今天学习内容:二叉树理论基础、递归遍历 、迭代遍历、统一迭代
讲解:代码随想录
二叉树题目思维导图如下,来自代码随想录。

1.二叉树理论基础
1.1二叉树种类
满二叉树
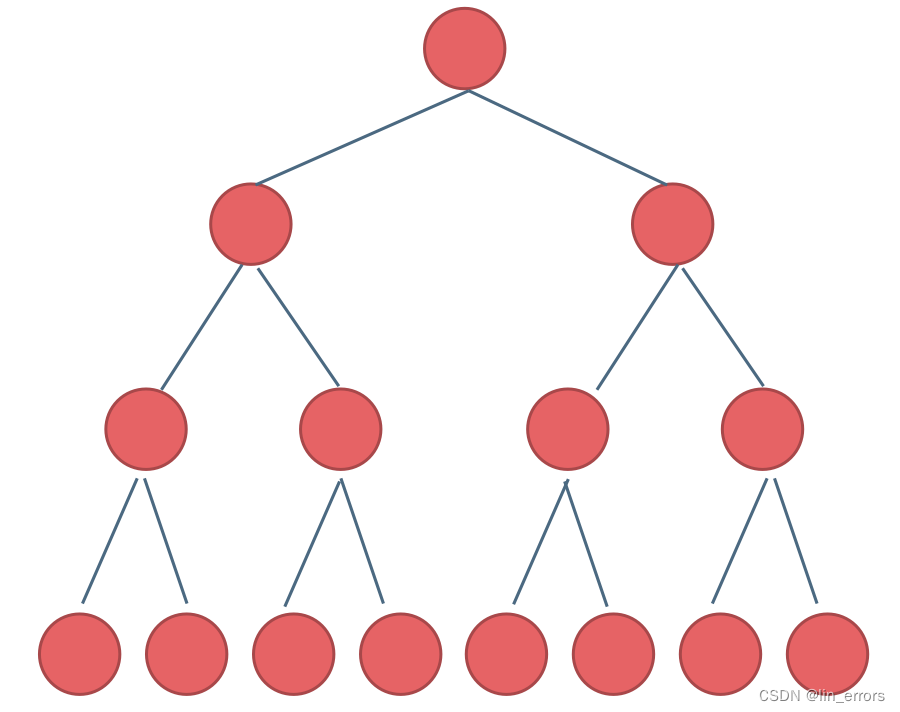
完全二叉树
二叉搜索树
平衡二叉搜索树

C++中map、set、multimap,multiset的底层实现都是平衡二叉搜索树。
1.2存储方式
链式
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};以上是二叉树的链式存储的二叉树节点的定义方式。
顺序

1.3遍历方式
-
深度优先遍历
- 前序遍历(递归法,迭代法)
- 中序遍历(递归法,迭代法)
- 后序遍历(递归法,迭代法)

-
广度优先遍历
- 层次遍历(迭代法)
递归遍历
每次写递归,都按照这三要素来写,可以保证大家写出正确的递归算法!
-
确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
-
确定终止条件: 写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
-
确定单层递归的逻辑: 确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
以下以前序遍历为例:
1.确定递归函数的参数和返回值:因为要打印出前序遍历节点的数值,所以参数里需要传入vector来放节点的数值,除了这一点就不需要再处理什么数据了也不需要有返回值,所以递归函数返回类型就是void,代码如下:
void traversal(TreeNode* cur, vector<int>& vec)
2.确定终止条件:在递归的过程中,如何算是递归结束了呢,当然是当前遍历的节点是空了,那么本层递归就要结束了,所以如果当前遍历的这个节点是空,就直接return,代码如下:
if (cur == NULL) return;
3.确定单层递归的逻辑:前序遍历是中左右的循序,所以在单层递归的逻辑,是要先取中节点的数值,代码如下:
vec.push_back(cur->val); // 中
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右前序遍历
class Solution {
public:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
vec.push_back(cur->val); // 中
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
traversal(root, result);
return result;
}
};leetcode上三道题目相关可以做:
- 144.二叉树的前序遍历
- 145.二叉树的后序遍历
- 94.二叉树的中序遍历
迭代遍历

前序遍历
前序遍历是中左右,每次先处理的是中间节点,那么先将根节点放入栈中,然后将右孩子加入栈,再加入左孩子。
先加入右孩子,再加入左孩子:因为这样出栈的时候才是中左右的顺序。以下是前序迭代的代码:
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> result;
if (root == NULL) return result;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top(); // 中
st.pop();
result.push_back(node->val);
if (node->right) st.push(node->right); // 右(空节点不入栈)
if (node->left) st.push(node->left); // 左(空节点不入栈)
}
return result;
}
};后序遍历
同理,后序遍历只是转换了顺序。

以下是后序迭代的代码:
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> result;
if (root == NULL) return result;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
st.pop();
result.push_back(node->val);
if (node->left) st.push(node->left); // 相对于前序遍历,这更改一下入栈顺序 (空节点不入栈)
if (node->right) st.push(node->right); // 空节点不入栈
}
reverse(result.begin(), result.end()); // 将结果反转之后就是左右中的顺序了
return result;
}
};在迭代的过程中,其实我们有两个操作:
- 处理:将元素放进result数组中
- 访问:遍历节点
前序遍历的顺序是中左右,先访问的元素是中间节点,要处理的元素也是中间节点,所以刚刚才能写出相对简洁的代码,因为要访问的元素和要处理的元素顺序是一致的,都是中间节点。
那么再看看中序遍历,中序遍历是左中右,先访问的是二叉树顶部的节点,然后一层一层向下访问,直到到达树左面的最底部,再开始处理节点(也就是在把节点的数值放进result数组中),这就造成了处理顺序和访问顺序是不一致的。
因此中序无法这么简单地操作。
统一迭代
由于迭代遍历无法同时解决访问节点(遍历节点)和处理节点(将元素放进结果集)不一致的情况。那我们就将访问的节点放入栈中,把要处理的节点也放入栈中但是要做标记。
如何标记呢,就是要处理的节点放入栈之后,紧接着放入一个空指针作为标记。 这种方法也可以叫做标记法。

中序遍历代码如下:
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
if (root != NULL) st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
if (node != NULL) {
st.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中
if (node->right) st.push(node->right); // 添加右节点(空节点不入栈)
st.push(node); // 添加中节点
st.push(NULL); // 中节点访问过,但是还没有处理,加入空节点做为标记。
if (node->left) st.push(node->left); // 添加左节点(空节点不入栈)
} else { // 只有遇到空节点的时候,才将下一个节点放进结果集
st.pop(); // 将空节点弹出
node = st.top(); // 重新取出栈中元素
st.pop();
result.push_back(node->val); // 加入到结果集
}
}
return result;
}
};今日总结
1.了解二叉树的种类,存储方式,遍历方式以及二叉树的定义。
2.二叉树的三种递归遍历、迭代遍历、统一迭代。
![[Verilog] Verilog 操作符与表达式](https://img-blog.csdnimg.cn/direct/590491ae4b2d4883958f95287ca8dd1f.png)