目录
1.常见的排序算法
2.插入排序
直接插入排序
希尔排序
3.交换排序
冒泡排序
快速排序
hoare版本
挖坑法
前后指针法
非递归实现
4.选择排序
直接选择排序
堆排序
5.归并排序
6.排序总结
一起去,更远的远方

1.常见的排序算法

2.插入排序
直接插入排序


void InsertSort(int* a, int n)
{
for (int i = 1; i < n; i++)
{
int end = i - 1;
int tmp = a[i];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end+1] = a[end];
--end;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}
希尔排序

当gap==1时就是直接插入排序,可以赋值对比一下

//希尔排序
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end = end - gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
希尔排序的时间复杂度我们直接记住一个结论 o(n^1.3)
3.交换排序
冒泡排序
前一个和后一个数循坏比较大的数字放最后面,然后再循环比剩下的数字
void BubbleSort(int* a, int n)
{
for (int j = 0; j < n; j++)
{
for (int i = 1; i < n-j; i++)
{
if (a[i-1] > a[i ])
{
int tmp = a[i];
a[i] = a[i -1];
a[i - 1] = tmp;
}
}
}
}

快速排序
hoare版本
hoare排序思想: 我们默认序列左起第一个数为key,我们定义两个下标left和right分别从序列的左边和右边去找值,left找比key大的值,right找比key小的值,找到之后,交换left和right的值,等到left和right相遇的时候,此时的值一定是比key小的值,我们再把key和这个相遇位置的值进行交换,这样key就回到它应有的正确位置上,我们再递归处理key的左边区间和右边区间,递归结束之后,快排也就结束了。

//单趟排序,
int PartSort1(int* a, int left, int right)
{
int key = left;
while (left < right)
{
//左边做key,先走右边
while (left<right&& a[right] >= a[key])
{
right--;
}
//左边找大交换,找大的数,小的数就继续走,大的数是结束循环条件
while (left < right && a[left] <= a[key])
{
left++;
}
Swap(&a[left],&a[right]);
}
Swap(&a[key],&a[left]); //最后把key交换一下
return left;//相遇的位置,就是key中间的位置
}
void QuickSort(int* a, int begin, int end)
{
if (begin >= end) //当左边区间为空或者左边为1个就结束了
return;
int key = PartSort1(a, begin, end);
//begin key-1 key key+1 end
QuickSort(a, begin, key - 1);
QuickSort(a, key + 1, end);
} 
注意两个问题
a. 如果key后面的每个数都比key小或大的话,那left向后面找或right向前面找,就会产生越界访问的问题,为了防止这样情况的产生,我们选择在if语句的判断部分加个逻辑与&&保证left小于right,以免产生越界访问的问题。
b. 我们在if语句的判断部分,找的数一定得比key小或大,连相等都是不可以的,为什么呢?因为会产生死循环。
一旦序列中的左右出现相等的数字的时候,我们if语句如果写成>或<而不是>=或<=,程序就废了。

我们用的是分而治之的思想,第一趟排序找到了中间的key,然后再让begin,key-1和key+1,end再继续递归(begin,key-1,,,key,,,,,,key+1,end)

挖坑法
挖坑法思想: 挖坑法的思想还是要比hoare大佬的思想更加容易理解的,整体是一个什么思想呢?
我们先在序列的最左边挖一个坑,然后这个坑位的值就是key值,然后从右往左找比key小的值填到坑位上面去,这个时候坑位就变成right位置了,我们再从左向右找比key大的值,把这个值填到坑位上面去,再将坑位更新为left,循环进行这个工作,直到left和right相遇,他们相遇的位置也就是最后一次hole的位置,我们将key填到hole的位置,这样key就回到它本身的位置了。
剩下的工作我们还是交给递归,递归处理左区间和右区间。
//挖坑法
int PartSort1(int* a, int left, int right)
{
int key = a[left];
int hole = left;
while (left < right)
{
//先走右边
while (left < right && a[right] >= key)
{
right--;
}
a[hole] = a[right];
hole = right;
//左边找大交换,找大的数,小的数就继续走,大的数是结束循环条件
while (left < right && a[left] <= key)
{
left++;
}
a[hole] = a[left];
hole = left;
}
a[hole] = key;
return left;//相遇的位置,就是key中间的位置
}
void QuickSort(int* a, int begin, int end)
{
if (begin >= end) //当左边区间为空或者左边为1个就结束了
return;
int key = PartSort1(a, begin, end);
//begin key-1 key key+1 end
QuickSort(a, begin, key - 1);
QuickSort(a, key + 1, end);
}
前后指针法
前后指针办法,这个简单方便
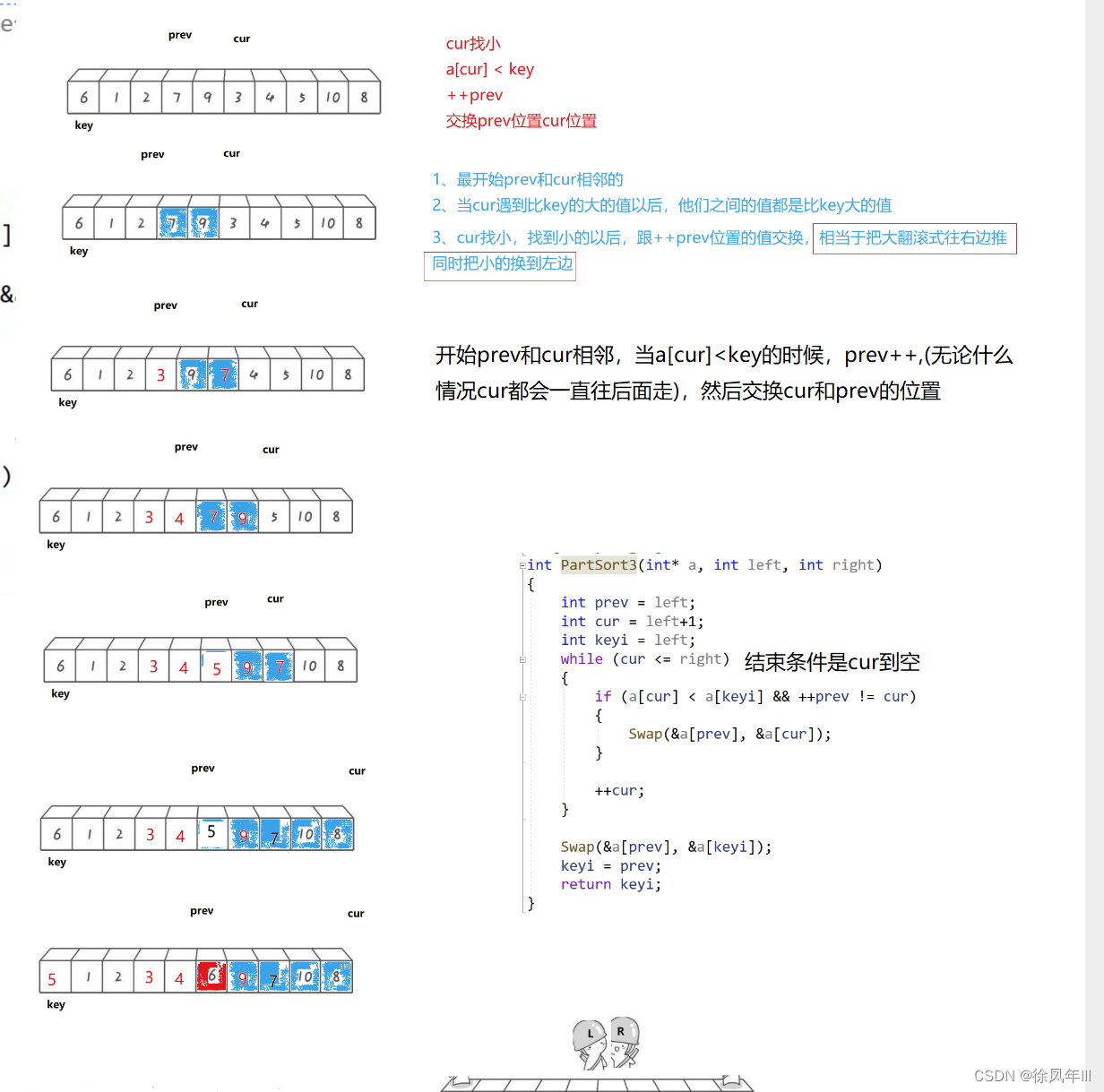
int PartSort3(int* a, int left, int right)
{
int prev = left;
int cur = left + 1;
int keyi = left;
while (cur<=right)
{
if (a[cur] < a[keyi])
{
prev++;
Swap(&a[cur],& a[prev]);
}
cur++;
}
Swap(&a[keyi], &a[prev]);
keyi = prev;
return keyi;
}
void QuickSort(int* a, int begin, int end)
{
if (begin >= end) //当左边区间为空或者左边为1个就结束了
return;
int key = PartSort3(a, begin, end);
//begin key-1 key key+1 end
QuickSort(a, begin, key - 1);
QuickSort(a, key + 1, end);
}
非递归实现
void QuickSortNonR(int* a, int begin, int end)
{
ST st;
STInit(&st);
STPush(&st, end);
STPush(&st, begin);
while (!STEmpty(&st))
{
int left = STTop(&st);
STPop(&st);
int right = STTop(&st);
STPop(&st);
//int keyi = PartSort3(a, left, right);
int keyi = PartSort1(a, left, right);
// [left, keyi-1] keyi [keyi+1, right]
if (keyi + 1 < right)
{
STPush(&st, right);
STPush(&st, keyi + 1);
}
if (left < keyi-1)
{
STPush(&st, keyi-1);
STPush(&st, left);
}
}
STDestroy(&st);
}4.选择排序
直接选择排序
相当于玩扑克牌的时候,一把把全部的牌抓起来,按大小顺序排序
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void SelectSort(int* a, int n)
{
int begin = 0, end = n - 1;
while (begin < end)
{
int maxi = begin, mini = begin;
for (int i = begin; i <= end; i++)
{
if (a[i] > a[maxi])
{
maxi = i;
}
if (a[i] < a[mini])
{
mini = i;
}
}
Swap(&a[begin], &a[mini]);
if (begin == maxi)
{
maxi = mini;
}
Swap(&a[end], &a[maxi]);
++begin;
--end;
}
}
堆排序
向下调整算法

建堆+向下调整算法
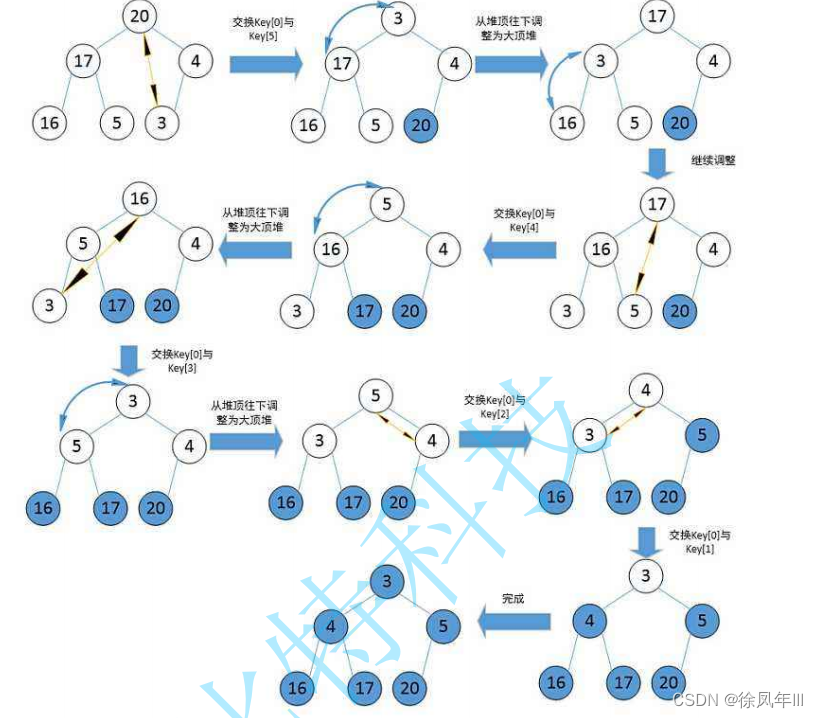
//向下调整
void AdjustDwon(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
//if (child + 1 < n && a[child + 1] < a[child]) //小堆
if (child + 1 < n && a[child + 1] > a[child]) //升序改成大堆
{
++child;
//默认左孩子最小,这样可以找出最小的那个孩子
}
//if (a[child] < a[parent]) //小堆是小于
if (a[child] > a[parent]) //大堆改成大于, 升序改成大堆
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//堆排
//升序建大堆,降序建小堆
void HeapSort(int* a, int n)
{
//建堆,向下调整建堆
for (int i = (n - 1 - 1) / 2; i >=0; i--)
{
AdjustDwon(a,n,i);
}
int end = n - 1;
while (end > 0)
{
Swap(&a[end], &a[0]);
AdjustDwon(a, end, 0);
end--;
}
}详情可以看二叉树和堆的章节

5.归并排序

void _MergeSort(int* arr, int begin, int end, int* tmp)
{
if (begin >= end)
{
return;
}
int mid = (begin + end) / 2;
_MergeSort(arr, begin, mid , tmp);
_MergeSort(arr, mid + 1, end, tmp);
int i = begin;
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] <= arr[begin2])//等于时我们取前一个,保证算法的稳定性
{
tmp[i++] = arr[begin1++];
}
else
{
tmp[i++] = arr[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = arr[begin2++];
}
memcpy(arr+begin, tmp+begin, sizeof(int) * (end - begin + 1));
}
void MergeSort(int* arr, int begin, int end)
{
int* tmp = (int*)malloc(sizeof(int) * (end - begin));
_MergeSort(arr, begin, end-1, tmp);
free(tmp);
tmp = NULL;
}
6.排序总结