(一)POM模式介绍
1、什么是POM?
POM是Page Object Model页面对象模型的简称。
POM是为Web UI元素创建Object Repository的设计模式 。
在这个模型下,对于应用程序中的每个网页,应该有相应的页面类。
此Page类将会找到该Web页面的WebElements,并且还包含对这些WebElements执行操作的页面方法。
POM设计模式旨在为每个待测试的页面创建一个页面对象,将那些繁琐的定位操作封装到这个页面对象中,只对外提供必要的操作接口,是一种封装思想。
白话总结:
我们所做的自动化测试,就是模拟人在浏览器上的操作。而自动化测试中操作所有的元素的步骤,无非就是先定位到页面的各种元素,然后在模拟各种对元素执行的操作。
而我们大量的工作都用在定位元素上,定位元素的方式有很多中,定位起来也非常的繁琐。如果将这些代码全部放在代码中,不去好好的管理,代码会显示非常的冗余,而且不容易维护。所以将这些繁琐的定位,封装到一些页面对象中,用例只需要去调用就可以了。
2、为什么要使用POM模式
少数的自动化测试用例维护起来看起来是很容易的。但随着时间的迁移,测试套件将持续的增长脚本也将变得越来越臃肿庞大。如果变成我们需要维护10个页面,100个页面,甚至1000个呢?而且页面元素很多是公用的,所以页面元素的任何改变都会让我们的脚本维护变得繁琐复杂,而且变得耗时易出错。
也就是说页面中有一个按钮"元素A"。该元素A在十个测试用例中都被用到了,如果元素A被前端更新了,我就要去修改这十个自动化用例所用道元素A的地方。如果有100个、1000个用例用到了元素A,那我可就疯了。
而POM设计模式,会把公共的元素抽取出来,该元素被前端修改,只需要更新该元素的定位方式即可,用例不需要改动。换句话说,不管我多少测试用例,用到了该元素,我只重新修改元素的定位方式,重新能够获得该元素即可。
3、POM的优势
在自动化测试中,引入了Page Object Model(POM):页面对象模式,能让我们的测试代码变得可读性更好,高可维护性,高复用性。
还有如下优势:
- 让Ul自动化更早介入项目中,可项目开发完再进行元素定位的适配与调试。
换句话说元素定位器分离出来写,最后根据前端开发出来的页面,再根据页面编写编写元素定位器,前期可以做一些其他的工作。 - POM设计模式将页面元素定位和业务操作流程分开,分离了测试对象和测试脚本(对象库与用例分离),使得我们更好的复用测试对象。
- 如果Ul页面元素更改,测试脚本不需要更改,只需要更改页面对象中的某些代码就可以。
- POM设计模式能让我们的测试代码变得更加优化,提高了可读性,可维护性,可复用性。
- 可多人共同维护开发脚本,利于团队协作。
4、POM模式封装思路
(1)POM模式将页面分成三层
- 表现层
页面中可见的元素,都属于表现层。(元素定位器的编写) - 操作层
对页面可见元素的操作。点击、输入、拖拽等。 - 业务层
在页面中对若干元素操作后所实现的功能。(就是测试用例)
(2)POM模式的核心要素(重点)
- 在POM模式中将公共方法统一封装成到一个BasePage 类中,换句话说该基类对Selenium的常用操作做二次封装。
- 每个页面对应一个page类,page类都需要继承 BasePage,通过 driver 来管理本page类中的元素,并将page类中的操作封装成一个个的方法。
换句话说,就是page类中封装页面表现层和操作层。 TestCase继承unittest.Testcase类,并且依赖 page 类,从而实现相应的测试步骤。
(3)总结
就是按照系统或模块 —> 其中包含哪些被测页面 —> 页面中的哪些元素
换句话说,元素被页面管理,页面被模块管理。
- 根据页面来进行管理例
例如:测式xx页面,需要用到的元素,把所有的元素定位器编写出来。 - 页面根据系统或者模块来管理例如:
例如:xx系统或模块,涉及到哪几个页面元素
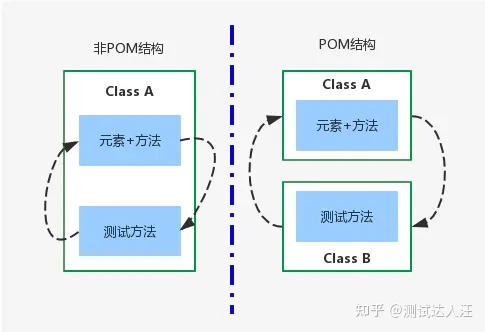
(4)非POM和POM对比图
(5)POM设计模式核心架构图

5、对POM小结:
- POM是
selenium webdriver自动化测试实践对象库设计模式。 - POM使得测试脚本更易于维护。
- POM通过对象库方式进一步优化了元素、用例、数据的维护组织。
(二)将普通的Selenium代码封装成POM模式
1、案例说明:
这里只是提供一种封装的思路,小伙伴们可以根据自己的实际情况,按需封装。
以下是简单普通的登录测试用例
# 1. 导入包
from selenium import webdriver
import time
# 2. 打开谷歌浏览器(获取浏览器操作对象)
driver = webdriver.Chrome()
# 3. 打开快递100网站
url = "https://sso.kuaidi100.com/sso/authorize.do"
driver.get(url)
time.sleep(3)
# 4. 登陆网站
driver.find_element_by_id("name").send_keys('xxxxxxxxxxx')
driver.find_element_by_id("password").send_keys('xxxxxx')
driver.find_element_by_id("submit").click()
time.sleep(3)
# 5. 关闭浏览器
driver.quit()那我们如何进行一个改造升级呢?
2、加入unittest测试框架
# 1. 导入包
from selenium import webdriver
import time
import unittest
# 定义测试类
class TestCaseLogin(unittest.TestCase):
def setUp(self) -> None:
"""
前置函数
用于打开浏览器,连接数据库,初始化数据等操作
"""
# 2. 打开谷歌浏览器(获取浏览器操作对象)
self.driver = webdriver.Chrome()
# 3. 打开快递100网站
url = "https://sso.kuaidi100.com/sso/authorize.do"
self.driver.get(url)
time.sleep(3)
def tearDown(self) -> None:
"""
后置函数
用于关闭浏览器,断开数据库连接,清理测试数据等操作
"""
# 5. 关闭浏览器
self.driver.quit()
def testLogin(self):
"""登陆测试用例"""
self.driver.find_element_by_id("name").send_keys('xxxxxxxxxxx')
self.driver.find_element_by_id("password").send_keys('xxxxxx')
self.driver.find_element_by_id("submit").click()
time.sleep(3)
if __name__ == '__main__':
unittest.main()如果有不清楚unittest测试框架的小伙伴可以查看我以前的unittest测试框架博客有4篇,简单易懂。
3、加入元素显示等待
我们上边的示例中,用的是固定的等待时间,我们需要有话一下代码的效率,加入元素的显示等待。
关于元素显示等待请看:元素等待的使用
Seleniun的EC模块:EC模块的使用
# 1. 导入包
from selenium import webdriver
import time
import unittest
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 定义测试类
class TestCaseLogin(unittest.TestCase):
def setUp(self) -> None:
"""
前置函数
用于打开浏览器,连接数据库,初始化数据等操作
"""
# 2. 打开谷歌浏览器(获取浏览器操作对象)
self.driver = webdriver.Chrome()
# 3. 打开快递100网站
url = "https://sso.kuaidi100.com/sso/authorize.do"
self.driver.get(url)
time.sleep(2)
def tearDown(self) -> None:
"""
后置函数
用于关闭浏览器,断开数据库连接,清理测试数据等操作
"""
# 5. 关闭浏览器
time.sleep(2)
self.driver.quit()
def testLogin(self):
"""登陆测试用例"""
# 编写定位器
name_input_locator = ("id", "name")
passwd_input_locator = ("id", "password")
submit_button_locator = ("id", "submit")
# 等待元素出现在操作元素
WebDriverWait(self.driver, 5).until(EC.visibility_of_element_located(name_input_locator))
WebDriverWait(self.driver, 5).until(EC.visibility_of_element_located(passwd_input_locator))
WebDriverWait(self.driver, 5).until(EC.visibility_of_element_located(submit_button_locator))
self.driver.find_element_by_id("name").send_keys('xxxxxxxxxxx')
self.driver.find_element_by_id("password").send_keys('xxxxxx')
self.driver.find_element_by_id("submit").click()
if __name__ == '__main__':
unittest.main()4、引入POM模式
我们发现上面的代码越来越乱,代码冗余,不利于维护,可读性差,不可复用。
(1)改造案例思路:
- 第一, 我们要分离测试对象(元素对象)和测试脚本(用例脚本),那么我们分别创建两个脚本文件,分别为:
LoginPage.py用于定义页面元素对象,每一个元素都封装成组件(可以看做存放页面元素对象的仓库)TestCaseLogin.py测试用例脚本。
- 第二,抽取出公共方法定义在
base.py文件中,每个Page类都要继承这个base.py文件,也就是每Page类都能使用base类中的方法,来操作页面中的元素,同时也可以在每个Page类中定义自己独有的方法,解决工作中的实际需求。 - 第三,设计实现思想,一切元素和元素的操作组件化定义在Page页面,用例脚本页面,通过调用Page中的组件对象,进行拼凑成一个登录脚本。
(2)封装公共操作在base类
把一些公共的方法放到此类中,这个类将被PO对象继承
"""
封装公共方法
"""
from selenium import webdriver
import time
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class Base:
def __init__(self, browser="chrome"):
"""
初始化driver
:param browser:浏览器名称
"""
if browser == "chrome":
self.driver = webdriver.Chrome()
elif browser == "firefox":
self.driver = webdriver.Firefox()
elif browser == "ie":
self.driver = webdriver.Ie()
else:
self.driver = None
print("请输入正确的浏览器,例如:chrome,firefox,ie")
def open_url(self, url):
"""
打开地址
:param url: 被测地址
:return:
"""
self.driver.get(url)
time.sleep(2)
def find_element(self, locator, timeout=10):
"""
定位单个元素,如果定位成功返回元素本身,如果失败,返回False
:param locator: 定位器,例如("id","id属性值")
:return: 元素本身
"""
try:
element = WebDriverWait(self.driver, timeout).until(EC.presence_of_element_located(locator))
return element
except:
print(f"{locator}元素没找到")
return False
def click(self, locator):
"""
点击元素
:return:
"""
element = self.find_element(locator)
element.click()
def send_keys(self, locator, text):
"""
元素输入
:param locator: 定位器
:param text: 输入内容
:return:
"""
element = self.find_element(locator)
element.clear()
element.send_keys(text)
def close(self):
"""
关闭浏览器
:return:
"""
time.sleep(2)
self.driver.quit()
if __name__ == '__main__':
base = Base()
base.open_url("https://sso.kuaidi100.com/sso/authorize.do")
base.close()(3)每个页面对应一个page类
定位元素的定位器和操作元素方法分离开,元素定位器全部放一起,然后每一个操作元素动作写成一个方法。
"""
管理登陆页面所有的元素,
以及操作这些元素所用的方法。
"""
from common.base import Base
class LoginPage(Base):
# 编写定位器和页面属性
name_input_locator = ("id", "name")
passwd_input_locator = ("id", "password")
submit_button_locator = ("id", "submit")
username = 'xxxxxxxxxxx'
userpasswd = 'xxxxxx'
url = 'https://sso.kuaidi100.com/sso/authorize.do'
# """封装元素操作"""
# 输入用户名
def name_imput(self):
self.send_keys(self.name_input_locator, self.username)
# 输入密码
def passwd_imput(self):
self.send_keys(self.passwd_input_locator, self.userpasswd)
# 点击登陆
def click_submit(self):
self.click(self.submit_button_locator)
if __name__ == '__main__':
base = Base('firefox')
base.open_url(url=LoginPage.url)(4)原登陆案例封装完成代码
测试方法及测试类的执行都在此文件中。
# 1. 导入包
import unittest
from pages.login_page import LoginPage
# 定义测试类
class TestCaseLogin(unittest.TestCase):
def setUp(self) -> None:
self.driver = LoginPage()
self.driver.open_url(LoginPage.url)
def tearDown(self) -> None:
# 5. 关闭浏览器
self.driver.close()
def testLogin(self):
"""登陆测试用例"""
self.driver.name_imput()
self.driver.passwd_imput()
self.driver.click_submit()
if __name__ == '__main__':
unittest.main()提示:最后我们在使用测试套件来执行测试用例的时候,就定位这些testcase文件就好。
5、总结
虽然该实现方法看上去复杂多了,但其中的设计好处是不同层关心不同的问题。
- 页面对象只关心元素的定位。
- 测试用例只关心测试数据。
使用POM进行重新构造代码结构后,发现代码测试用例代码的可读性提高很多。
定义好的PageObject组件可以重复在其它的脚本中进行使用,减少了代码的工作量,也方便对脚本进行后期的维护管理,当元素属性发生变化时,我们只需要对一个PageObaject页面中的对象组件定义进行更改即可。
最后我这里给你们分享一下我所积累和真理的文档和学习资料有需要是领取就可以了
1、学习思路和方法
这个大纲涵盖了目前市面上企业百分之99的技术,这个大纲很详细的写了你该学习什么内容,企业会用到什么内容。总共十个专题足够你学习

2、想学习却无从下手,该如何学习?
这里我准备了对应上面的每个知识点的学习资料、可以自学神器,已经项目练手。

3、软件测试/自动化测试【全家桶装】学习中的工具、安装包、插件....


4、有了安装包和学习资料,没有项目实战怎么办,我这里都已经准备好了往下看

最后送上一句话:
世界的模样取决于你凝视它的目光,自己的价值取决于你的追求和心态,一切美好的愿望,不在等待中拥有,而是在奋斗中争取。
如果我的博客对你有帮助、如果你喜欢我的文章内容,请 “点赞” “评论” “收藏” 一键三连哦




![[附源码]java毕业设计剧本杀门店管理系统-](https://img-blog.csdnimg.cn/34d494fdd8a4431dbb79ae904104e667.png)

![[附源码]Python计算机毕业设计《数据库系统原理》在线学习平台](https://img-blog.csdnimg.cn/2d31b8b732e54684a89fca7302c289a5.png)