
)
n(x_p)
n(xp)可以从渲染管线中获得(g-buffer),然后为了神经网络更好的训练减少不必要的参数。这两个加上的参数,作者认为很有用所以也做了消融实验

a是ground truth, b是两个都加,c只有albedo,d都没加, 看到b 和a十分的效果十分的接近。
考虑场景复杂性
另外考虑到场景的复杂性,用kd-tree对数据点降维然后进行了划分,让尽可能相似的点在一起,然后训练一个共用的RRF神经网络。其中为了防止不同RRF之间的非连续性还将对应的box扩大了10%
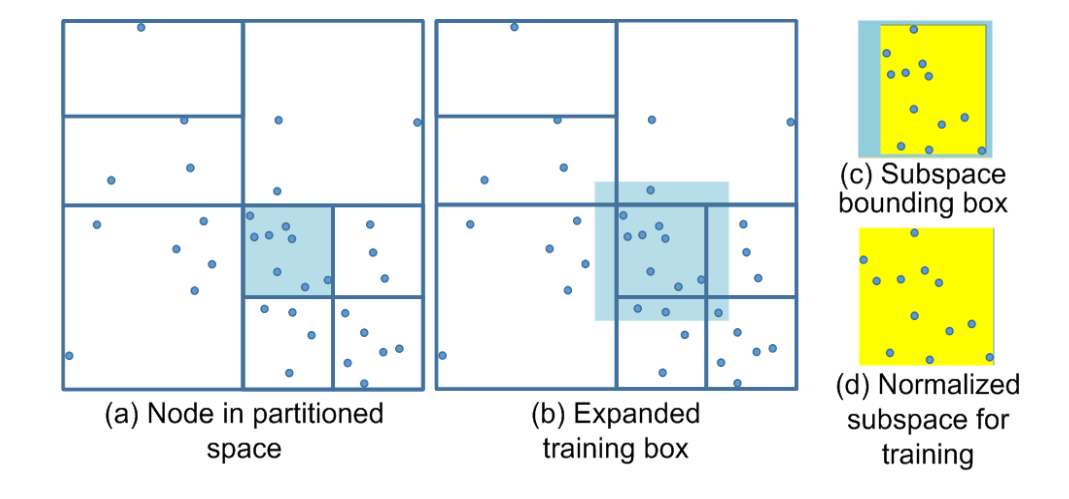
考虑到划分轴选择的问题,最佳分裂轴是在 ν 的子节点上产生最小训练和预测误差的轴,暴力或者随机的遍历所有轴选取即可。
实验表现
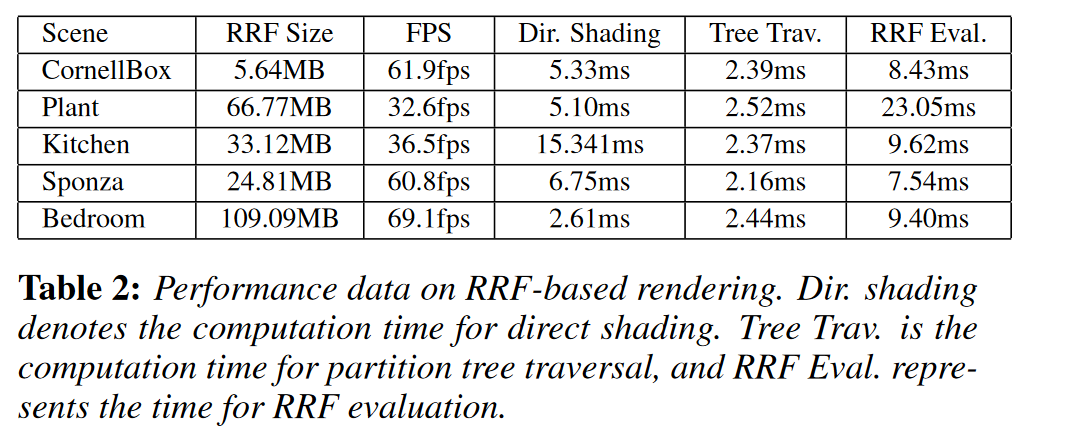
其中RRF的效果能达到30-60多帧的效果,在当年某些场景还算可以。但当场景几何复杂了,就像Plant一样,RRF的难学习到其中的共性,自然就慢。
跟训练集的大小也有关系,训练集越大效果越好

可以对glossy的材质进行渲染,就像下面的墙面

总的来说,当年选用的两层简单的MLP效果还是有很大的局限,场景一大稍微一复杂就无法有效拟合了,并且推理的时间也相当的慢,光照如果变化的剧烈也一样,另外场景也是不能变动的,动了预测的肯定就不准了,毕竟是用训练数据训练的网络。



![[Verilog] Verilog 操作符与表达式](https://img-blog.csdnimg.cn/direct/590491ae4b2d4883958f95287ca8dd1f.png)