—— 分而治之,逐个击破
把特征空间划分区域
每个区域拟合简单模型
分级分类决策
1、核心思想和原理

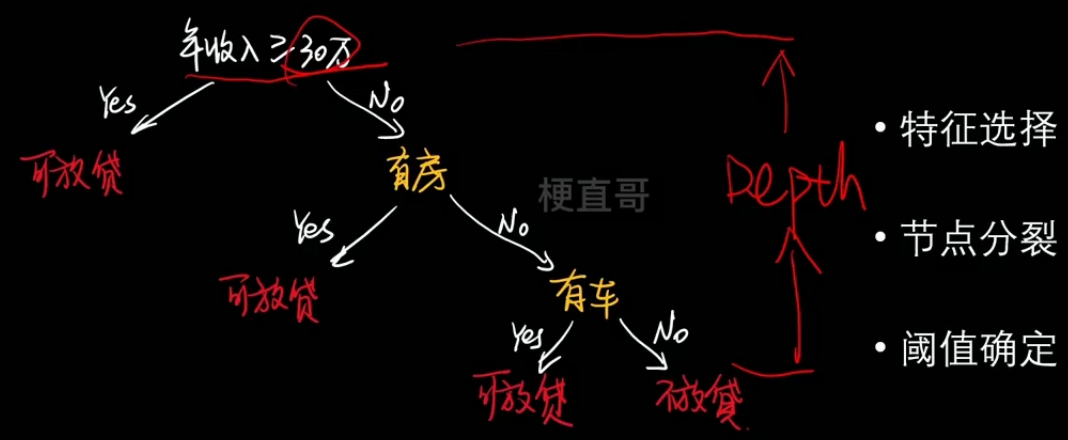
- 举例:
- 特征选择、节点分类、阈值确定
2、信息嫡
熵本身代表不确定性,是不确定性的一种度量。
熵越大,不确定性越高,信息量越高。
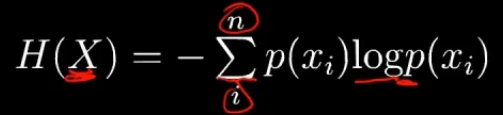
为什么用log?—— 两种解释,可能性的增长呈指数型;log可以将乘法变为加减法。
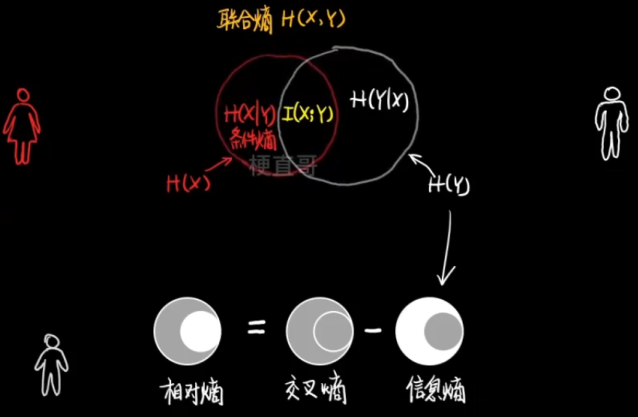
联合熵 的物理意义:观察一个多变量系统获得的信息量。
条件熵 的物理意义:知道其中一个变量的信息后,另一个变量的信息量。
给定了训练样本 X ,分类标签中包含的信息量是什么。

信息增益(互信息)
代表了一个特征能够为一个系统带来多少信息。

熵的分类

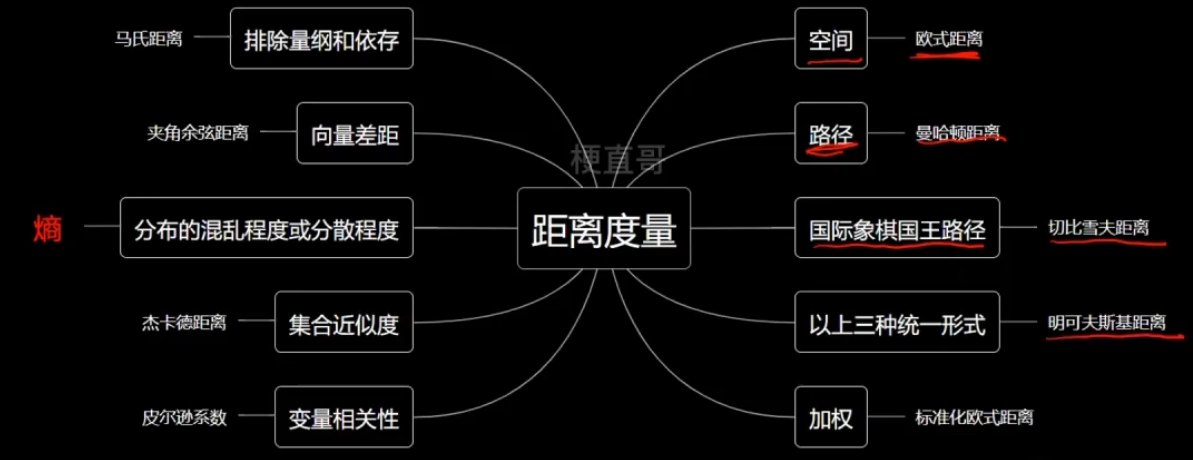
熵的本质:特殊的衡量分布的混乱程度与分散程度的距离
决策树的本质
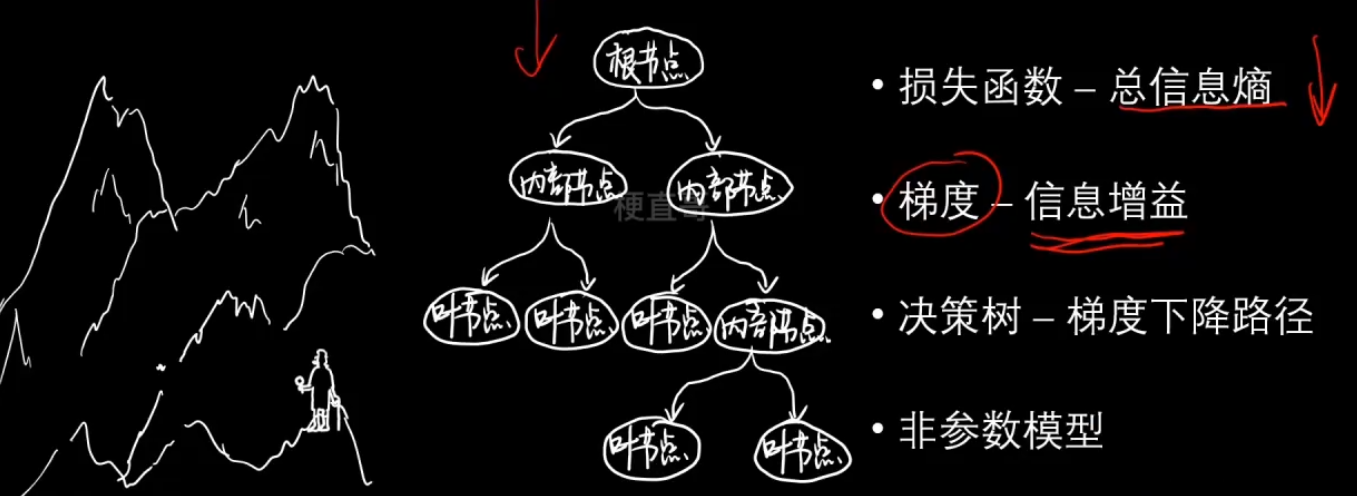
3、决策树分类
4、基尼系数

基尼系数运算稍快;
物理意义略有不同,信息熵表示的是随机变量的不确定度;
基尼系数表示在样本集合中一个随机选中的样本被分错的概率,也就是纯度。
基尼系数越小,纯度越高。
模型效果上差异不大。
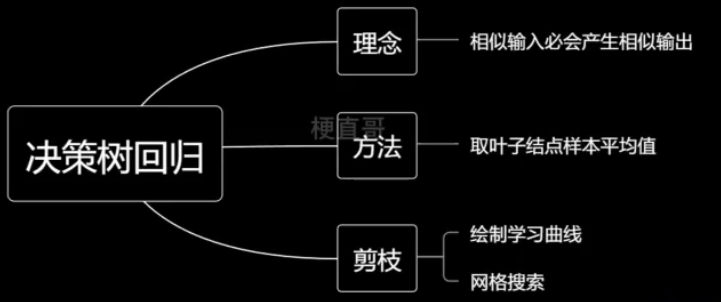
5、决策树剪枝
为什么要剪枝?
复杂度过高。
预测复杂度:O(logm)
训练复杂度:O(n x m x logm)
logm为数的深度,n为数据的维度。
容易过拟合
为非参数学习方法。
目标:
降低复杂度
解决过拟合
手段:
限制深度(结点层数)
限制广度(叶子结点个数)
—— 设置超参数

6、决策树回归
基于一种思想:相似输入必会产生相似输出。
取节点平均值。
7、优缺点和适用条件
优点:
符合人类直观思维
可解释性强
能够处理数值型数据和分类型数据
能够处理多输出问题
缺点:
容易产生过拟合
决策边界只能是水平或竖直方向
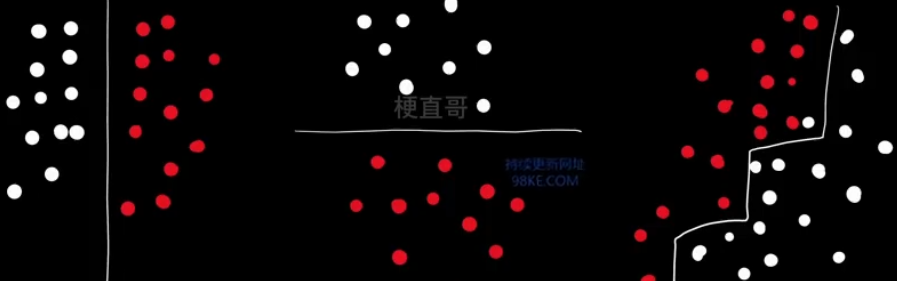
不稳定,数据的微小变化可能生成完全不同的树
参考于
Chapter-07/7-4 决策树分类.ipynb · 梗直哥/Machine-Learning - Gitee.com





![[密码学]AES](https://img-blog.csdnimg.cn/direct/ba0b792076044a7a9b943b87d4526712.png)



![[NOI2015] 程序自动分析(并查集)](https://img-blog.csdnimg.cn/direct/6d24656acd254b13af07693f26ed3722.png)