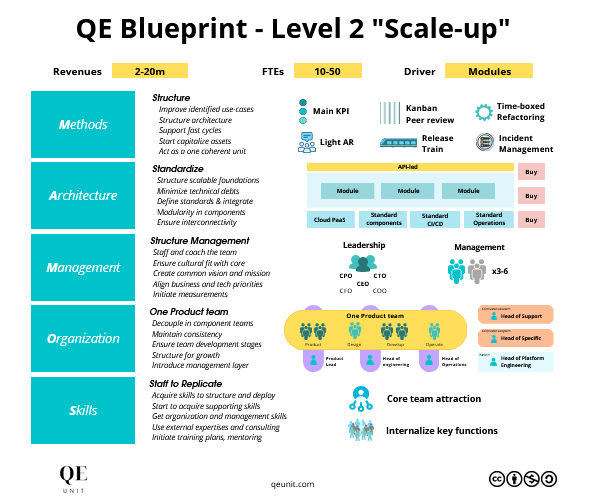
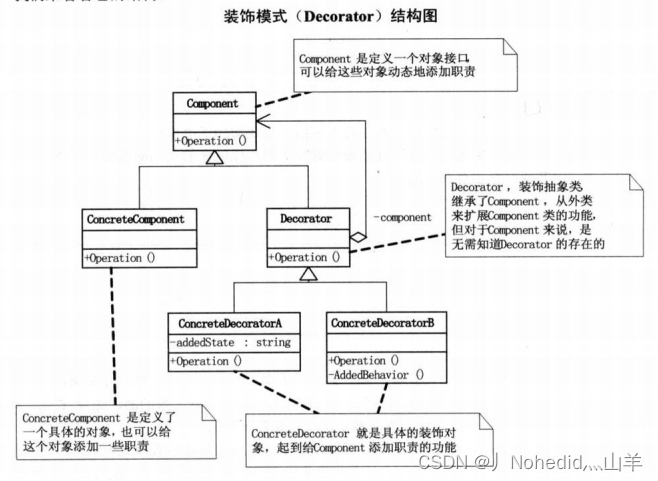
# 执行特征工程(交叉验证)
def perform_feature_engineering(df, features):
# 根据 features 中的内容选择特征生成函数
if 'typical_ma' in features:
df = calculate_typical_ma(df, window=10)
if 'RSI' in features:
df = calculate_rsi(df, column_name='Close', window=14)
# 其他特征的生成函数,按照类似的方式添加
# 合并所有特征
selected_features = ['date', 'Open', 'Close', 'High', 'Low', 'Volume']
selected_features.extend(features) # 将 features 中的特征添加到选定特征中
df = df[selected_features]
# 补全缺失值
for feature in features:
df[feature].fillna(method='bfill', inplace=True)
return df
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from datetime import datetime, timedelta
from keras.models import Sequential
from keras.layers import Dense, LSTM, GRU, Conv1D, Flatten, Dropout
from sklearn.preprocessing import StandardScaler
from keras.optimizers import Adam
import matplotlib.dates as mdates
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import TimeSeriesSplit
from tensorflow.keras.models import Sequential
from feature_engineering import calculate_rsi,calculate_typical_ma,perform_feature_engineering
from keras.callbacks import EarlyStopping
from keras.callbacks import LearningRateScheduler
from keras.regularizers import l2
from keras.layers import BatchNormalization
from keras import backend as K
K.clear_session()
look_back = 7
# 定义学习率调度函数
def lr_schedule(epoch):
lr = 0.1
if epoch > 50:
lr = 0.01
if epoch > 100:
lr = 0.001
return lr
# 创建 LearningRateScheduler 回调函数
lr_scheduler = LearningRateScheduler(lr_schedule)
# 定义函数以创建数据集
def create_dataset(dataset, look_back):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), :]
dataX.append(a)
dataY.append(dataset[i + look_back])
return np.array(dataX), np.array(dataY)
# 读取数据
df = pd.read_excel('C:/Users/47418/Desktop/data3.xlsx', sheet_name='Sheet1', parse_dates=['date'])
# 构建模型
model = Sequential()
model.add(Flatten(input_shape=(look_back, 1)))
model.add(Dense(64, activation='relu', kernel_regularizer=l2(0.01))) # 通过减少或增加层数来调整
model.add(Dropout(0.3))
model.add(Dense(32, activation='relu', kernel_regularizer=l2(0.01))) #神经元数量是32
model.add(Dropout(0.3))
model.add(BatchNormalization(momentum=0.9))#批量归一化
model.add(Dense(1, activation='linear'))
# 编译模型,调整学习率
optimizer = Adam() # 调整 learning_rate 的值
model.compile(optimizer=optimizer, loss='mean_squared_error', metrics=['mae', 'mse'])
feature_combinations = [
['typical_ma'],
['typical_ma', 'RSI'],
# 其他特征组合
]
prediction_results = {} # 用于存储预测值的字典
performance_results = [] # 记录调试数据的变量
results_list = [] # 存储每次测试的结果、特征组合和参数
for features in feature_combinations:
# 调用特征工程函数
df = perform_feature_engineering(df, features)
print(df.to_string())
# 获取数据值(根据交叉验证的特征调整)
feature_columns = ['date', 'Open', 'Close', 'High', 'Low', 'Volume'] + [f for feature in features for f in [feature]] # 对于features这个列表中的每个元素feature,将[feature]这个列表中的每个元素f添加到新的列表中。
values = df[feature_columns].iloc[:, 1:].values
# 将数据值缩放到0和1之间
scaler = MinMaxScaler(feature_range=(0, 1))
values_normalized = scaler.fit_transform(values.reshape(-1, 1))
# 创建训练集、验证集和测试集
train_size = int(len(values_normalized) * 0.67)
val_size = int(len(values_normalized) * 0.15)
test_size = len(values_normalized) - train_size - val_size
train, val, test = values_normalized[0:train_size, :], values_normalized[train_size:train_size+val_size, :], values_normalized[train_size+val_size:, :]
# 将输入重塑为 [样本,时间步长,特征]
trainX, trainY = create_dataset(train, look_back=look_back)
valX, valY = create_dataset(val, look_back=look_back)
trainX = np.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1))
valX = np.reshape(valX, (valX.shape[0], valX.shape[1], 1))
# 定义 TimeSeriesSplit
n_splits = 7
tscv = TimeSeriesSplit(n_splits=n_splits)
print(f"交叉验证的折数:\n", n_splits)
split_results = []
for train_index, test_index in tscv.split(trainX):
X_train, X_test = trainX[train_index], trainX[test_index]
y_train, y_test = trainY[train_index], trainY[test_index]
split_results.append((X_train, X_test, y_train, y_test))
# 在这里训练模型,评估模型等等
# X_train, y_train 是训练集的输入和输出
# X_test, y_test 是验证集的输入和输出
# 训练模型
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
lr_scheduler = LearningRateScheduler(lr_schedule)
history = model.fit(trainX, trainY, epochs=700, batch_size=8, verbose=4, validation_data=(valX, valY), callbacks=[early_stopping, lr_scheduler], shuffle=False)
# 预测未来5天的数据
future_data_normalized = model.predict(np.reshape(values_normalized[-look_back:], (1, look_back, 1)))
# 反向转换归一化的数据为实际数据
predicted_data = scaler.inverse_transform(future_data_normalized)
# 记录性能指标
metrics = model.evaluate(valX, valY, verbose=0)
# 记录预测值
future_data_normalized = model.predict(np.reshape(values_normalized[-look_back:], (1, look_back, 1)))
predicted_data = scaler.inverse_transform(future_data_normalized)
# 存储结果、特征组合和参数到字典
result_dict = {
'Features': features,
'Loss': metrics[0],
'MAE': metrics[1],
'MSE': metrics[2],
'Predicted_Data': predicted_data.squeeze().tolist(),
# 其他参数...
}
results_list.append(result_dict)
# 将字典列表转换为 DataFrame
results_df = pd.DataFrame(results_list)
# 保存 DataFrame 到 Excel 文件
results_df.to_excel('C:/Users/47418/Desktop/results_comparison.xlsx', index=False)





![力扣第一题-两数之和[简单]](https://img-blog.csdnimg.cn/img_convert/95229a89de8aa65a617c14dddaf7b0e4.png)