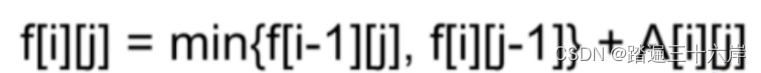引言
在持续集成的过程中,Jenkins Pipeline 是非常关键的一环。它定义了如何自动编译、测试和部署代码。随着项目的不断发展,Pipeline 的复杂性也在不断上升,这就需要我们持续优化 Pipeline 脚本,以提高代码的可读性和维护性。本文将介绍一次从繁琐Pipeline脚本到精简Pipeline脚本的转化过程,以及这种转化所带来的好处。
原始的 Pipeline 脚本:

注: loader其实已经废弃了
pipeline {
agent { label "build01" }
stages {
stage("GetCode"){
agent { label "build01" }
steps{
script{
println("下载代码 --> 分支: ${env.branchName}")
checkout([$class: 'GitSCM', branches: [[name: "${env.branchName}"]],
doGenerateSubmoduleConfigurations: false,
extensions: [[$class: 'CloneOption', depth: 1, noTags: false, reference: '', shallow: true]],
submoduleCfg: [],
userRemoteConfigs: [[credentialsId: 'xxxxx',
url: "${env.gitHttpURL}"]]])
}
}
}
stage('docker build dataloader-game-ucenter') {
agent { label "build01" }
when {
environment name: 'dataloader', value: 'true'
}
steps {
sh ''' cd dataloader
docker build --build-arg NODE_ENV=game-ucenter -t swr.cn-north-4.myhuaweicloud.com/master-metaspace/dataloader-game-ucenter:$data .'''
withCredentials([usernamePassword(credentialsId: 'hw-registry', passwordVariable: 'dockerPassword', usernameVariable: 'dockerUser')]) {
sh "docker login -u ${dockerUser} -p ${dockerPassword} swr.cn-north-4.myhuaweicloud.com"
sh "docker push swr.cn-north-4.myhuaweicloud.com/master-metaspace/dataloader-game-ucenter:$data"
}
}
}
stage('docker build datawriter-game-ucenter') {
agent { label "build01" }
when {
environment name: 'datawriter', value: 'true'
}
steps {
sh ''' cd datawriter-game-ucenter
docker build --build-arg NODE_ENV=game-ucenter -t swr.cn-north-4.myhuaweicloud.com/master-metaspace/datawriter-game-ucenter:$data .'''
withCredentials([usernamePassword(credentialsId: 'hw-registry', passwordVariable: 'dockerPassword', usernameVariable: 'dockerUser')]) {
sh "docker login -u ${dockerUser} -p ${dockerPassword} swr.cn-north-4.myhuaweicloud.com"
sh "docker push swr.cn-north-4.myhuaweicloud.com/master-metaspace/datawriter-game-ucenter:$data"
}
}
}
stage('docker build game-ucenter') {
agent { label "build01" }
when {
environment name: 'game-ucenter', value: 'true'
}
steps {
sh ''' cd game-ucenter
docker build --build-arg NODE_ENV=game-ucenter -t swr.cn-north-4.myhuaweicloud.com/master-metaspace/game-ucenter:$data .'''
withCredentials([usernamePassword(credentialsId: 'hw-registry', passwordVariable: 'dockerPassword', usernameVariable: 'dockerUser')]) {
sh "docker login -u ${dockerUser} -p ${dockerPassword} swr.cn-north-4.myhuaweicloud.com"
sh "docker push swr.cn-north-4.myhuaweicloud.com/master-metaspace/game-ucenter:$data"
}
}
}
stage('develop') {
parallel {
stage("develop datawriter-game-ucenter") {
when {
environment name: 'datawriter-game-ucenter', value: 'true'
}
agent { label "huaweiyun-xx" }
steps {
sh "sed -e 's/{data}/$data/g' /home/jenkins/workspace/yaml/master-metaspace/datawriter-game-ucenter.tpl > /home/jenkins/workspace/yaml/master-metaspace/datawriter-game-ucenter.yaml"
sh "sudo kubectl apply -f /home/jenkins/workspace/yaml/master-metaspace/datawriter-game-ucenter.yaml --namespace=master-metaspace --context=master"
}
}
stage("develop dataloader-game-ucenter") {
when {
environment name: 'dataloader', value: 'true'
}
agent { label "huaweiyun-xx" }
steps {
sh "sed -e 's/{data}/$data/g' /home/jenkins/workspace/yaml/master-metaspace/dataloader-game-ucenter.tpl > /home/jenkins/workspace/yaml/master-metaspace/dataloader-game-ucenter.yaml"
sh "sudo kubectl apply -f /home/jenkins/workspace/yaml/master-metaspace/dataloader-game-ucenter.yaml --namespace=master-metaspace --context=master"
}
}
stage("develop game-ucenter") {
when {
environment name: 'game-ucenter', value: 'true'
}
agent { label "huaweiyun-xx" }
steps {
sh "sed -e 's/{data}/$data/g' /home/jenkins/workspace/yaml/master-metaspace/game-ucenter.tpl > /home/jenkins/workspace/yaml/master-metaspace/game-ucenter.yaml"
sh "sudo kubectl apply -f /home/jenkins/workspace/yaml/master-metaspace/game-ucenter.yaml --namespace=master-metaspace --context=master"
}
}
}
}
}
}
在优化之前,我们的 Jenkins Pipeline 脚本中包含了多个独立定义的 stage,每个 stage 中都有重复的结构和指令:
- 明确指定了 agent。
- 在每个 stage 的 steps 中,都使用了类似的脚本来操作 git、构建 docker 镜像和部署到 Kubernetes。
- 使用了冗长的 shell 脚本来绑定变量和执行部署。
这种写法虽然直观,但存在以下问题:
- 代码冗余:相同的任务(例如构建与部署)重复编写了多次。
- 低效的修改:一旦需要调整构建或部署流程,需要同时修改多个类似的代码段。
- 可读性差:过于细碎的脚本内容使得新成员阅读和理解这个 Pipeline 变得困难。
转化的原因与过程
简化 agent 的声明
pipeline {
agent none // Use none at the top level, each stage will define its own agent.
}
在原始脚本中,每个 stage 都重复指定相同的 agent,这是不必要的。转化后,我们在 pipeline 的顶层使用 agent none 声明,表示不在这一层级指定执行者,这样各个 stage 就可以根据需求独立地声明自己的 agent。
将环境变量统一管理
我们创建一个 environment 部分来集中定义环境变量,简化了变量的管理,并且当需要修改时只要在一个地方进行调整即可。
environment {
REGISTRY = "swr.cn-north-4.myhuaweicloud.com/master-metaspace"
KUBE_CONFIG = "--namespace=master-metaspace --context=master"
KUBE_YAML_PATH = "/home/jenkins/workspace/yaml/master-metaspace"
// Assume that 'data' is defined elsewhere or injected as a parameter.
}
使用共用方法减少代码重复
对于 Docker 镜像的构建和推送操作,每个应用几乎执行相同的步骤。我们提取了一个方法 buildAndPushDockerImage 来代替在每个 stage 里重复定义的步骤,这样不但减小了脚本体积,也提升了代码的复用性。
def buildAndPushDockerImage(String imageName, String tag) {
sh "cd $imageName && docker build --build-arg NODE_ENV=$imageName -t $REGISTRY/$imageName:$tag ."
withCredentials([usernamePassword(credentialsId: 'hw-registry', passwordVariable: 'dockerPassword', usernameVariable: 'dockerUser')]) {
sh "docker login -u $dockerUser -p $dockerPassword $REGISTRY"
sh "docker push $REGISTRY/$imageName:$tag"
}
}
同理,部署到 Kubernetes 的指令也被提取到了 deployToKubernetes 方法中,进一步去重。
def deployToKubernetes(String kubernetesComponent) {
String templateFile = "${KUBE_YAML_PATH}/${kubernetesComponent}.tpl"
String outputFile = "${KUBE_YAML_PATH}/${kubernetesComponent}.yaml"
sh "sed -e 's/{data}/$data/g' $templateFile > $outputFile"
sh "sudo kubectl apply -f $outputFile $KUBE_CONFIG"
}
结构的并行化
将 Docker 构建步骤组合为一个并行执行的 stage,这样不仅可以缩短整个流水线的执行时间,还可以使得结构更加清晰。
stage("Docker Builds") {
parallel {
stage('Build dataloader-game-ucenter') {
agent { label "build01" }
when { environment name: 'dataloader', value: 'true' }
steps {
buildAndPushDockerImage("dataloader-game-ucenter", env.data, env.BASE_WORKSPACE)
}
}
stage('Build datawriter-game-ucenter') {
agent { label "build01" }
when { environment name: 'datawriter', value: 'true' }
steps {
buildAndPushDockerImage("datawriter-game-ucenter", env.data, env.BASE_WORKSPACE)
}
}
stage('Build game-ucenter') {
agent { label "build01" }
when { environment name: 'game-ucenter', value: 'true' }
steps {
buildAndPushDockerImage("game-ucenter", env.data, env.BASE_WORKSPACE)
}
}
}
}
转化后的好处
转换后的pipeline如下:
pipeline {
agent none // Use none at the top level, each stage will define its own agent.
environment {
REGISTRY = "swr.cn-north-4.myhuaweicloud.com/master-metaspace"
KUBE_CONFIG = "--namespace=master-metaspace --context=master"
KUBE_YAML_PATH = "/home/jenkins/workspace/yaml/master-metaspace"
// Assume that 'data' is defined elsewhere or injected as a parameter.
BASE_WORKSPACE = "xxxxxxx" // 定义一个基础工作空间路径
}
stages {
stage("GetCode") {
agent { label "build01" }
steps {
script {
checkout scm: [
$class: 'GitSCM',
branches: [[name: env.branchName]],
extensions: [[$class: 'CloneOption', depth: 1, noTags: false, shallow: true]],
userRemoteConfigs: [[credentialsId: 'xxxx', url: env.gitHttpURL]]
]
}
}
}
stage("Docker Builds") {
parallel {
stage('Build dataloader-game-ucenter') {
agent { label "build01" }
when { environment name: 'dataloader', value: 'true' }
steps {
buildAndPushDockerImage("dataloader-game-ucenter", env.data, env.BASE_WORKSPACE)
}
}
stage('Build datawriter-game-ucenter') {
agent { label "build01" }
when { environment name: 'datawriter', value: 'true' }
steps {
buildAndPushDockerImage("datawriter-game-ucenter", env.data, env.BASE_WORKSPACE)
}
}
stage('Build game-ucenter') {
agent { label "build01" }
when { environment name: 'game-ucenter', value: 'true' }
steps {
buildAndPushDockerImage("game-ucenter", env.data, env.BASE_WORKSPACE)
}
}
}
}
stage('Development Deployment') {
parallel {
stage("Deploy datawriter-game-ucenter") {
when { environment name: 'datawriter-game-ucenter', value: 'true' }
agent { label "huaweiyun-xx" }
steps {
deployToKubernetes("datawriter-game-ucenter")
}
}
stage("Deploy dataloader-game-ucenter") {
when { environment name: 'dataloader', value: 'true' }
agent { label "huaweiyun-xx" }
steps {
deployToKubernetes("dataloader-game-ucenter")
}
}
stage("Deploy game-ucenter") {
when { environment name: 'game-ucenter', value: 'true' }
agent { label "huaweiyun-xx" }
steps {
deployToKubernetes("game-ucenter")
}
}
}
}
}
}
// Define methods outside pipeline to avoid repetition
def buildAndPushDockerImage(String imageName, String tag, String workspacePath) {
sh "cd ${workspacePath} && echo 'Current directory: \$(pwd)'" // 使用基础工作空间变量
sh "cd ${workspacePath}/${imageName}&& docker build --build-arg NODE_ENV=$imageName -t $REGISTRY/$imageName:$tag ."
withCredentials([usernamePassword(credentialsId: 'hw-registry', passwordVariable: 'dockerPassword', usernameVariable: 'dockerUser')]) {
sh "docker login -u $dockerUser -p $dockerPassword $REGISTRY"
sh "docker push $REGISTRY/$imageName:$tag"
}
}
def deployToKubernetes(String kubernetesComponent) {
String templateFile = "${KUBE_YAML_PATH}/${kubernetesComponent}.tpl"
String outputFile = "${KUBE_YAML_PATH}/${kubernetesComponent}.yaml"
sh "sed -e 's/{data}/$data/g' $templateFile > $outputFile"
sh "sudo kubectl apply -f $outputFile $KUBE_CONFIG"
}
- 代码结构清晰:每个阶段的职责更加明确,整个 Pipeline 结构变得简单易懂。
- 维护成本降低:通用操作被封装成方法,避免了重复代码,当流程需要修改时,只需在一个地方更新。
- 执行效率提升:使用 parallel 来并行构建 Docker 镜像降低了整体构建时间。
- 可扩展性增加:如果将来要增加新的镜像构建或者 Kubernetes 部署,只需很少的修改即可。
总结来说,通过优化 Jenkins Pipeline 脚本,我们不仅提高了流程的效率,还大大减小了维护成本。在持续集成和持续部署的实践中,拥有一个简洁和高效的 Pipeline 是至关重要的。
特意强调的
environment 添加了BASE_WORKSPACE,why?
在Jenkins中,当你在一个Pipeline中使用并行步骤执行作业时,默认情况下,每个并行的分支都会创建一个新的工作空间目录,格式一般为workspace@2、workspace@3等,这样做是为了避免各个分支之间产生文件系统上的冲突。
这样带来的后果就是:
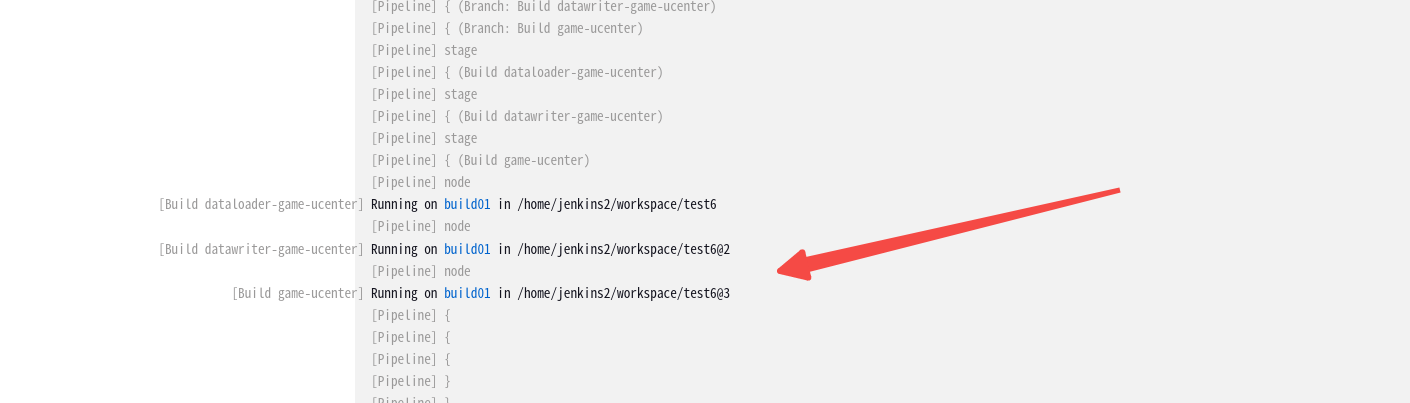
构建过程中就会出现No such file or directory这样的报错:

所以这里引入了BASE_WORKSPACE
environment {
REGISTRY = "swr.cn-north-4.myhuaweicloud.com/master-metaspace"
KUBE_CONFIG = "--namespace=master-metaspace --context=master"
KUBE_YAML_PATH = "/home/jenkins/workspace/yaml/master-metaspace"
// Assume that 'data' is defined elsewhere or injected as a parameter.
BASE_WORKSPACE = "/home/jenkins2/workspace/test6" // 定义一个基础工作空间路径
}
build过程中引入了:
sh "cd ${workspacePath} && echo 'Current directory: \$(pwd)'"
确保并行步骤中引用到正确的工作空间目录!
注: 以上脚本代码转换后的pipeline使用chatgpt生成,并多次修订!