《Restormer: Efficient Transformer for High-Resolution Image Restoration》发表于2022年的CVPR,在 Transformer block 中进行了几个关键设计以提出一种新的高效的视觉 Transformer,称为 Restormer,再一次刷新了视觉 transformer 在高分辨率图像复原领域的性能并取得了新 SOTA。评估囊括了图像复原的主流任务,包括图像去雨、单图像运动去模糊、散焦去模糊和图像去噪。

下面对其技术特点做点记录。
1. 解决cnn的不足:
1)感受野有限
2)输入尺寸固定
2. 解决transform的不足:
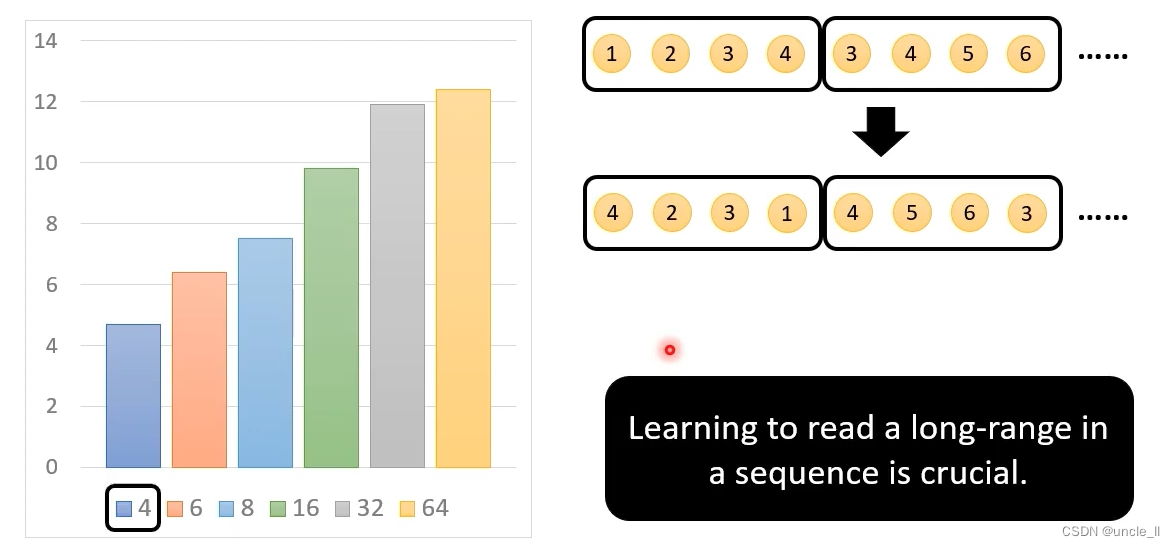
1)计算复杂度随着空间分辨率的增加而二次增长
3. 优势结构:MDTA(Multi-Dconv Head Transposed Attention)和GDFN( Gated-Dconv Feed-Forward Network)
1)MDTA(Multi-Dconv Head Transposed Attention:多头注意力机制

~计算通道上的自注意力而不是空间上,即计算跨通道的交叉协方差来生成隐式地编码全局上下文的注意力图
~计算自注意力map之间,使用depth-wise卷积操作生成Q、K、V,这样可以强调局部信息
2)GDFN( Gated-Dconv Feed-Forward Network)
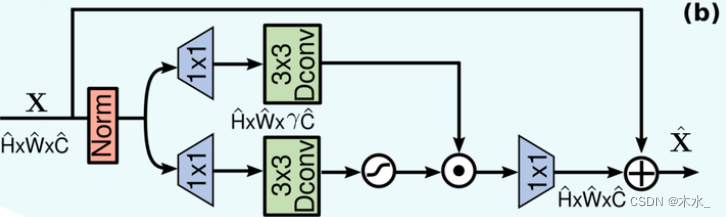
GDFN 控制各层中的通道中的信息流,从而使得每层都专注于与其他层之间互补的精细细节。既与MDTA相比,GDFN 更专注于使用上下文信息丰富特
~门控制
~GELU 非线性激活:GELU对于输入乘以一个0,1组成的mask,而该mask的生成则是依靠伯努利分布的随机输入,可以看作 dropout的思想和relu的结合,增加鲁棒性
4. 渐进式训练方法
在早期阶段,网络在较小的图像块上进行训练,在后期的训练阶段,网络在逐渐增大的图像块上进行训练,所以会随着patch大小的增加而减少batch大小,以保持相同的训练时间。
最后,根据实际训练情况来看,restormer,尤其是小型化的restormer,未必比同大小的cnn更有优势。








![[ 8 种有效方法] 如何在没有备份的情况下恢复 Android 上永久删除的照片?](https://img-blog.csdnimg.cn/direct/8b2d752b89814d5db5ff1410dc314ac9.png)