Class文件结构
字节码文件的跨平台性(了解)
1.Java语言:跨平台的语言
- 当Java源代码成功编译为字节码后,如果想在不同的平台上运行,则无须再次编译
- 这个优势不再那么吸引人了。Python PHP perl ruby lisp等有强大的解释器
- 跨平台似乎已经快成为一门语言必须的特征
2.Java虚拟机:跨语言的平台:
( Java虚拟机不和包括java在内的任何语言绑定,它只与class文件这种二进制文件格式所关联。无论使用何种语言进行软件开发,只要将源文件编译为正确的Class文件,那么这种语言就可以在Java虚拟机上执行,可以说,统一而强大的Class文件结构,就是Java虚拟机的基石、桥梁)。
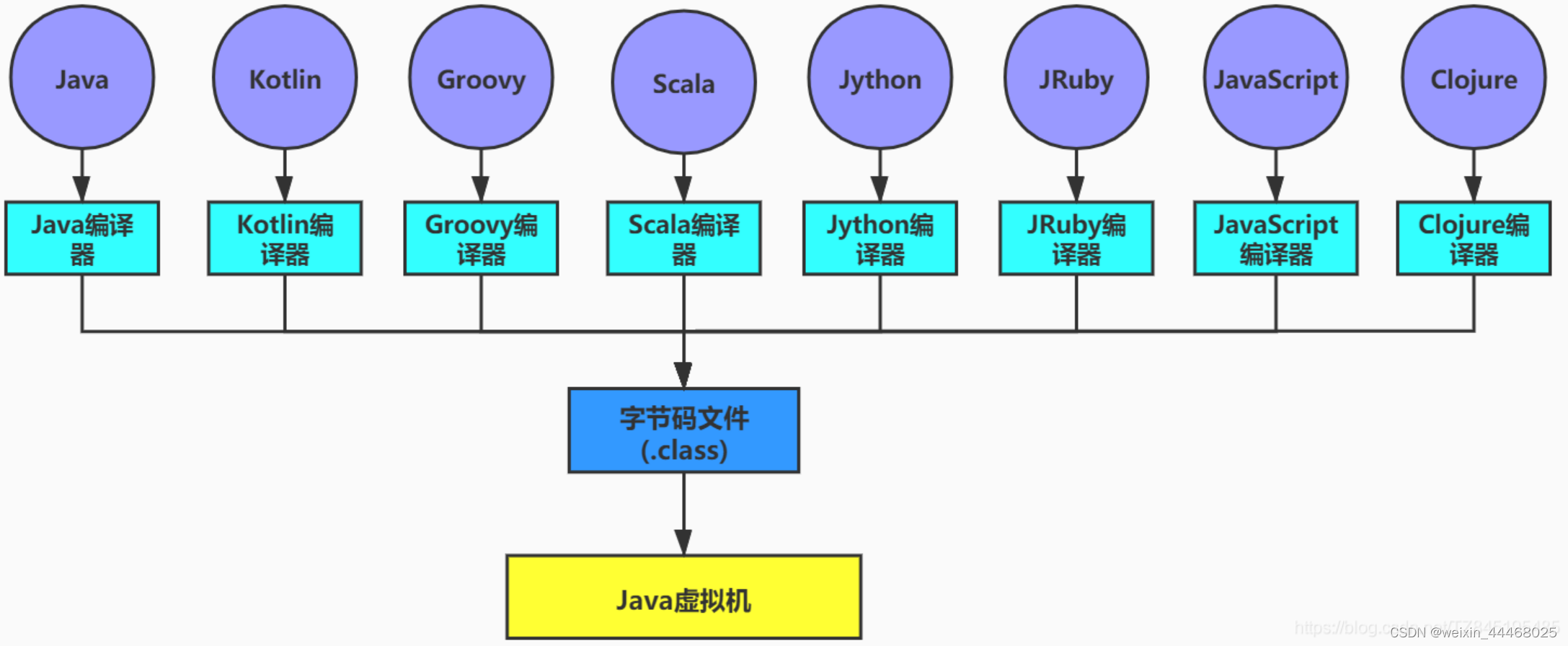
想要让一个Java程序正确地运行在JVM中,Java源码就必须要编译为符合JVM规范的字节码
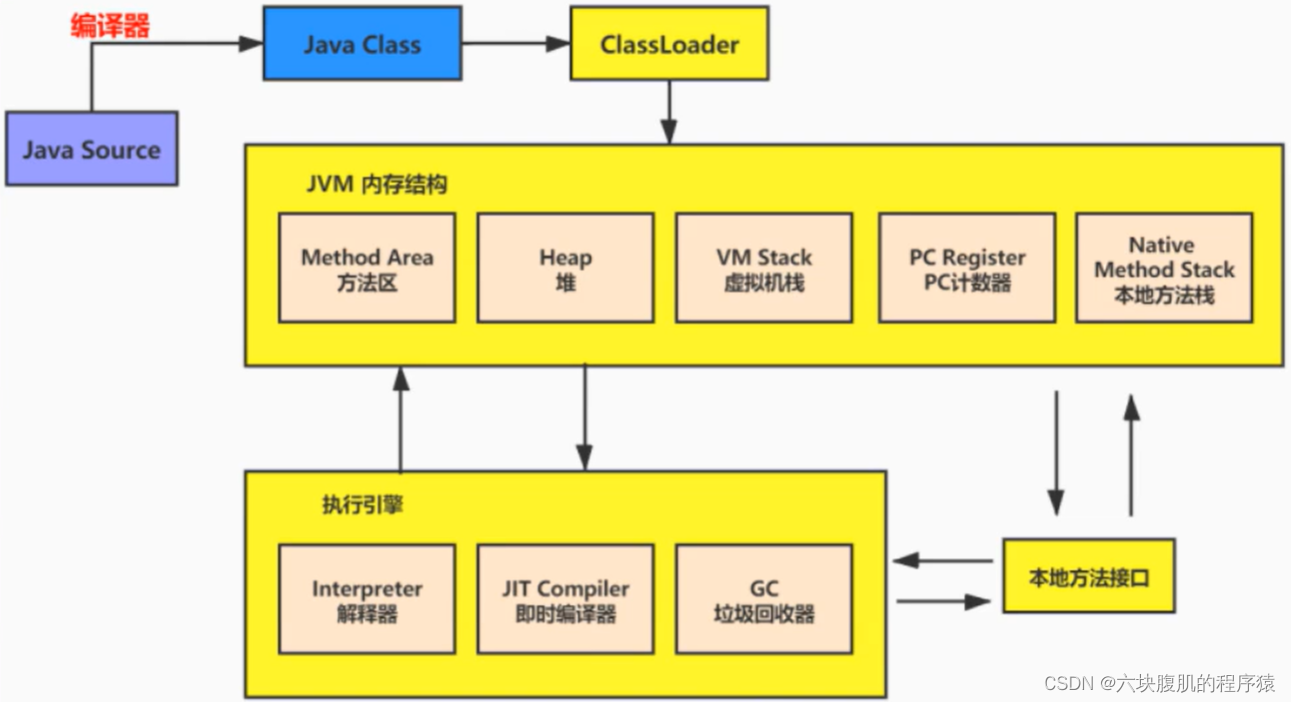
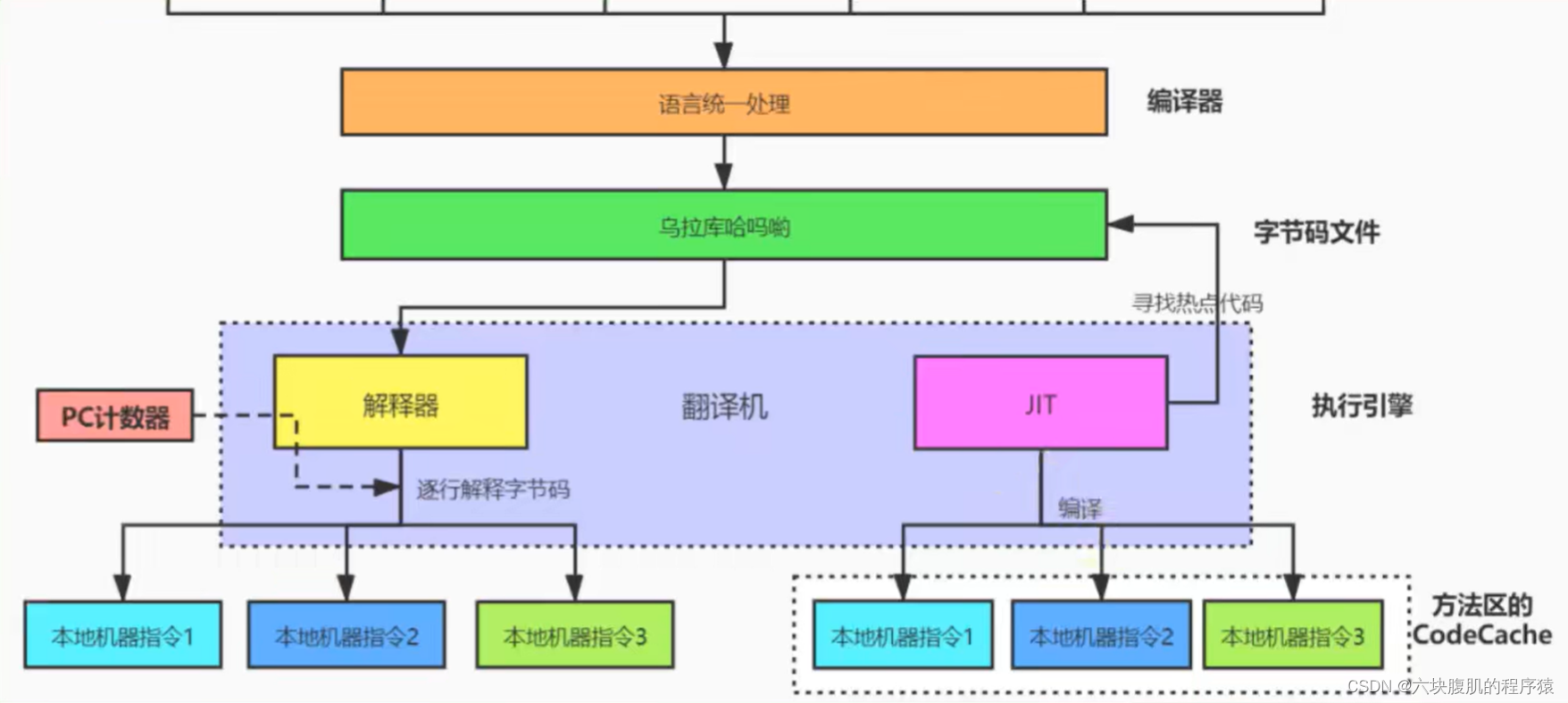
- 前端编译器的主要任务 就是负责将符合Java语言规范的Java代码转换为符合JVM规范的字节码文件
- javac是一种能够将Java源码编译为字节码的前端编译器
- javac编译器在将Java源码编译为一个有效的字节码文件过程中经历了4个步骤:分别是词法解析、语法解析、语义解析以及生成字节码。
Java的前端编译器(了解)
前端编译器 vs 后端编译器

(为什么要学习字节码文件)透过字节码指令看代码细节
1.BAT面试题
①类文件结构有几个部分?
②知道字节码吗?字节码都有哪些?Integer x = 5;int = 5;比较x==y都经过哪些步骤?
2.代码举例
①. Integer:透过字节码可以看出,当Integer的范围在-128 - +127 之间会在数组中直接拿取数值,超过这个范围会重新new对象
public class IntegerTest {
public static void main(String[] args) {
/*
* 透过字节码可以看出,当Integer的范围在-128 - +127 之间会在数组中直接拿取数值
* 超过这个范围会重新new对象
* */
Integer x = 5;
int y = 5;
System.out.println(x == y);
Integer i1 = 10;
Integer i2 = 10;
System.out.println(i1 == i2);//true
Integer i3 = 128;
Integer i4 = 128;
System.out.println(i3 == i4);//false
}
②. 在父类中调用方法,如果子类有重写,那么调用的是子类的方法,如代码中的this.print( )
注意:这里的this是指的 new son( )
/*
成员变量(非静态的)的赋值过程:
① 默认初始化 -
② 显式初始化 /代码块中初始化 -
③ 构造器中初始化 -
④ 有了对象之后,可以“对象.属性”或"对象.方法"
的方式对成员变量进行赋值。
*/
class Father {
int x = 10;
public Father() {
this.print();
x = 20;
}
public void print() {
System.out.println("Father.x = " + x);
}
}
class Son extends Father {
int x = 30;
// float x = 30.1F;
public Son() {
this.print();
x = 40;
}
public void print() {
System.out.println("Son.x = " + x);
}
}
public class SonTest {
public static void main(String[] args) {
Father f = new Son();
System.out.println(f.x);//编译看左边,执行也看左边
}
}
/*
son.x=0
son.x=30
20
*/
如何解读供虚拟机解释执行的二进制字节码?
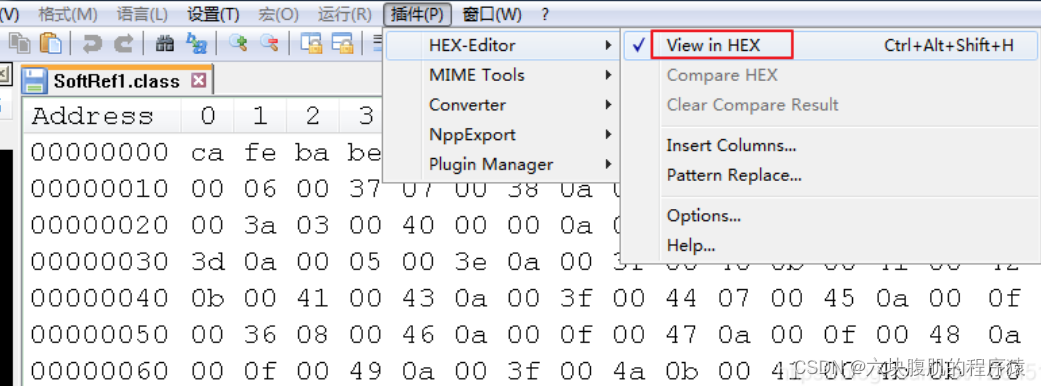
- 一个一个二进制的看。这里用到的是Notepad++,需要安装一个HEX-Editor插件,或者使用Binary View
2.使用javap指令:jdk自带的反解析工具
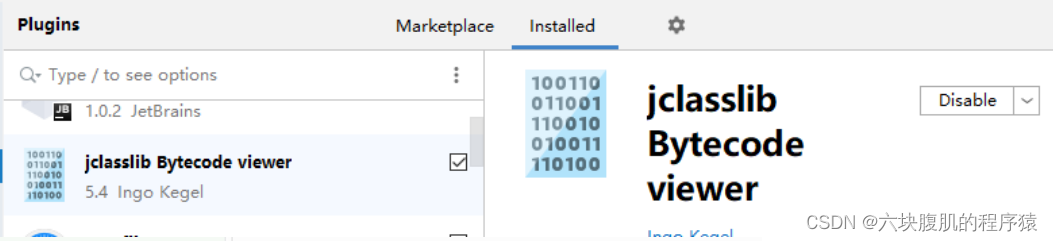
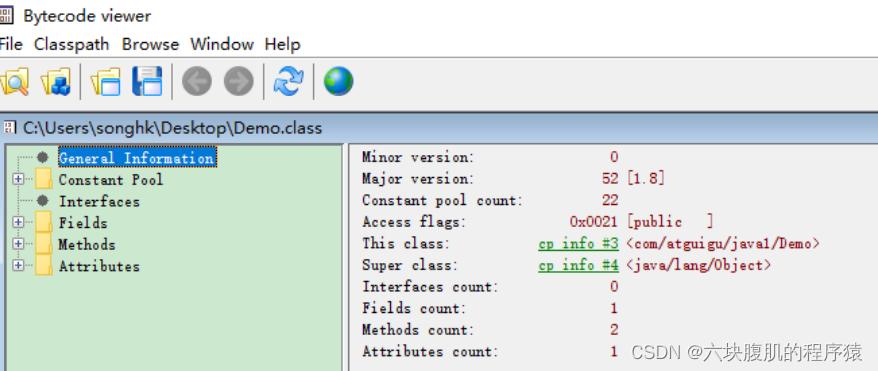
3.使用IDEA插件:jclasslib 或jclasslib bytecode viewer客户端工具(可视化更好)
什么是字节码指令
Java虚拟机的指令由一个字节长度的、代表着某种特定操作含义的操作码(opcode)以及跟随其后的零至多个代表此操作所需参数的操作数(operand)所构成。虚拟机中许多指令并不包含操作数,只有一个操作码
比如:操作码(操作数)

class文件结构
class文件结构细节概述
① Class文件的结构并不是一成不变的,随着Java虚拟机的不断发展,总是不可避免地会对Class文件结构做出一些调整,但是其基本结构和框架是非常稳定的
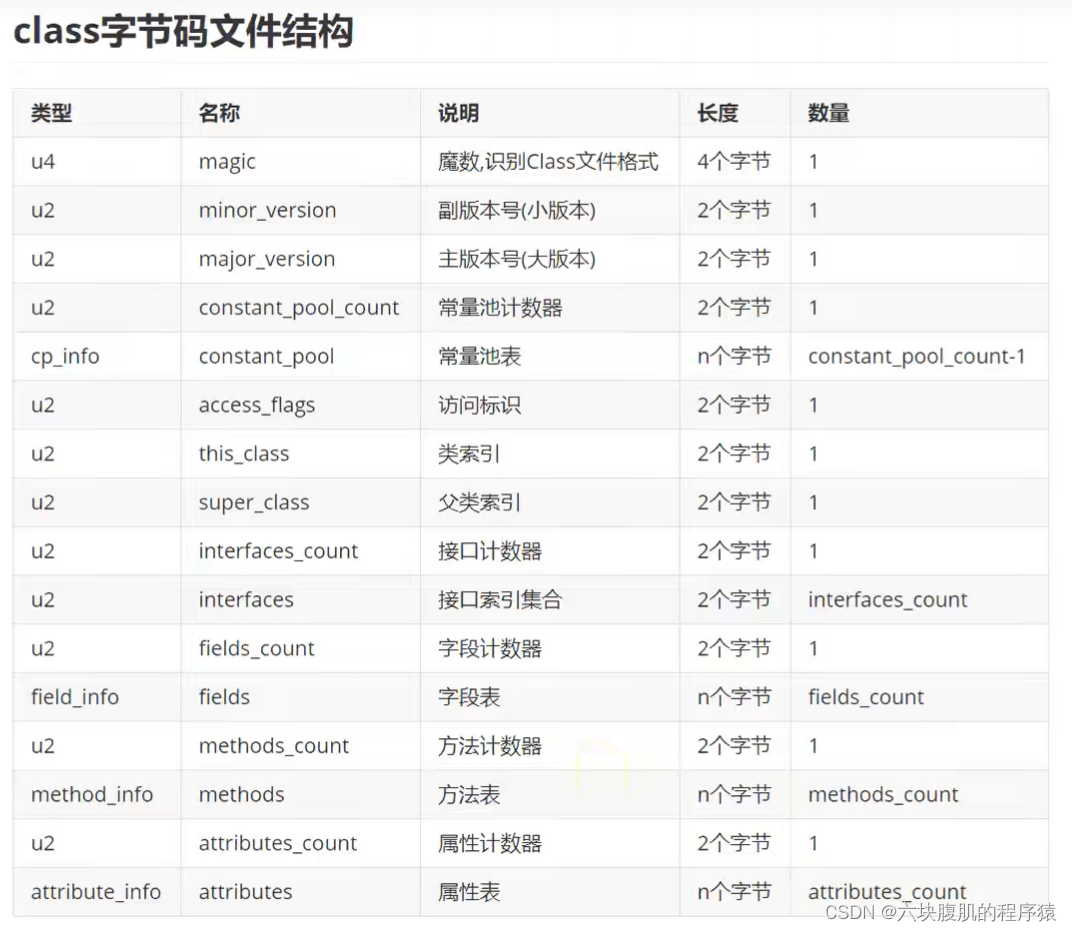
② Class 文件格式采用一种类似于 C语言结构体的方式进行数据存储,这种结构中只有两种数据类型:无符号数和表
无符号数属于基本的数据类型,以 u1、u2、u4、u8 来分别代表 1 个字节、2 个字节、4 个字节和 8 个字节的无符号数,无符号数可以用来描述数字、索引引用、数量值或者按照 UTF-8 编码构成字符串值
表是由多个无符号数或者其他表作为数据项构成的复合数据类型,所有表都习惯性地以“_info”结尾。表用于描述有层次关系的复合结构的数据,整个 Class 文件本质上就是一张表。 由于表没有固定长度,所以通常会在其前面加上个数说明
public class Demo {
private int num = 1;
public int add(){
num = num + 2;
return num;
}
}
③ Class文件的总体结构如下
(魔数、Class文件版本、常量池、访问标识(或标志)、索引,父类索引,接口索引集合、字段表集合、方法表集合、属性表集合)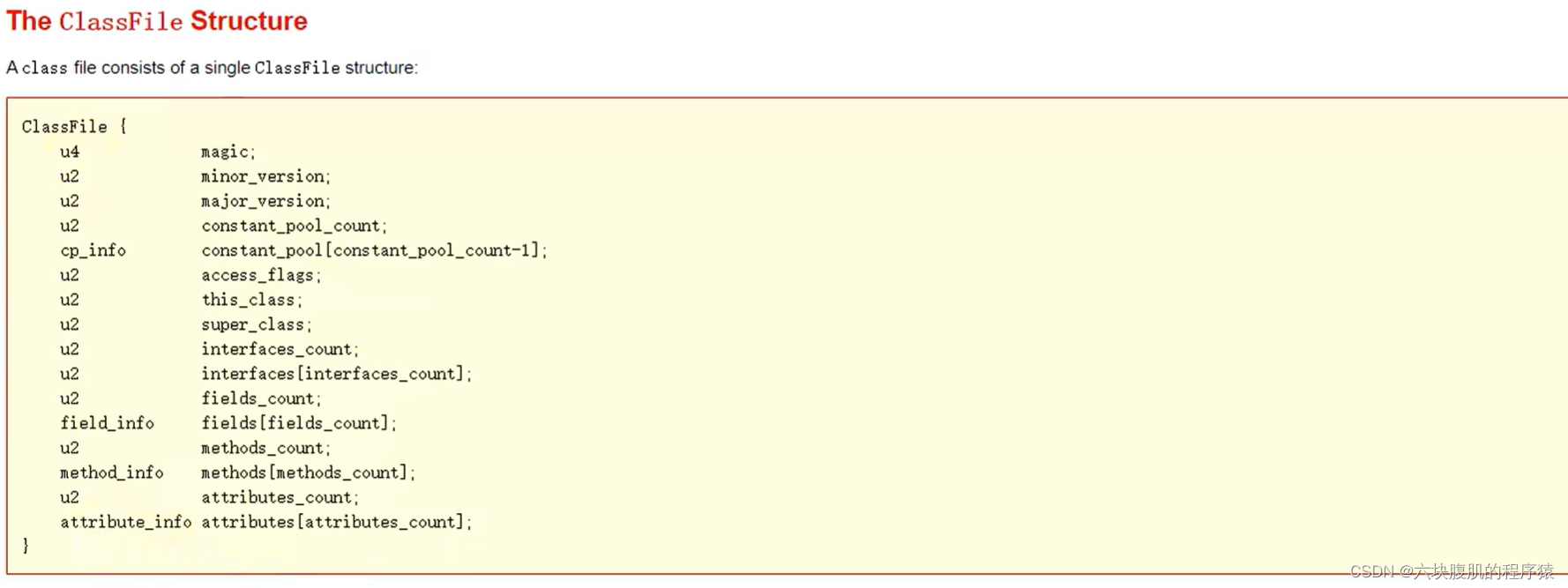
class文件的魔数是什么
- 每个Class文件开头的4个字节的无符号整数称为魔数(Magic Number)
- 它的唯一作用是确定这个文件是否为一个能被虚拟机接受的有效合法的Class文件。即:魔数是Class文件的标识符
- 魔数值固定为0xCAFEBABE。不会改变
- 如果一个Class文件不以0xCAFEBABE开头,虚拟机在进行文件校验的时候就会直接抛出以下错误:

- 使用魔数而不是扩展名来进行识别主要是基于安全方面的考虑,因为文件扩展名可以随意地改动
如何确保高版本的JVM可执行低版本的class文件?
class文件版本号:
-
紧接着魔数的 4 个字节存储的是 Class 文件的版本号。同样也是4个字节。第5个和第6个字节所代表的含义就是编译的副版本号minor_version,而第7个和第8个字节就是编译的主版本major_version
-
它们共同构成了class文件的格式版本号。譬如某个 Class 文件的主版本号为 M,副版本号为 m,那么这个Class 文件的格式版本号就确定为 M.m
-
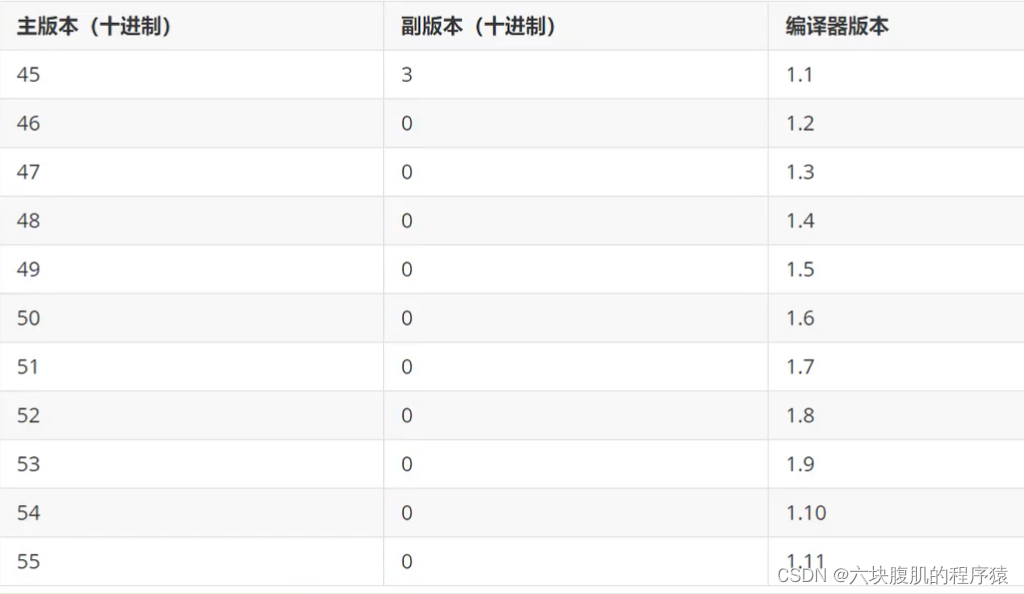
版本号和Java编译器的对应关系如下表:
-
Java 的版本号是从45开始的,JDK 1.1之后的每个JDK大版本发布主版本号向上加1。
-
不同版本的Java编译器编译的Class文件对应的版本是不一样的。目前,高版本的Java虚拟机可以执行由低版本编译器生成的Class文件,但是低版本的Java虚拟机不能执行由高版本编译器生成的Class文件。否则JVM会抛出java.lang.UnsupportedClassVersionError异常(向下兼容)
常量池(class文件的基石)
什么是常量池?
-
常量池是Class文件中内容最为丰富的区域之一。常量池对于Class文件中的字段和方法解析也有着至关重要的作用。
-
随着Java虚拟机的不断发展,常量池的内容也日渐丰富。可以说,常量池是整个Class文件的基石。
-
在版本号之后,紧跟着的是常量池的数量,以及若干个常量池表项。
-
常量池中常量的数量是不固定的,所以在常量池的入口需要放置一项u2类型的无符号数,代表常量池容量计数值(constant_pool_count)。与Java中语言习惯不一样的是,这个容量计数是从1而不是0开始的。

由上表可见,Class文件使用了一个前置的容量计数器(constant_pool_count)加若干个连续的数据项(constant_pool)的形式来描述常量池内容。我们把这一系列连续常量池数据称为常量池集合。 -
常量池表项中,用于存放编译时期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放
常量池计数器
onstant_pool_count(常量池计数器)
- 由于常量池的数量不固定,时长时短,所以需要放置两个字节来表示常量池容量计数值。
- 常量池容量计数值(u2类型):从1开始,表示常量池中有多少项常量。即constant_pool_count=1表示常量池中有0个常量项。
- Demo的值为:

其值为0x0016,掐指一算,也就是22。
需要注意的是,这实际上只有21项常量。索引为范围是1-21。为什么呢?
通常我们写代码时都是从0开始的,但是这里的常量池却是从1开始,因为它把第0项常量空出来了。这是为了满足后面某些指向常量池的索引值的数据在特定情况下需要表达“不引用任何一个常量池项目”的含义,这种情况可用索引值0来表示。
常量池表
-
constant_pool是一种表结构,以1 ~ constant_pool_count - 1为索引。表明了后面有多少个常量项。
-
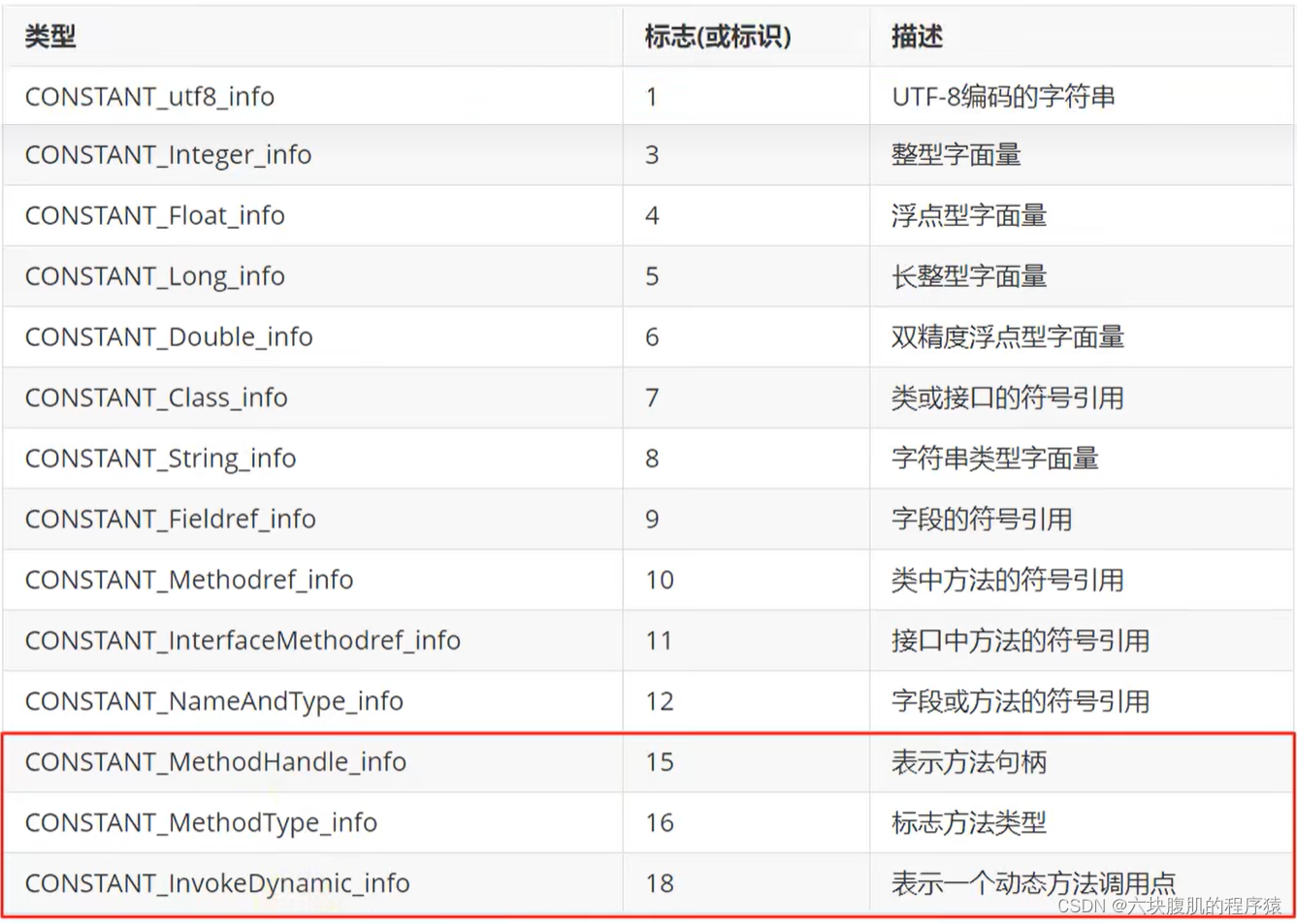
常量池主要存放两大类常量:字面量(Literal)和符号引用(Symbolic References)
-
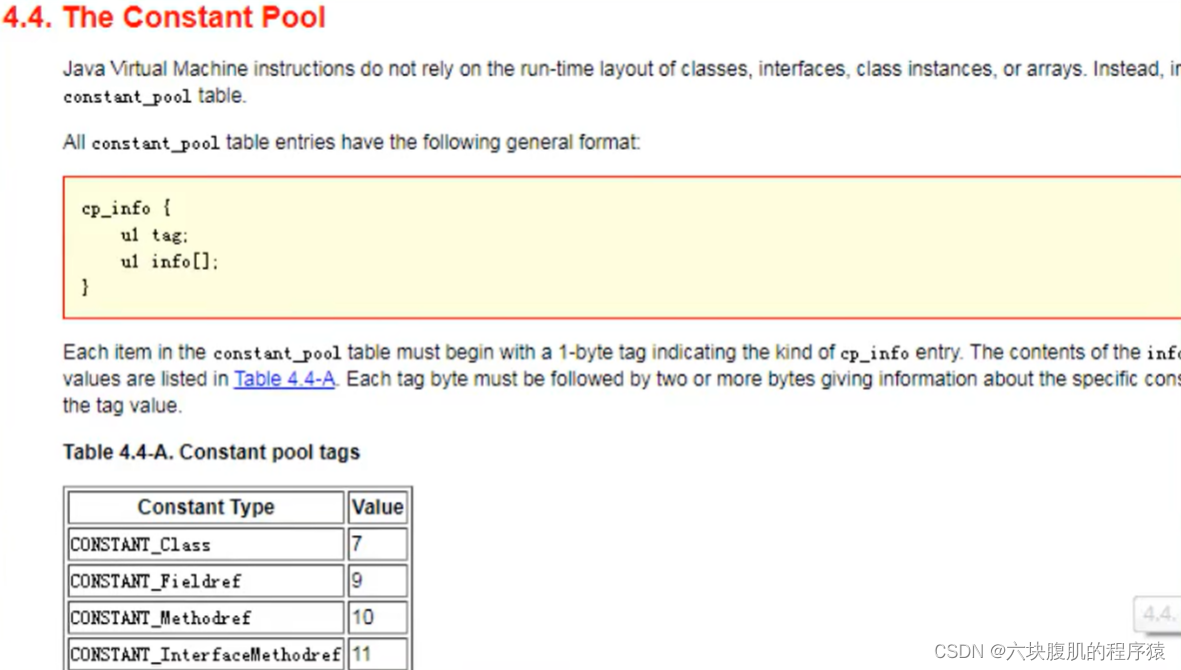
它包含了class文件结构及其子结构中引用的所有字符串常量、类或接口名、字段名和其他常量。常量池中的每一项都具备相同的特征。第1个字节作为类型标记,用于确定该项的格式,这个字节称为tag byte(标记字节、标签字节)。
字面量和符号引用
在对这些常量解读前,我们需要搞清楚几个概念。
常量池主要存放两大类常量:字面量(Literal)和符号引用(Symbolic References)。如下表:
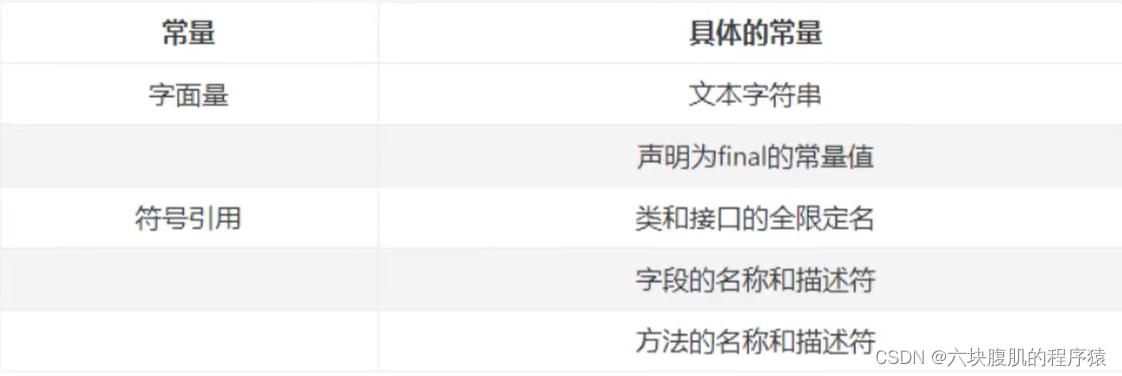
全限定名
com/atguigu/test/Demo这个就是类的全限定名,仅仅是把包名的“.“替换成”/”,为了使连续的多个全限定名之间不产生混淆,在使用时最后一般会加入一个“;”表示全限定名结束。
简单名称
简单名称是指没有类型和参数修饰的方法或者字段名称,上面例子中的类的add()方法和num字段的简单名称分别是add和num。
描述符
描述符的作用是用来描述字段的数据类型、方法的参数列表(包括数量、类型以及顺序)和返回值。根据描述符规则,基本数据类型(byte、char、double、float、int、long、short、boolean)以及代表无返回值的void类型都用一个大写字符来表示,而对象类型则用字符L加对象的全限定名来表示,详见下表:
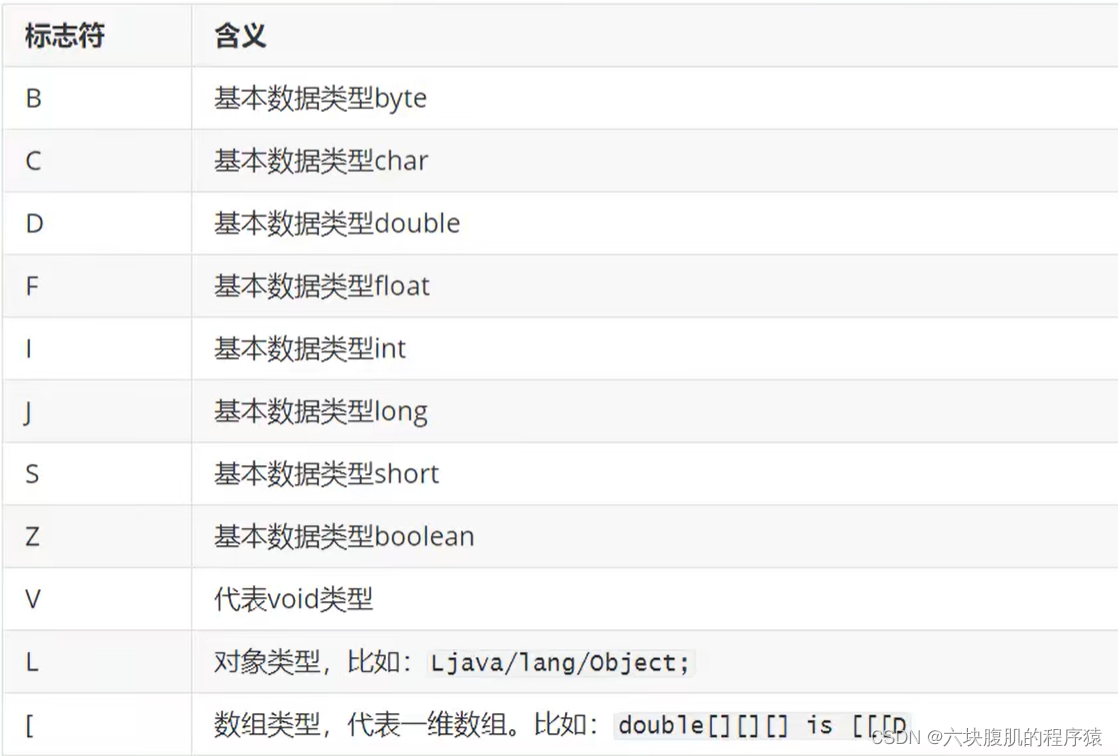
用描述符来描述方法时,按照先参数列表,后返回值的顺序描述,参数列表按照参数的严格顺序放在一组小括号“()”之内。如方法java.lang.String tostring()的描述符为()Ljava/lang/String; ,方法int abc(int[]x, int y)的描述符为([II)I。
补充说明:
虚拟机在加载Class文件时才会进行动态链接,也就是说,Class文件中不会保存各个方法和字段的最终内存布局信息。因此,这些字段和方法的符号引用不经过转换是无法直接被虚拟机使用的。当虚拟机运行时,需要从常量池中获得对应的符号引用,再在类加载过程中的解析阶段将其替换为直接引用,并翻译到具体的内存地址中。
这里说明下符号引用和直接引用的区别与关联:
符号引用:符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可。符号引用与虚拟机实现的内存布局无关,引用的目标并不一定已经加载到了内存中。
直接引用:直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。直接引用是与虚拟机实现的内存布局相关的,同一个符号引用在不同虚拟机实例上翻译出来的直接引用一般不会相同。如果有了直接引用,那说明引用的目标必定已经存在于内存之中了。
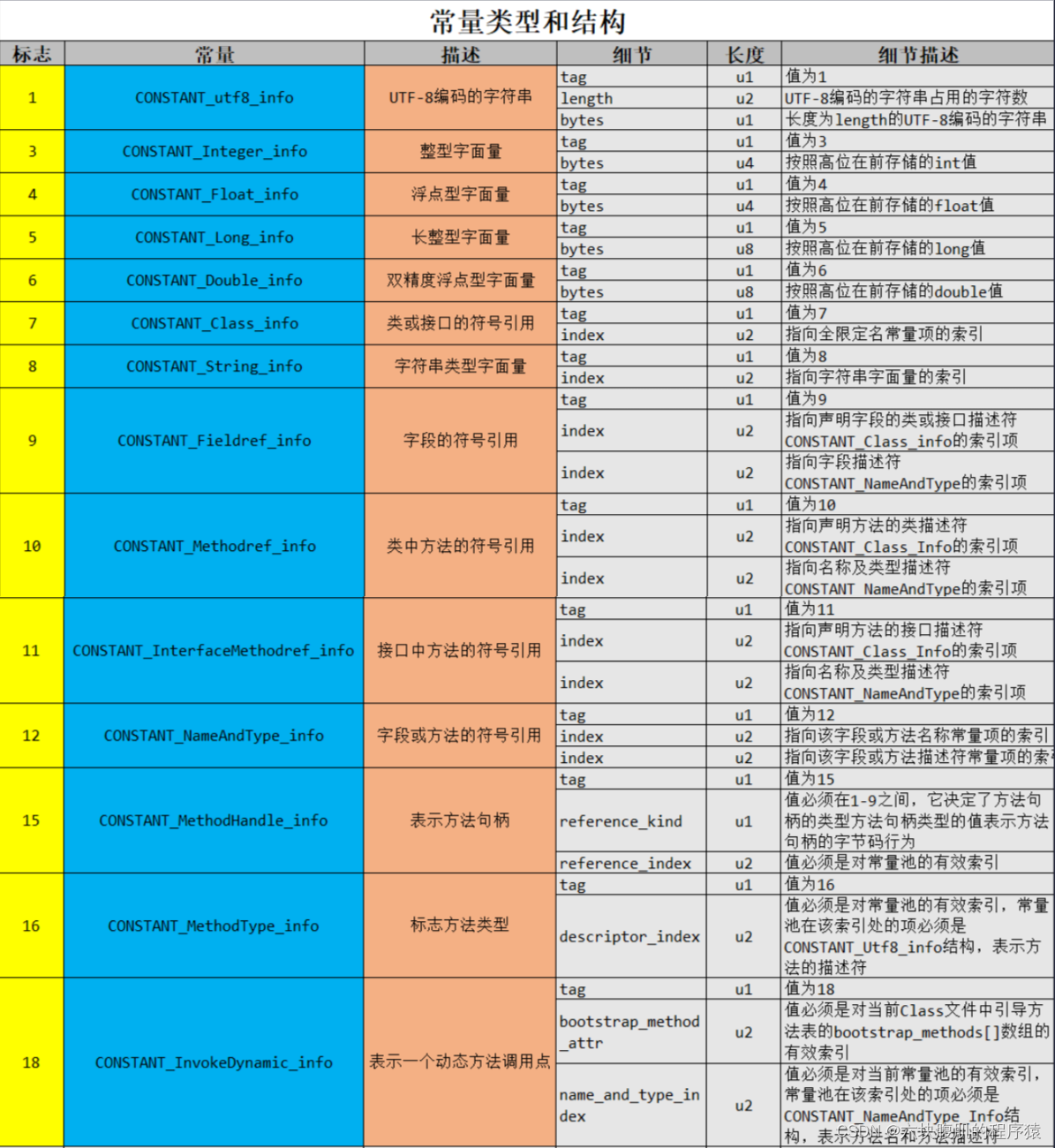
常量类型和结构
常量池中每一项常量都是一个表,J0K1.7之后共有14种不同的表结构数据。如下表格所示:
-
根据上图每个类型的描述我们也可以知道每个类型是用来描述常量池中哪些内容(主要是字面量、符号引用)的。比如:
CONSTANT_Integer_info是用来描述常量池中字面量信息的,而且只是整型字面量信息。 -
标志为15、16、18的常量项类型是用来支持动态语言调用的(jdk1.7时才加入的)。
-
细节说明:
- CONSTANT_Class_info结构用于表示类或接口
- CONSTAT_Fieldref_info、CONSTAHT_Methodref_infoF和lCONSTANIT_InterfaceMethodref_info结构表示字段、方汇和按口小法
- CONSTANT_String_info结构用于表示示String类型的常量对象
- CONSTANT_Integer_info和CONSTANT_Float_info表示4字节(int和float)的数值常量
- CONSTANT_Long_info和CONSTAT_Double_info结构表示8字作(long和double)的数值常量
- 在class文件的常最池表中,所行的a字节常借均占两个表成员(项)的空问。如果一个CONSTAHT_Long_info和 - - - CNSTAHT_Double_info结构在常量池中的索引位n,则常量池中一个可用的索引位n+2,此时常量池长中索引为n+1的项仍然有效但必须视为不可用的。
-
CONSTANT_NameAndType_info结构用于表示字段或方法,但是和之前的3个结构不同,CONSTANT_NameAndType_info结构没有指明该字段或方法所属的类或接口。
-
CONSTANT_Utf8_info用于表示字符常量的值
-
CONSTANT_MethodHandle_info结构用于表示方法句柄
-
CONSTANT_MethodType_info结构表示方法类型
-
CONSTANT_InvokeDynamic_info结构表示invokedynamic指令所用到的引导方法(bootstrap method)、引导方法所用到的动态调用名称(dynamic invocation name)、参数和返回类型,并可以给引导方法传入一系列称为静态参数(static argument)的常量。
-
解析方法:
一个字节一个字节的解析

使用javap命令解析:javap-verbose Demo.class或jclasslib工具会更方便。
总结1:
- 这14种表(或者常量项结构)的共同点是:表开始的第一位是一个u1类型的标志位(tag),代表当前这个常量项使用的是哪种表结构,即哪种常量类型。
- 在常量池列表中,CONSTANT_Utf8_info常量项是一种使用改进过的UTF-8编码格式来存储诸如文字字符串、类或者接口的全限定名、字段或者方法的简单名称以及描述符等常量字符串信息。
- 这14种常量项结构还有一个特点是,其中13个常量项占用的字节固定,只有CONSTANT_Utf8_info占用字节不固定,其大小由length决定。为什么呢?因为从常量池存放的内容可知,其存放的是字面量和符号引用,最终这些内容都会是一个字符串,这些字符串的大小是在编写程序时才确定,比如你定义一个类,类名可以取长取短,所以在没编译前,大小不固定,编译后,通过utf-8编码,就可以知道其长度。
总结2:
- 常量池:可以理解为Class文件之中的资源仓库,它是Class文件结构中与其他项目关联最多的数据类型(后面的很多数据类型都会指向此处),也是占用Class文件空间最大的数据项目之一。
- 常量池中为什么要包含这些内容?
Java代码在进行Javac编译的时候,并不像C和C++那样有“连接”这一步骤,而是在虚拟机加载C1ass文件的时候进行动态链接。也就是说,在Class文件中不会保存各个方法、字段的最终内存布局信息,因此这些字段、方法的符号引用不经过运行期转换的话无法得到真正的内存入口地址,也就无法直接被虚拟机使用。当虚拟机运行时,需要从常量池获得对应的符号引用,再在类创建时或运行时解析、翻译到具体的内存地址之中。关于类的创建和动态链接的内容,在虚拟机类加载过程时再进行详细讲解
访问标志
访问标识(access_flag、访问标志、访问标记)
-
在常量池后,紧跟着访问标记。该标记使用两个字节表示,用于识别一些类或者接口层次的访问信息,包括:这个Class是类还是接口;是否定义为public类型;是否定义为abstract类型;如果是类的话,是否被声明为final等。各种访问标记如下所示:

-
类的访问权限通常为ACC_开头的常量。
-
每一种类型的表示都是通过设置访问标记的32位中的特定位来实现的。比如,若是public final的类,则该标记为ACC_PUBLIC | ACC_FINAL。
-
使用ACC_SUPER可以让类更准确地定位到父类的方法super.method(),现代编译器都会设置并且使用这个标记。
补充说明:
1.带有ACC_INTERFACE标志的class文件表示的是接口而不是类,反之则表示的是类而不是接口。
1)如果一个class文件被设置了ACC_INTERFACE标志,那么同时也得设置ACC_ABSTRACT标志。同时它不能再设置ACC_FINAL、ACC_SUPER 或ACC_ENUM标志。
2)如果没有设置ACC_INTERFACE标志,那么这个class文件可以具有上表中除ACC_ANNOTATION外的其他所有标志。当然,ACC_FINAL和ACC_ABSTRACT这类互斥的标志除外。这两个标志不得同时设置。
2.ACC_SUPER标志用于确定类或接口里面的invokespecial指令使用的是哪一种执行语义。针对Java虚拟机指令集的编译器都应当设置这个标志。对于Java SE 8及后续版本来说,无论class文件中这个标志的实际值是什么,也不管class文件的版本号是多少,Java虚拟机都认为每个class文件均设置了ACC_SUPER标志。
1)CC_SUPER标志是为了向后兼容由旧Java编译器所编译的代码而设计的。目前的ACC_SUPER标志在由JDK1.0.2之前的编译器所生成的access_flags中是没有确定含义的,如果设置了该标志,那么0racle的Java虚拟机实现会将其忽略。
3.ACC_SYNTHETIC标志意味着该类或接口是由编译器生成的,而不是由源代码生成的。
4.注解类型必须设置ACC_ANNOTATION标志。如果设置了ACC_ANNOTATION标志,那么也必须设置ACC_INTERFACE标志。
5.ACC_ENUM标志表明该类或其父类为枚举类型。
类索引、父类索引、接口索引
在访问标记后,会指定该类的类别、父类类别以及实现的接口,格式如下:
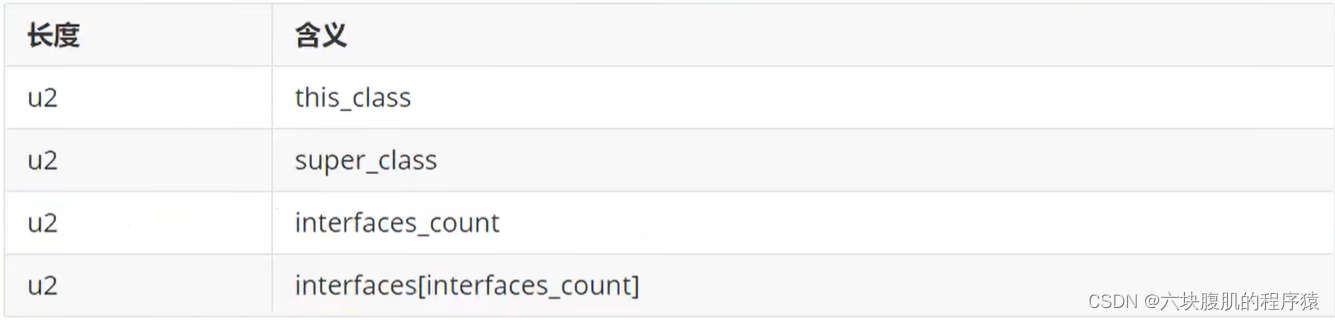
-
这三项数据来确定这个类的继承关系:
- 类索引用于确定这个类的全限定名
- 父类索引用于确定这个类的父类的全限定名。由于Java语言不允许多重继承,所以父类索引只有一个,除了java.1ang.Object之外,所有的Java类都有父类,因此除了java.lang.Object外,所有Java类的父类索引都不为e。
- 接口索引集合就用来描述这个类实现了哪些接口,这些被实现的接口将按implements语句(如果这个类本身是一个接口,则应当是extends语句)后的接口顺序从左到右排列在接口索引集合中。
this_class(类索引)
- 2字节无符号整数,指向常量池的索引。它提供了类的全限定名,如com/atguigu/java1/Demo。this_class的值必须是对常量池表中某项的一个有效索引值。常量池在这个索引处的成员必须为CONSTANT_Class_info类型结构体,该结构体表示这个class文件所定义的类或接口。
super_class(父类索引)
- 2字节无符号整数,指向常量池的索引。它提供了当前类的父类的全限定名。如果我们没有继承任何类,其默认继承的是java/lang/object类。同时,由于Java不支持多继承,所以其父类只有一个。
- super_class指向的父类不能是final。
interfaces
-
指向常量池索引集合,它提供了一个符号引用到所有已实现的接口
-
由于一个类可以实现多个接口,因此需要以数组形式保存多个接口的索引,表示接口的每个索引也是一个指向常量池的CONSTANT_Class(当然这里就必须是接口,而不是类)。
Ⅰ. interfaces_count(接口计数器)
interfaces_count项的值表示当前类或接口的直接超接口数量。
Ⅱ. interfaces[](接口索引集合)
interfaces[]中每个成员的值必须是对常量池表中某项的有效索引值,它的长度为interfaces_count。每个成员interfaces[i]必须为CONSTANT_Class_info结构,其中0 <= i < interfaces_count。在interfaces[]中,各成员所表示的接口顺序和对应的源代码中给定的接口顺序(从左至右)一样,即interfaces[0]对应的是源代码中最左边的接口。
字段表集合
fields
-
用于描述接口或类中声明的变量。字段(field)包括类级变量以及实例级变量,但是不包括方法内部、代码块内部声明的局部变量。
-
字段叫什么名字、字段被定义为什么数据类型,这些都是无法固定的,只能引用常量池中的常量来描述。
-
它指向常量池索引集合,它描述了每个字段的完整信息。比如**字段的标识符、访问修饰符(public、private或protected)、是类变量还是实例变量(static修饰符)、是否是常量(final修饰符)**等。
注意事项:
- 字段表集合中不会列出从父类或者实现的接口中继承而来的字段,但有可能列出原本Java代码之中不存在的字段。譬如在内部类中为了保持对外部类的访问性,会自动添加指向外部类实例的字段。
- 在Java语言中字段是无法重载的,两个字段的数据类型、修饰符不管是否相同,都必须使用不一样的名称,但是对于字节码来讲,如果两个字段的描述符不一致,那字段重名就是合法的。
字段计数器
fields_count(字段计数器)
fields_count的值表示当前class文件fields表的成员个数。使用两个字节来表示。
fields[] (字段表)
fields表中每个成员都是一个field_info结构,用于表示该类或接口所声明的所有类字段或者实例字段,不包括方法内部声明的变量,也不包括从父类或父接口继承的那些字段。

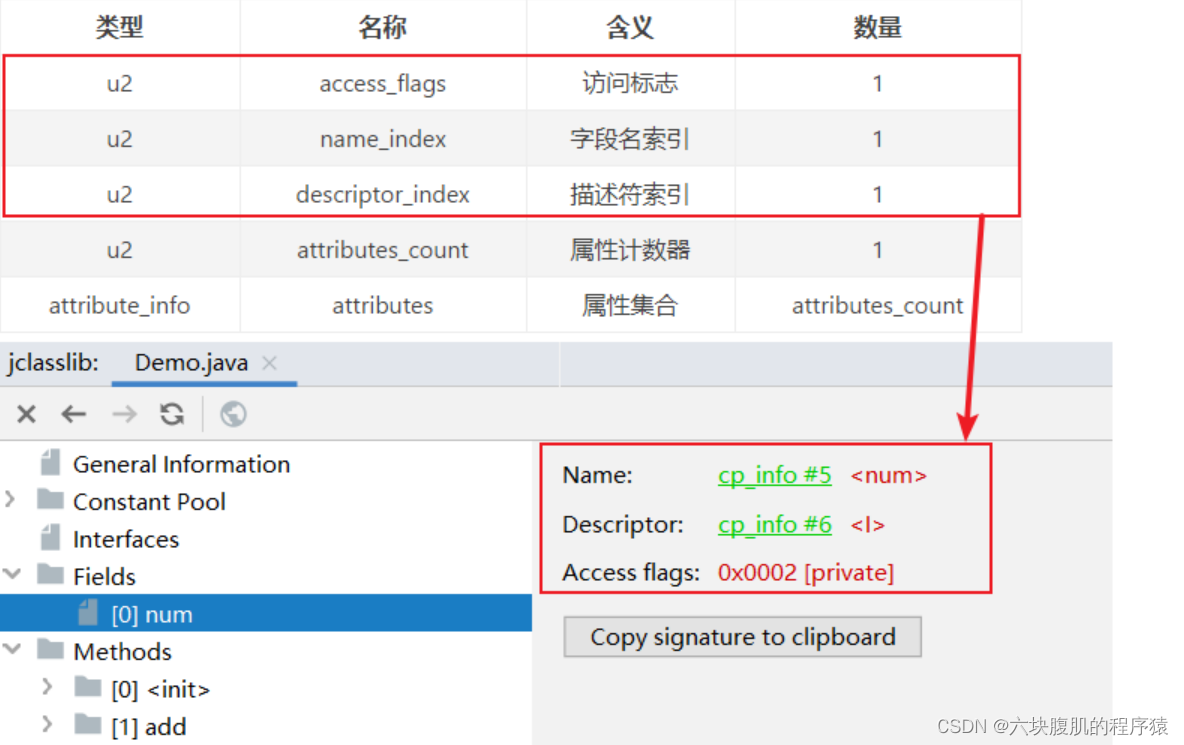
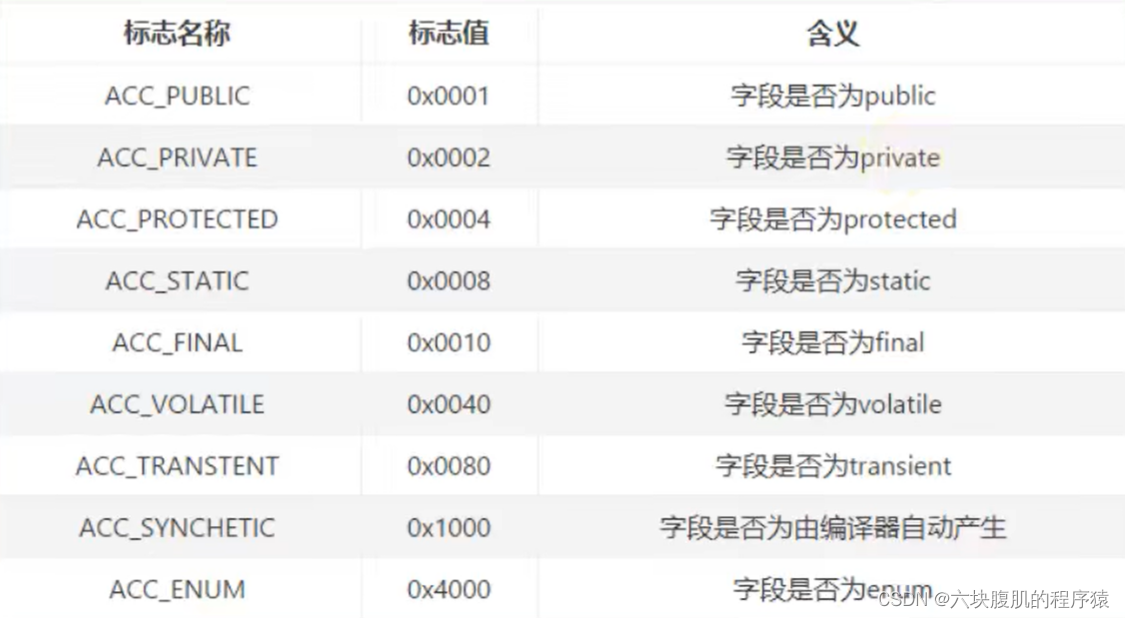
字段表访问标识
(我们知道,一个字段可以被各个关键字去修饰,比如:作用域修饰符(public、private、protected)、static修饰符、final修饰符、volatile修饰符等等。因此,其可像类的访问标志那样,使用一些标志来标记字段。字段的访问标志有如下这些)
描述符索引
描述符的作用是用来描述字段的数据类型、方法的参数列表(包括数量、类型以及顺序)和返回值。根据描述符规则,基本数据类型(byte,char,double,float,int,long,short,boolean)及代表无返回值的void类型都用一个大写字符来表示,而对象则用字符L加对象的全限定名来表示,如下所示:
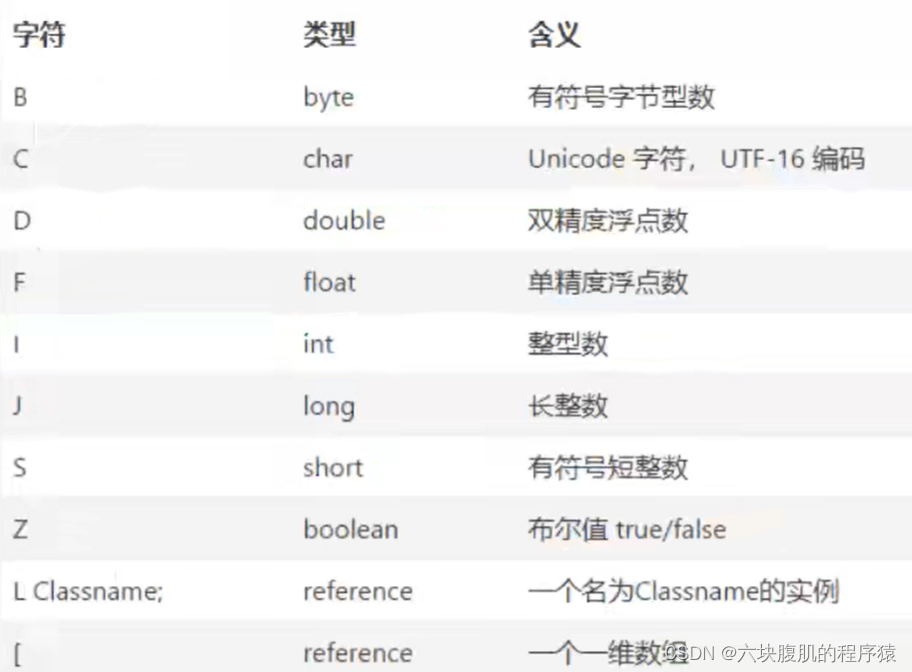
属性表集合
一个字段还可能拥有一些属性,用于存储更多的额外信息。比如初始化值、一些注释信息等。属性个数存放在attribute_count中,属性具体内容存放在attributes数组中
// 以常量属性为例,结构为:
ConstantValue_attribute{
u2 attribute_name_index;
u4 attribute_length;
u2 constantvalue_index;
}
说明:对于常量属性而言,attribute_length值恒为2。
方法表集合
methods:指向常量池索引集合,它完整描述了每个方法的签名。
- 在字节码文件中,每一个method_info项都对应着一个类或者接口中的方法信息。比如方法的访问修饰符(public、private或protected),方法的返回值类型以及方法的参数信息等。
- 如果这个方法不是抽象的或者不是native的,那么字节码中会体现出来。
- 一方面,methods表只描述当前类或接口中声明的方法,不包括从父类或父接口继承的方法。另一方面,methods表有可能会出现由编译器自动添加的方法,最典型的便是编译器产生的方法信息(比如:类(接口)初始化方法()和实例初始化方法())。
使用注意事项:
在Java语言中,要重载(Overload)一个方法,除了要与原方法具有相同的简单名称之外,还要求必须拥有一个与原方法不同的特征签名,特征签名就是一个方法中各个参数在常量池中的字段符号引用的集合,也就是因为返回值不会包含在特征签名之中,因此Java语言里无法仅仅依靠返回值的不同来对一个已有方法进行重载。但在Class文件格式中,特征签名的范围更大一些,只要描述符不是完全一致的两个方法就可以共存。也就是说,如果两个方法有相同的名称和特征签名,但返回值不同,那么也是可以合法共存于同一个class文件中。
也就是说,尽管Java语法规范并不允许在一个类或者接口中声明多个方法签名相同的方法,但是和Java语法规范相反,字节码文件中却恰恰允许存放多个方法签名相同的方法,唯一的条件就是这些方法之间的返回值不能相同。
methods_count(方法计数器)
methods_count的值表示当前class文件methods表的成员个数。使用两个字节来表示。
methods表中每个成员都是一个method_info结构。
methods[](方法表)
- methods表中的每个成员都必须是一个method_info结构,用于表示当前类或接口中某个方法的完整描述。如果某个method_info结构的access_flags项既没有设置ACC_NATIVE标志也没有设置ACC_ABSTRACT标志,那么该结构中也应包含实现这个方法所用的Java虚拟机指令。
- method_info结构可以表示类和接口中定义的所有方法,包括实例方法、类方法、实例初始化方法和类或接口初始化方法
- 方法表的结构实际跟字段表是一样的,方法表结构如下:
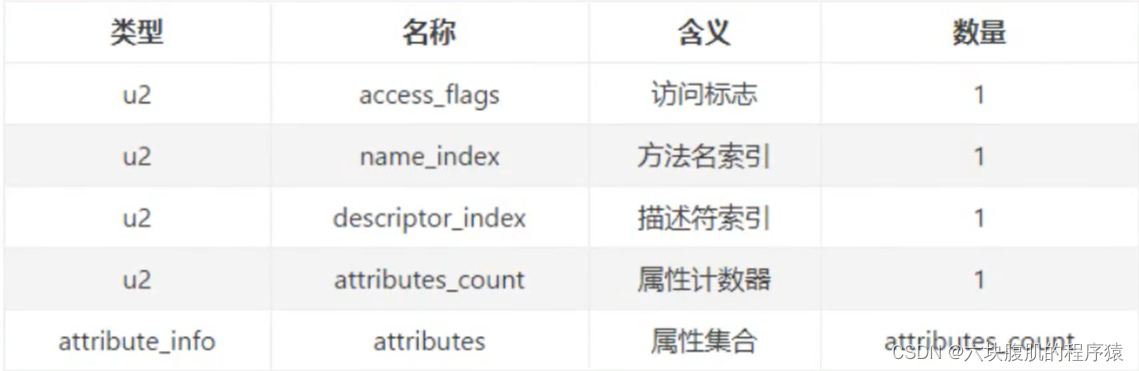
方法表访问标志
跟字段表一样,方法表也有访问标志,而且他们的标志有部分相同,部分则不同,方法表的具体访问标志如下:

属性表集合
方法表集合之后的属性表集合,指的是class文件所携带的辅助信息,比如该class文件的源文件的名称。以及任何带有RetentionPolicy.CLASS 或者RetentionPolicy.RUNTIME的注解。这类信息通常被用于Java虚拟机的验证和运行,以及Java程序的调试,一般无须深入了解。
此外,字段表、方法表都可以有自己的属性表。用于描述某些场景专有的信息。
属性表集合的限制没有那么严格,不再要求各个属性表具有严格的顺序,并且只要不与已有的属性名重复,任何人实现的编译器都可以向属性表中写入自己定义的属性信息,但Java虚拟机运行时会忽略掉它不认识的属性。
属性计数器
attributes_count(属性计数器)
attributes_count的值表示当前class文件属性表的成员个数。属性表中每一项都是一个attribute_info结构。
属性表
attributes[](属性表)
属性表的每个项的值必须是attribute_info结构。属性表的结构比较灵活,各种不同的属性只要满足以下结构即可。
属性的通用格式

属性类型
属性表实际上可以有很多类型,上面看到的Code属性只是其中一种,Java8里面定义了23种属性。下面这些是虚拟机中预定义的属性:

或者(查看官网)
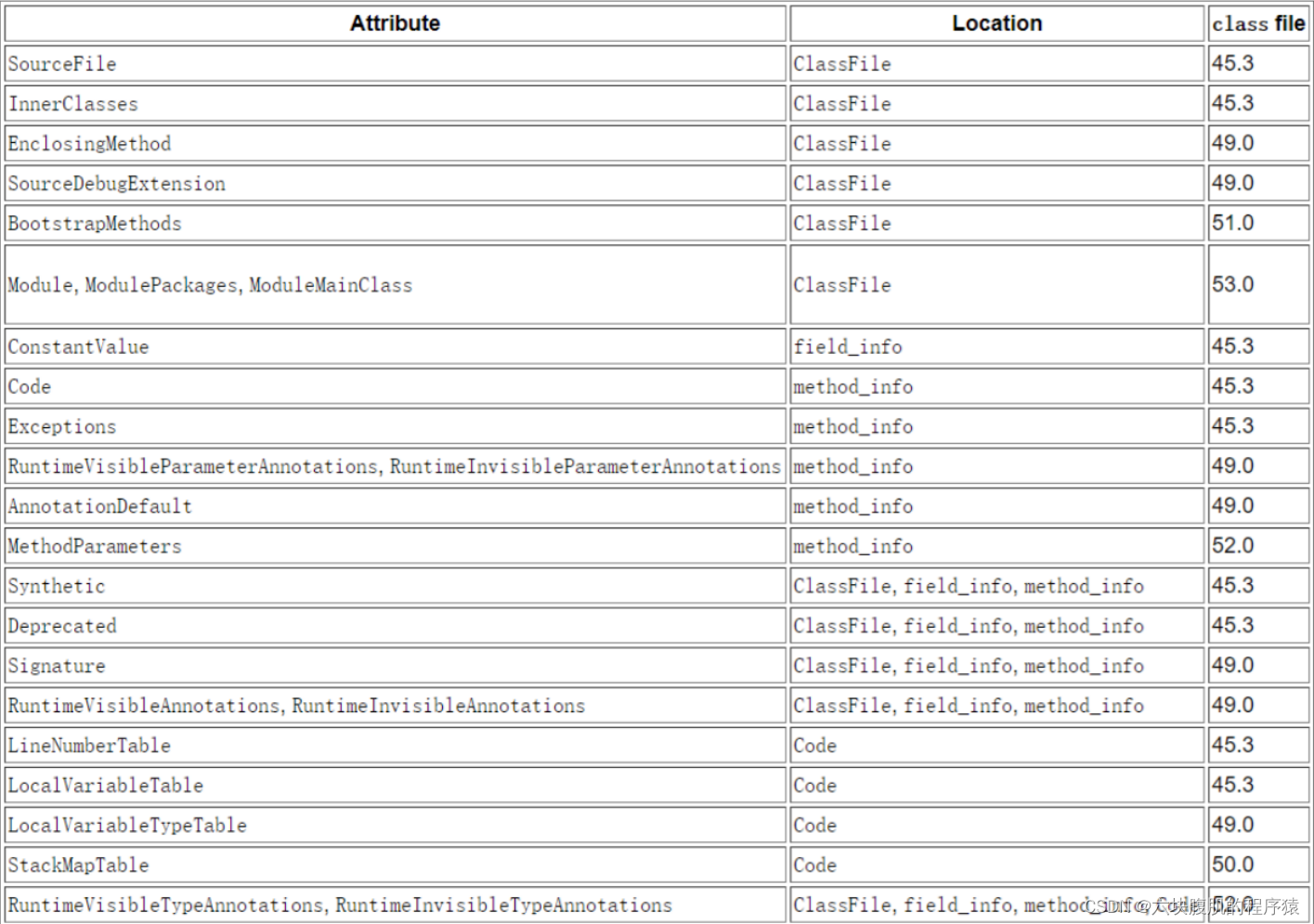
部分属性详解
① ConstantValue属性
ConstantValue属性表示一个常量字段的值。位于field_info结构的属性表中。
ConstantValue_attribute{
u2 attribute_name_index;
u4 attribute_length;
u2 constantvalue_index;//字段值在常量池中的索引,常量池在该索引处的项给出该属性表示的常量值。(例如,值是1ong型的,在常量池中便是CONSTANT_Long)
}
② Deprecated 属性
Deprecated 属性是在JDK1.1为了支持注释中的关键词@deprecated而引入的。
Deprecated_attribute{
u2 attribute_name_index;
u4 attribute_length;
}
③ Code属性
Code属性就是存放方法体里面的代码。但是,并非所有方法表都有Code属性。像接口或者抽象方法,他们没有具体的方法体,因此也就不会有Code属性了。Code属性表的结构,如下图:
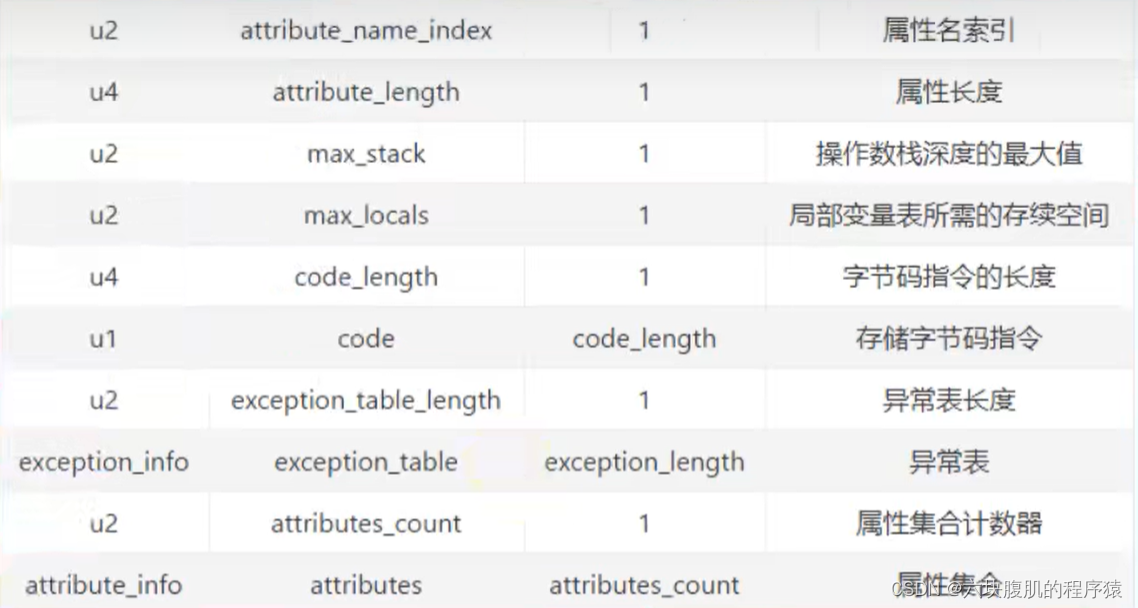
可以看到:Code属性表的前两项跟属性表是一致的,即Code属性表遵循属性表的结构,后面那些则是他自定义的结构。
④ InnerClasses 属性
为了方便说明特别定义一个表示类或接口的Class格式为C。如果C的常量池中包含某个CONSTANT_Class_info成员,且这个成员所表示的类或接口不属于任何一个包,那么C的ClassFile结构的属性表中就必须含有对应的InnerClasses属性。InnerClasses属性是在JDK1.1中为了支持内部类和内部接口而引入的,位于ClassFile结构的属性表。
⑤ LineNumberTable属性
LineNumberTable属性是可选变长属性,位于Code结构的属性表。
LineNumberTable属性是用来描述Java源码行号与字节码行号之间的对应关系。这个属性可以用来在调试的时候定位代码执行的行数。
- start_pc,即字节码行号;1ine_number,即Java源代码行号。
在Code属性的属性表中,LineNumberTable属性可以按照任意顺序出现,此外,多个LineNumberTable属性可以共同表示一个行号在源文件中表示的内容,即LineNumberTable属性不需要与源文件的行一一对应。
// LineNumberTable属性表结构:
LineNumberTable_attribute{
u2 attribute_name_index;
u4 attribute_length;
u2 line_number_table_length;
{
u2 start_pc;
u2 line_number;
} line_number_table[line_number_table_length];
}
⑥ LocalVariableTable属性
LocalVariableTable是可选变长属性,位于Code属性的属性表中。它被调试器用于确定方法在执行过程中局部变量的信息。在Code属性的属性表中,LocalVariableTable属性可以按照任意顺序出现。Code属性中的每个局部变量最多只能有一个LocalVariableTable属性。
start pc + length表示这个变量在字节码中的生命周期起始和结束的偏移位置(this生命周期从头e到结尾10)
index就是这个变量在局部变量表中的槽位(槽位可复用)
name就是变量名
Descriptor表示局部变量类型描述
// LocalVariableTable属性表结构:
LocalVariableTable_attribute{
u2 attribute_name_index;
u4 attribute_length;
u2 local_variable_table_length;
{
u2 start_pc;
u2 length;
u2 name_index;
u2 descriptor_index;
u2 index;
} local_variable_table[local_variable_table_length];
}
⑦ Signature属性
Signature属性是可选的定长属性,位于ClassFile,field_info或method_info结构的属性表中。在Java语言中,任何类、接口、初始化方法或成员的泛型签名如果包含了类型变量(Type Variables)或参数化类型(Parameterized Types),则Signature属性会为它记录泛型签名信息。
⑧ SourceFile属性
SourceFile属性结构
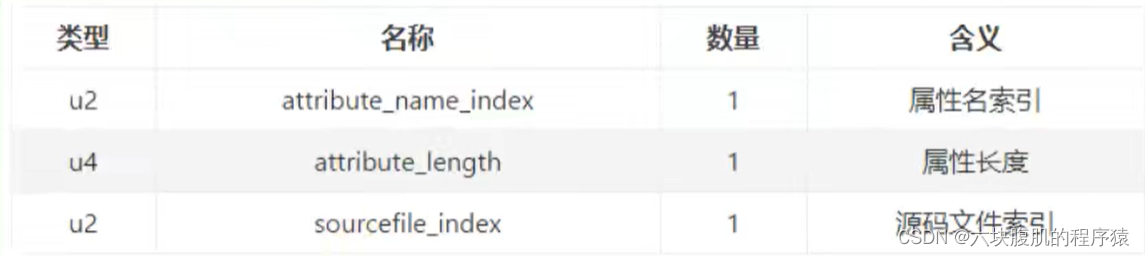
可以看到,其长度总是固定的8个字节。
⑨ 其他属性
Java虚拟机中预定义的属性有20多个,这里就不一一介绍了,通过上面几个属性的介绍,只要领会其精髓,其他属性的解读也是易如反掌。


![Rabbit客户端操作不同交换机[包含延迟类型]](https://img-blog.csdnimg.cn/b61baf95e18a431a82cd1ae06c2d1751.png)

![[牛客复盘] 牛客2022跨年场 20221212](https://img-blog.csdnimg.cn/07c2880706ad4a5eb2363567714be2e9.png)





![[ XSS-labs通关宝典 ] xss-labs 通关宝典之 less1 - less5](https://img-blog.csdnimg.cn/a125b39655294c87bb54d2a8c7691701.png)