V1
V1根本思想: 1.GConv替换resnet的普通1*1Conv
2.GConv后加channel shuffle模块
对GConv的不同组进行重新组合。channel_shuffle
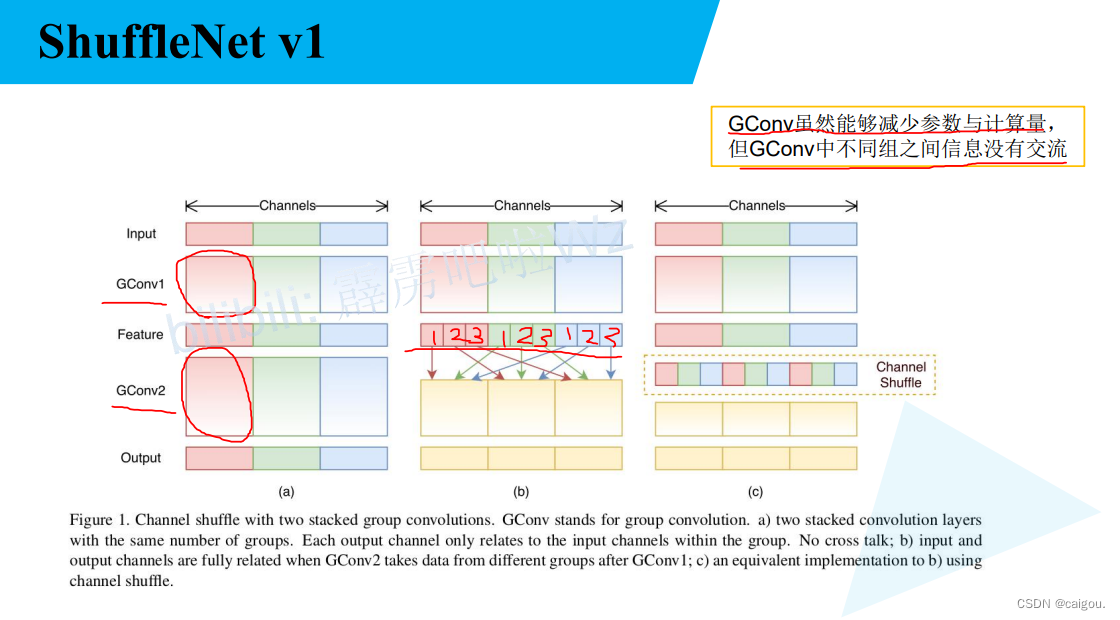
a是resnet模块,b,c是ShuffleNetV1的block,在V1版中,两模块branch2的第一个1*1卷积依然是类似MobileNet中的组卷积,减少参数量,之后有一个channel shuaffle操作,之后是类似MobileNet的DW卷积,之后进行1*1的GConv,b进行的是相加操作,d进行的是堆叠操作。
注意:b模块对应的是s=1的情况,c模块对应的是s=2的情况,具体参数后续参数表查看。

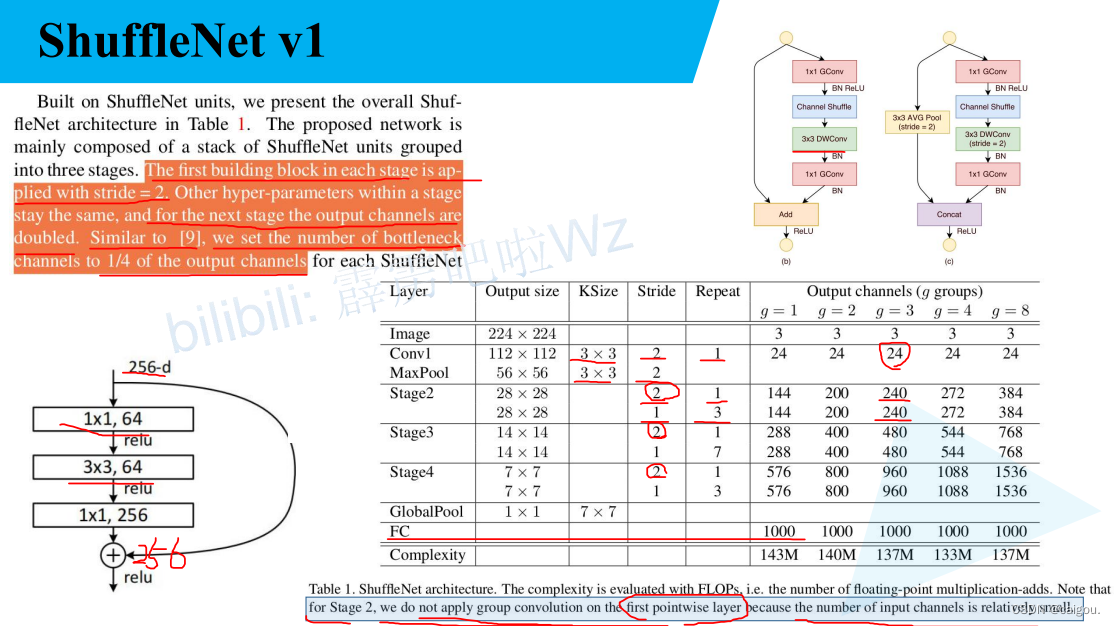
V1的模型参数表,一般选择g=3的情况。注意,stage2,3,4开始s=2,使用c模块,第二个s=1,使用b模块的block,repeat参数表示每个步距对应的模块的重复次数。其他参数容易理解。
还有g=3的输出通道给出了,没给出的是隐藏层的,也就是GConv 1*1卷积维度变换的参数,这个参数借鉴的是resnet,也就是降维成输出矩阵通道数的1/4,比如Stage2输出通道数是240,里面模块的1*1GCon降维参数是60.
FLOPs对比:(resnet,resnext,shuffleNet),FLOPs是浮点运算数,理解为计算量,下面是对比。
注意,V2的论文中提出不能一味追求FLOPs,针对这个又进行了一系列设计。

V2

如下图,shuffleNet模型的卷积运算时间占比。

如下图,V2论文给出的深度学习模型的设计策略,主要是一个平衡,都是作者在论文里经过实验验证的,G1 是说在FLOPs相同情况下,模块输入通道和输出通道比值越接近1,MAC(memory access cost 内存访问时间成本)越小,G2 策略是FLOPs一样,groups越大,单位时间推理的Batch越少,所以不能因为追求较少的参数groups设置的过大, G3 策略是网络设计碎片化程度越高,运行速度越慢,虽然比如googLeNet的Inception模块提高了准确率,但多分支会降低运行速度(卷积核的启动等待时间等变长),G4 策略是说Relu,Add Tensor,Add bias等操作 会增大模型推理时间。

针对以上的模型设计策略,作者给出了按照上述策略设计的ShuffleNetV2模型。
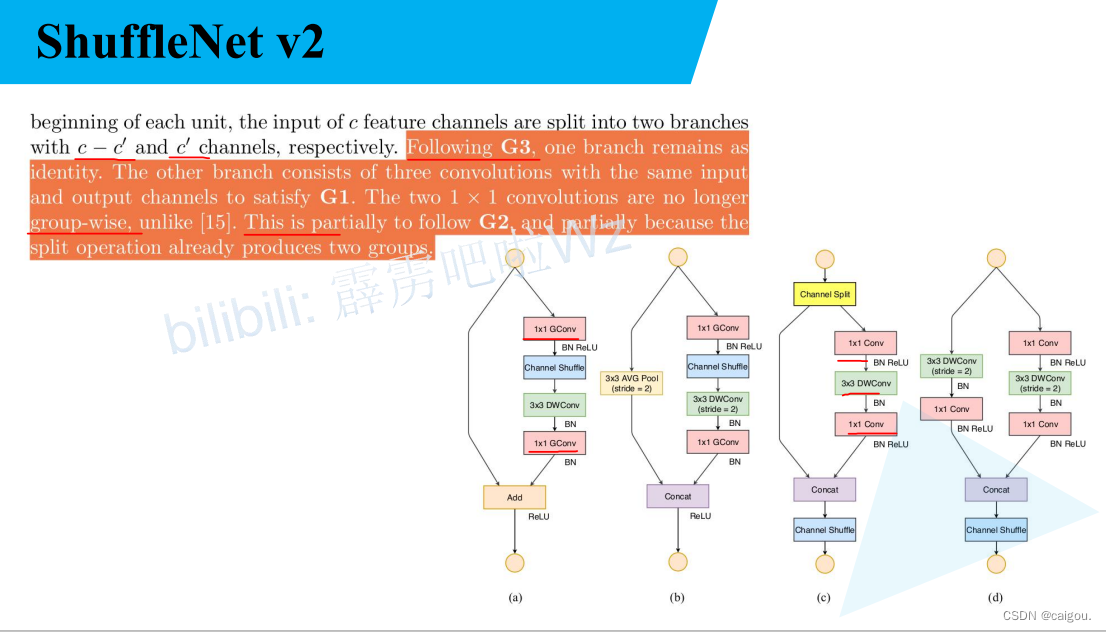
如下图,a,b是V1的block,c,d是V2的block。符合上述设计策略的用法:
G1 :c,d中输入通道和输出通道设计的一样,且两个分支每个分支各占c/2,最后拼接。
G2: 1*1的通道变换卷积不再用GConv,改用普通的Conv
G3: 分支尽量少
G4: 在V1 (a,b模块)中Relu是对两分支合并后激活,在V2中只对branch2进行激活。
整体上V2和V1 框架相似,channel shuffle位置不一样。
性能对比:

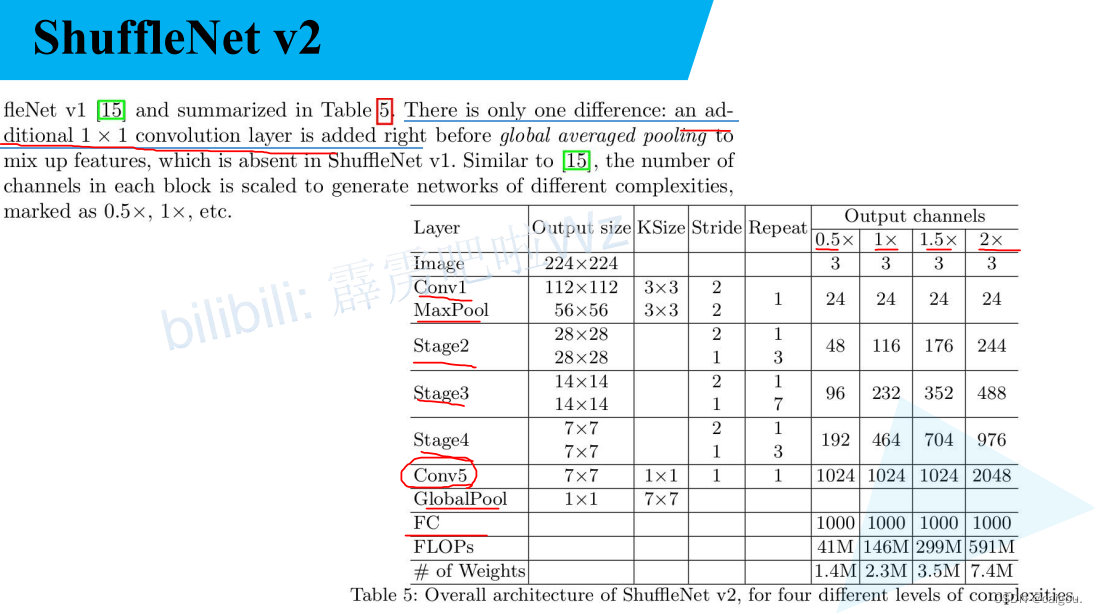
ShuffleNetV2 参数表:
0.5×,1×,1.5×,2×对应的是不同的参数(输出通道数)版本。
在下述代码中用的是1×版本,其他版本也可以定义
model.py
这个文件要注意的是V2中只要求c模块输入输出通道数一致,d模块不要求,只有这样才能用d模块进行通道变换,模型才能往下运行。
from typing import List, Callable
import torch
from torch import Tensor
import torch.nn as nn
def channel_shuffle(x: Tensor, groups: int) -> Tensor:
#注意,这是一个函数,输入张量x,对x通道进行重新组合后返回x
batch_size, num_channels, height, width = x.size()
channels_per_group = num_channels // groups
# reshape
# [batch_size, num_channels, height, width] -> [batch_size, groups, channels_per_group, height, width]
x = x.view(batch_size, groups, channels_per_group, height, width)
#对分组维度和通道维度进行交换,实现通道分组的重新组合,
#调用 .contiguous() 方法可以将张量转换为连续存储的形式,以便后续操作能够高效地进行
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batch_size, -1, height, width)
return x
class InvertedResidual(nn.Module):
#这个类是构造倒残差块的,也就是shuffleNet的基础模块,这里直接实现两个基础模块,只是V2的两个基础模块
def __init__(self, input_c: int, output_c: int, stride: int):
super(InvertedResidual, self).__init__()
#stride参数在这个模型里只能是1,2
if stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.stride = stride
#参数表中输出通道都是双数
assert output_c % 2 == 0
#V2模块的每个分支都是一半的输出通道数
branch_features = output_c // 2
# 当stride为1时,input_channel应该是branch_features的两倍
# python中 '<<' 是位运算,可理解为计算×2的快速方法
#步长为1是c模块,步长为2是d模块,
#在V2版本中,要求每个block的输入通道和输出通道是一样的,branch_features是输出通道一半,乘2判断是否输入输出通道一致
#s=2时候,是c模块,直接往下走就行,s=1时候就是不满足的,再判断一下输入输出通道是否一样
#注意这是断言语句,or前后任意一个条件满足,都继续向下执行
assert (self.stride != 1) or (input_c == branch_features << 1)
#s=2是d模块
if self.stride == 2:
self.branch1 = nn.Sequential(
#depthwise_conv 就是一个DW卷积,
self.depthwise_conv(input_c, input_c, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(input_c),
#下一句代码可以看出上面的DW卷积也就是d模块的DW卷积用的输入通道还是模块的输入通道,降成一半是在下面的1*1卷积来做的
#从结构图上可以看出来c模块是有一个模块分割操作的,也就是输入到每个分支上的已经是输入模块通道数的一半了
nn.Conv2d(input_c, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
else: #否则就是c模块的branch1
self.branch1 = nn.Sequential()
self.branch2 = nn.Sequential(
#c,d模块的每个分支的输入通道数是不一样的,需要进行判断
nn.Conv2d(input_c if self.stride > 1 else branch_features, branch_features, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
#DW卷积
self.depthwise_conv(branch_features, branch_features, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
@staticmethod
def depthwise_conv(input_c: int,
output_c: int,
kernel_s: int,
stride: int = 1,
padding: int = 0,
bias: bool = False) -> nn.Conv2d:
return nn.Conv2d(in_channels=input_c, out_channels=output_c, kernel_size=kernel_s,
stride=stride, padding=padding, bias=bias, groups=input_c)
#一个模块的前向传播,在结构图中,可以看出Stage2,3,4都是包括c,d两个模块的
def forward(self, x: Tensor) -> Tensor:
if self.stride == 1:
#如果s=1使用c模块,直接均分通道维度
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
#c,d模块,也就是V2的两个模块都是在拼接完成后进行通道重组的,通道重组后再进入下一个模块后就是重组的通道了
#可以对重组的通道进行操作
return out
class ShuffleNetV2(nn.Module):
def __init__(self,
stages_repeats: List[int], #每个stage的c,d模块数量和
stages_out_channels: List[int], #五层对应的输出通道数
num_classes: int = 1000,
inverted_residual: Callable[..., nn.Module] = InvertedResidual):
super(ShuffleNetV2, self).__init__()
if len(stages_repeats) != 3: #只有3个stage
raise ValueError("expected stages_repeats as list of 3 positive ints")
if len(stages_out_channels) != 5: #五个层输出通道数
raise ValueError("expected stages_out_channels as list of 5 positive ints")
#获取一下输入的每层输出通道数列表
self._stage_out_channels = stages_out_channels
# input RGB image
#这个下面的根据参数表来看
input_channels = 3
output_channels = self._stage_out_channels[0]
self.conv1 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
input_channels = output_channels # 第一遍运行shufflenet_v2_x1_0,input_channels=output_channels=24
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# Static annotations for mypy
#定义stage,每个步骤都是一个模型序列类型
self.stage2: nn.Sequential
self.stage3: nn.Sequential
self.stage4: nn.Sequential
#stages名字列表
stage_names = ["stage{}".format(i) for i in [2, 3, 4]]
#遍历构造所有satge
for name, repeats, output_channels in zip(stage_names, stages_repeats,
self._stage_out_channels[1:]):
#self._stage_out_channels[1:]这个切片操作去掉了Conv1层的输出通道数,因前面已经构建了 self.conv1层
#通过将 inverted_residual(input_channels, output_channels, 2) 的返回值放入列表 seq 中,创建了一个包含一个模块的序列
#下面这句代码先添加了第一个步距为2的block_d,d并不要求输入输出通道数一致,用来改变通道数,其他block都是c_block
seq = [inverted_residual(input_channels, output_channels, 2)]
for i in range(repeats - 1): #遍历添加stage中每个模块
#将一个名为 inverted_residual 的函数返回的模块添加到列表 seq 中
#本来应该conv1后输出通道是24,这个属于模型构建,先不管这个不匹配的情况,接着往下看
seq.append(inverted_residual(output_channels, output_channels, 1)) #(116,116,1)
#在对象 self 上设置属性 name 的值为 nn.Sequential(*seq)
setattr(self, name, nn.Sequential(*seq))
input_channels = output_channels #上一层的输出是下一层的输入,这样就构建了3个stage的模块
#取出Conv5这一层的输出,上面已经把stage4的输出给了input_channels
output_channels = self._stage_out_channels[-1]
self.conv5 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
self.fc = nn.Linear(output_channels, num_classes)
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.conv5(x)
x = x.mean([2, 3]) # global pool,得到[batch_size,output_channels]
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def shufflenet_v2_x0_5(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 0.5x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x0.5-f707e7126e.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 48, 96, 192, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_0(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x1-5666bf0f80.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
#stages_repeats是Stages2,3,4每个步骤中c+d的模块数量,分别是4,8,4
#而且从结构图可以看出来Stage2,3,4的第一个模块步长都是1,也就是说用的是c模块
#stages_out_channels是Conv1,Stage2,3,4,Conv5五个层的输出通道数
stages_out_channels=[24, 116, 232, 464, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_5(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x1_5-3c479a10.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 176, 352, 704, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x2_0(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x2_0-8be3c8ee.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 244, 488, 976, 2048],
num_classes=num_classes)
return model
train.py
import os
import math
import argparse
import torch
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import torch.optim.lr_scheduler as lr_scheduler
from model import shufflenet_v2_x1_0
from my_dataset import MyDataSet
from utils import read_split_data, train_one_epoch, evaluate
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
print(args)
print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')
tb_writer = SummaryWriter()
if os.path.exists("./weights") is False:
os.makedirs("./weights")
#拆分总的图片文件夹下的 训练图片路径列表 对应的类别索引列表 验证图片文件路径列表 验证图片类别索引列表
train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 实例化训练数据集
# 之后传入DataLoader中的数据集包含图片和对应标签,定义数据集时就要传入,自定义数据集进行返回
# 这里要区别ImageFolder这个官方提供的数据定义类,这个类只需要数据集根目录,自动生成对应的类别,
# ImageFolder有一个默认的类别和图片的文件结构
train_dataset = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_dataset = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_dataset.collate_fn)
# 如果存在预训练权重则载入
# 实例化模型只需要传入一个类别数量即可,前面构建模型需要的参数在定义模型时已经给出
model = shufflenet_v2_x1_0(num_classes=args.num_classes).to(device)
if args.weights != "":
if os.path.exists(args.weights):
weights_dict = torch.load(args.weights, map_location=device)
load_weights_dict = {k: v for k, v in weights_dict.items()
if model.state_dict()[k].numel() == v.numel()}
print(model.load_state_dict(load_weights_dict, strict=False))
else:
raise FileNotFoundError("not found weights file: {}".format(args.weights))
# 是否冻结权重
if args.freeze_layers:
for name, para in model.named_parameters():
# 除最后的全连接层外,其他权重全部冻结
if "fc" not in name:
para.requires_grad_(False)
# pg是需要训练的参数列表,这行代码获取了需要进行梯度更新的模型参数
pg = [p for p in model.parameters() if p.requires_grad]
# 动量和权重衰减
optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=4E-5)
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
# lf是一个Lambda函数,用于计算学习率调度的值。具体计算方式是通过余弦函数来调整学习率,在训练过程中学习率呈现余弦形状的变化。
lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosine
# 调用lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)创建了一个LambdaLR学习率调度器,并将其与优化器进行关联
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
for epoch in range(args.epochs):
# train 这是一个epoch调用train_one_epoch 函数训练一次
mean_loss = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
# 学习率更新
scheduler.step()
# validate
acc = evaluate(model=model,
data_loader=val_loader,
device=device)
# 每训练一轮打印一次,
# 对于进度条上每训练一批更新一次的参数已经在train_one_epoch()函数里有体现
print("[epoch {}] accuracy: {}".format(epoch, round(acc, 3)))
#这段代码的作用是将训练过程中的损失、准确率和学习率等指标记录到TensorBoard中,以便后续可视化和分析训练过程的变化。
tags = ["loss", "accuracy", "learning_rate"]
tb_writer.add_scalar(tags[0], mean_loss, epoch)
tb_writer.add_scalar(tags[1], acc, epoch)
tb_writer.add_scalar(tags[2], optimizer.param_groups[0]["lr"], epoch)
torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch))
if __name__ == '__main__':
#使用这种设计可以方便的更改模型的一些训练超参数,方便对训练的调整。
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=5)
parser.add_argument('--epochs', type=int, default=30)
parser.add_argument('--batch-size', type=int, default=16)
parser.add_argument('--lr', type=float, default=0.01)
parser.add_argument('--lrf', type=float, default=0.1)
# 数据集所在根目录
# https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
parser.add_argument('--data-path', type=str,
default="../../data_set/flower_data/flower_photos")
#注意,这个训练脚本用的是总的flower_photos,不是之前差分训练集,验证集后的文件路径
# shufflenetv2_x1.0 官方权重下载地址
# https://download.pytorch.org/models/shufflenetv2_x1-5666bf0f80.pth
parser.add_argument('--weights', type=str, default='./shufflenetv2_x1-pre.pth',
help='initial weights path')
parser.add_argument('--freeze-layers', type=bool, default=False)
parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')
opt = parser.parse_args()
main(opt)
训练代码里用到的自定义数据集类代码与理解:
相比之前的一些模型直接用官方提供的ImageFolder来定义数据集,其他文件结构的需要自定义数据集,类比ImageFolder,这个自定义数据集需要传入的参数是一个文件路径,一个预处理集合序列。下面是ImageFolder的使用:
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])这个ImageFolder的具体理解:
使用 ImageFolder 类加载图像数据集时,它会根据子目录的名称自动为每个类别分配一个唯一的索引。这些索引值是从 0 开始递增的整数。
例如,如果数据集的目录结构如下:
root/class_1/image_1.jpg
root/class_1/image_2.jpg
...
root/class_2/image_1.jpg
root/class_2/image_2.jpg
...这个使用直接划分出train,val文件,每个文件里对应有类别文件夹,每类别文件夹里有图片,ImageFolder直接获取传入路径下每个类别文件夹里的图片和图片所在文件夹的索引,这个索引就是类别,就是对应文件夹所代表的类的索引。
根据以上分析,自定义数据集要包括传入的路径参数,直接看代码分析:
使用自定义数据集:
train_dataset = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])这里的train_images_path 和 rain_images_label 是用下面这个函数生成的
train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)这个函数在utils.py中如下代码,这个里面还包括接下来训练epoch中的训练部分函数和验证部分函数,传入一个根目录,一个验证集划分比例,直接对根目录下的每个类别文件夹里的图片划分训练集验证集形成路径列表,根据遍历每个cla文件夹的cla生成图片的对应标签,最后对训练验证的图片路径列表及对应标签进行返回。
utls.py
import os
import sys
import json
import pickle
import random
import torch
from tqdm import tqdm
import matplotlib.pyplot as plt
def read_split_data(root: str, val_rate: float = 0.2):
random.seed(0) # 保证随机结果可复现
assert os.path.exists(root), "dataset root: {} does not exist.".format(root)
# 遍历文件夹,一个文件夹对应一个类别
#先连接root和cla,再判断是否是一个目录,因为 os.listdir(root)返回的是所有文件,不仅文件夹
flower_class = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root, cla))]
# 排序,保证各平台顺序一致
flower_class.sort()
# 生成类别名称以及对应的数字索引,
# 键(key)是花卉类别的名称,值(value)是对应的索引值,
class_indices = dict((k, v) for v, k in enumerate(flower_class))
#进行调换,生成索引,类别形式
json_str = json.dumps(dict((val, key) for key, val in class_indices.items()), indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
train_images_path = [] # 存储训练集的所有图片路径
train_images_label = [] # 存储训练集图片对应索引信息
val_images_path = [] # 存储验证集的所有图片路径
val_images_label = [] # 存储验证集图片对应索引信息
every_class_num = [] # 存储每个类别的样本总数
supported = [".jpg", ".JPG", ".png", ".PNG"] # 支持的文件后缀类型
# 遍历每个文件夹下的文件
for cla in flower_class:
cla_path = os.path.join(root, cla)
# 遍历获取supported支持的所有 文件路径,images是一个文件路径列表
#splitext 是 os.path 模块中的一个函数,用于拆分文件路径中的文件名和扩展名。
images = [os.path.join(root, cla, i) for i in os.listdir(cla_path)
if os.path.splitext(i)[-1] in supported]
# 排序,保证各平台顺序一致
images.sort()
# 获取该类别对应的索引,class_indices是前面生成的字典
image_class = class_indices[cla]
# 记录该类别的样本数量
every_class_num.append(len(images))
# 按比例随机采样验证样本,这个images遍历每个类别的花文件夹会生成一个新的变量,
# 因为images就是一个局部变量
#所以iamges只是当前类别文件夹下的文件路径列表
#存储所有图片路径用的是 train_images_path = [] 这些之前定义的全局变量
val_path = random.sample(images, k=int(len(images) * val_rate))
for img_path in images:
if img_path in val_path: # 如果该路径在采样的验证集样本中则存入验证集
val_images_path.append(img_path)
val_images_label.append(image_class)
else: # 否则存入训练集
train_images_path.append(img_path)
train_images_label.append(image_class)
print("{} images were found in the dataset.".format(sum(every_class_num)))
print("{} images for training.".format(len(train_images_path)))
print("{} images for validation.".format(len(val_images_path)))
assert len(train_images_path) > 0, "number of training images must greater than 0."
assert len(val_images_path) > 0, "number of validation images must greater than 0."
plot_image = False
if plot_image:
# 绘制每种类别个数柱状图
plt.bar(range(len(flower_class)), every_class_num, align='center')
# 将横坐标0,1,2,3,4替换为相应的类别名称
plt.xticks(range(len(flower_class)), flower_class)
# 在柱状图上添加数值标签,every_class_num是一个包含每类图片个数的列表
for i, v in enumerate(every_class_num):
plt.text(x=i, y=v + 5, s=str(v), ha='center')
# 设置x坐标
plt.xlabel('image class')
# 设置y坐标
plt.ylabel('number of images')
# 设置柱状图的标题
plt.title('flower class distribution')
plt.show()
return train_images_path, train_images_label, val_images_path, val_images_label
def plot_data_loader_image(data_loader):
batch_size = data_loader.batch_size
plot_num = min(batch_size, 4)
json_path = './class_indices.json'
assert os.path.exists(json_path), json_path + " does not exist."
json_file = open(json_path, 'r')
class_indices = json.load(json_file)
for data in data_loader:
images, labels = data
for i in range(plot_num):
# [C, H, W] -> [H, W, C]
img = images[i].numpy().transpose(1, 2, 0)
# 反Normalize操作
img = (img * [0.229, 0.224, 0.225] + [0.485, 0.456, 0.406]) * 255
label = labels[i].item()
plt.subplot(1, plot_num, i+1)
plt.xlabel(class_indices[str(label)])
plt.xticks([]) # 去掉x轴的刻度
plt.yticks([]) # 去掉y轴的刻度
plt.imshow(img.astype('uint8'))
plt.show()
def write_pickle(list_info: list, file_name: str):
with open(file_name, 'wb') as f:
pickle.dump(list_info, f)
def read_pickle(file_name: str) -> list:
with open(file_name, 'rb') as f:
info_list = pickle.load(f)
return info_list
def train_one_epoch(model, optimizer, data_loader, device, epoch):
model.train()
loss_function = torch.nn.CrossEntropyLoss()
mean_loss = torch.zeros(1).to(device)
#梯度清零
optimizer.zero_grad()
data_loader = tqdm(data_loader, file=sys.stdout)
# 传入的data_loader是train_loader
# 按批次取数据
for step, data in enumerate(data_loader):
images, labels = data
pred = model(images.to(device))
loss = loss_function(pred, labels.to(device))
loss.backward()
# 计算了平均损失(mean_loss)。假设在训练过程中有多个批次(step),每个批次计算得到一个损失值(loss)。
# 代码中使用了移动平均的方法来更新平均损失。
# mean_loss * step:当前平均损失乘前面的step表示前面总损失,再加 loss.detach()本次的损失,获取所有step的平均损失
mean_loss = (mean_loss * step + loss.detach()) / (step + 1) # update mean losses
# 这是一个进度条显示的设置
data_loader.desc = "[epoch {}] mean loss {}".format(epoch, round(mean_loss.item(), 3))
# 这段代码用于检查损失(loss)是否为有限值(finite)。
# 在深度学习训练过程中,如果损失出现非有限值(如NaN或无穷大),通常表示训练过程出现了异常情况,需要进行调试和排查。
if not torch.isfinite(loss):
print('WARNING: non-finite loss, ending training ', loss)
sys.exit(1)
optimizer.step()
optimizer.zero_grad()
return mean_loss.item()
@torch.no_grad()
def evaluate(model, data_loader, device):
model.eval()
# 验证样本总个数
total_num = len(data_loader.dataset)
# 用于存储预测正确的样本个数
sum_num = torch.zeros(1).to(device)
data_loader = tqdm(data_loader, file=sys.stdout)
# 传入的 data_loader 是 val_loader
for step, data in enumerate(data_loader):
images, labels = data
pred = model(images.to(device))
pred = torch.max(pred, dim=1)[1]
sum_num += torch.eq(pred, labels.to(device)).sum()
return sum_num.item() / total_num
自定义数据集:
这个自定义数据集的输入是一个train_images_path列表,也就是包含每个图片路径的列表,image_class,也就是包含对应标签的列表,里面要有初始化函数,获取长度的函数,以及getitem函数,getitem函数用于 torch.utils.data.DataLoader() 传入数据集参数时进行迭代获取图片及对应的标签。
,
from PIL import Image
import torch
from torch.utils.data import Dataset
class MyDataSet(Dataset):
"""自定义数据集"""
def __init__(self, images_path: list, images_class: list, transform=None):
self.images_path = images_path
self.images_class = images_class
self.transform = transform
def __len__(self):
return len(self.images_path)
def __getitem__(self, item):
img = Image.open(self.images_path[item])
# RGB为彩色图片,L为灰度图片
if img.mode != 'RGB':
raise ValueError("image: {} isn't RGB mode.".format(self.images_path[item]))
label = self.images_class[item]
if self.transform is not None:
img = self.transform(img)
return img, label
@staticmethod
def collate_fn(batch):
# 官方实现的default_collate可以参考
# https://github.com/pytorch/pytorch/blob/67b7e751e6b5931a9f45274653f4f653a4e6cdf6/torch/utils/data/_utils/collate.py
images, labels = tuple(zip(*batch))
images = torch.stack(images, dim=0)
labels = torch.as_tensor(labels)
return images, labels
训练结果:使用官方提供的shuffleNetV2的1×版本的权重:这个官方权重文件的大小相比resnet这些是很小的,只有8.8M,这也是模型研究的一个主要意义所在。看训练部分代码可知每个epoch生成的权重文件放在一个文件夹下。
Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/
3670 images were found in the dataset.
2939 images for training.
731 images for validation.
Using 8 dataloader workers every process
_IncompatibleKeys(missing_keys=['fc.weight', 'fc.bias'], unexpected_keys=[])
[epoch 0] mean loss 1.513: 100%|██████████| 184/184 [00:28<00:00, 6.35it/s]
100%|██████████| 46/46 [00:18<00:00, 2.43it/s]
[epoch 0] accuracy: 0.587
[epoch 1] mean loss 0.966: 100%|██████████| 184/184 [00:26<00:00, 6.97it/s]
100%|██████████| 46/46 [00:18<00:00, 2.48it/s]
[epoch 1] accuracy: 0.888
[epoch 2] mean loss 0.525: 100%|██████████| 184/184 [00:26<00:00, 7.00it/s]
100%|██████████| 46/46 [00:18<00:00, 2.45it/s]
[epoch 2] accuracy: 0.903
[epoch 3] mean loss 0.44: 100%|██████████| 184/184 [00:26<00:00, 7.07it/s]
100%|██████████| 46/46 [00:18<00:00, 2.54it/s]
[epoch 3] accuracy: 0.914
[epoch 4] mean loss 0.409: 100%|██████████| 184/184 [00:25<00:00, 7.13it/s]
100%|██████████| 46/46 [00:18<00:00, 2.47it/s]
[epoch 4] accuracy: 0.921
[epoch 5] mean loss 0.323: 100%|██████████| 184/184 [00:26<00:00, 6.99it/s]
100%|██████████| 46/46 [00:18<00:00, 2.48it/s]
[epoch 5] accuracy: 0.925
[epoch 6] mean loss 0.318: 100%|██████████| 184/184 [00:25<00:00, 7.10it/s]
100%|██████████| 46/46 [00:18<00:00, 2.43it/s]
[epoch 6] accuracy: 0.925
[epoch 7] mean loss 0.315: 100%|██████████| 184/184 [00:26<00:00, 7.01it/s]
100%|██████████| 46/46 [00:24<00:00, 1.85it/s]
[epoch 7] accuracy: 0.895
[epoch 8] mean loss 0.287: 100%|██████████| 184/184 [00:26<00:00, 6.96it/s]
100%|██████████| 46/46 [00:18<00:00, 2.49it/s]
[epoch 8] accuracy: 0.938
[epoch 9] mean loss 0.252: 100%|██████████| 184/184 [00:26<00:00, 6.96it/s]
100%|██████████| 46/46 [00:18<00:00, 2.52it/s]
[epoch 9] accuracy: 0.934
[epoch 10] mean loss 0.293: 100%|██████████| 184/184 [00:26<00:00, 6.97it/s]
100%|██████████| 46/46 [00:18<00:00, 2.43it/s]
[epoch 10] accuracy: 0.927
[epoch 11] mean loss 0.231: 100%|██████████| 184/184 [00:26<00:00, 6.99it/s]
100%|██████████| 46/46 [00:18<00:00, 2.47it/s]
[epoch 11] accuracy: 0.937
[epoch 12] mean loss 0.215: 100%|██████████| 184/184 [00:26<00:00, 6.99it/s]
100%|██████████| 46/46 [00:18<00:00, 2.50it/s]
[epoch 12] accuracy: 0.933
[epoch 13] mean loss 0.223: 100%|██████████| 184/184 [00:26<00:00, 7.05it/s]
100%|██████████| 46/46 [00:18<00:00, 2.50it/s]
[epoch 13] accuracy: 0.934
[epoch 14] mean loss 0.19: 100%|██████████| 184/184 [00:26<00:00, 6.97it/s]
100%|██████████| 46/46 [00:18<00:00, 2.47it/s]
[epoch 14] accuracy: 0.945
[epoch 15] mean loss 0.182: 100%|██████████| 184/184 [00:26<00:00, 7.04it/s]
100%|██████████| 46/46 [00:18<00:00, 2.48it/s]
[epoch 15] accuracy: 0.937
[epoch 16] mean loss 0.201: 100%|██████████| 184/184 [00:26<00:00, 6.99it/s]
100%|██████████| 46/46 [00:18<00:00, 2.47it/s]
[epoch 16] accuracy: 0.938
[epoch 17] mean loss 0.162: 100%|██████████| 184/184 [00:26<00:00, 7.04it/s]
100%|██████████| 46/46 [00:18<00:00, 2.50it/s]
[epoch 17] accuracy: 0.932
[epoch 18] mean loss 0.168: 100%|██████████| 184/184 [00:26<00:00, 7.05it/s]
100%|██████████| 46/46 [00:18<00:00, 2.49it/s]
[epoch 18] accuracy: 0.944
[epoch 19] mean loss 0.162: 100%|██████████| 184/184 [00:26<00:00, 6.95it/s]
100%|██████████| 46/46 [00:18<00:00, 2.50it/s]
[epoch 19] accuracy: 0.945
[epoch 20] mean loss 0.161: 100%|██████████| 184/184 [00:26<00:00, 6.97it/s]
100%|██████████| 46/46 [00:18<00:00, 2.48it/s]
[epoch 20] accuracy: 0.952
[epoch 21] mean loss 0.16: 100%|██████████| 184/184 [00:26<00:00, 6.90it/s]
100%|██████████| 46/46 [00:18<00:00, 2.43it/s]
[epoch 21] accuracy: 0.945
[epoch 22] mean loss 0.155: 100%|██████████| 184/184 [00:26<00:00, 7.01it/s]
100%|██████████| 46/46 [00:18<00:00, 2.50it/s]
[epoch 22] accuracy: 0.943
[epoch 23] mean loss 0.131: 100%|██████████| 184/184 [00:26<00:00, 7.00it/s]
100%|██████████| 46/46 [00:18<00:00, 2.52it/s]
[epoch 23] accuracy: 0.941
[epoch 24] mean loss 0.148: 100%|██████████| 184/184 [00:26<00:00, 7.02it/s]
100%|██████████| 46/46 [00:18<00:00, 2.46it/s]
[epoch 24] accuracy: 0.947
[epoch 25] mean loss 0.141: 100%|██████████| 184/184 [00:26<00:00, 6.93it/s]
100%|██████████| 46/46 [00:18<00:00, 2.50it/s]
[epoch 25] accuracy: 0.951
[epoch 26] mean loss 0.128: 100%|██████████| 184/184 [00:26<00:00, 6.97it/s]
100%|██████████| 46/46 [00:18<00:00, 2.45it/s]
[epoch 26] accuracy: 0.945
[epoch 27] mean loss 0.125: 100%|██████████| 184/184 [00:26<00:00, 6.98it/s]
100%|██████████| 46/46 [00:18<00:00, 2.49it/s]
[epoch 27] accuracy: 0.945
[epoch 28] mean loss 0.123: 100%|██████████| 184/184 [00:26<00:00, 6.98it/s]
100%|██████████| 46/46 [00:18<00:00, 2.48it/s]
[epoch 28] accuracy: 0.947
[epoch 29] mean loss 0.122: 100%|██████████| 184/184 [00:26<00:00, 7.04it/s]
100%|██████████| 46/46 [00:18<00:00, 2.48it/s]
[epoch 29] accuracy: 0.949predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import shufflenet_v2_x1_0
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
img_path = "./test.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = shufflenet_v2_x1_0(num_classes=5).to(device)
# load model weights
model_weight_path = "./weights/model-29.pth"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()
验证结果:
class: daisy prob: 0.00012
class: dandelion prob: 1.16e-05
class: roses prob: 0.000124
class: sunflowers prob: 0.000508
class: tulips prob: 0.999
Process finished with exit code 0




![[ 8 种有效方法] 如何在没有备份的情况下恢复 Android 上永久删除的照片?](https://img-blog.csdnimg.cn/direct/8b2d752b89814d5db5ff1410dc314ac9.png)