本文介绍一些注意力机制的实现,包括EA/MHSA/SK/DA/EPSA。
【深度学习】注意力机制(一)
【深度学习】注意力机制(三)
目录
一、EA(External Attention)
二、Multi Head Self Attention
三、SK(Selective Kernel Networks)
四、DA(Dual Attention)
五、EPSA(Efficient Pyramid Squeeze Attention)
一、EA(External Attention)
EA可以关注全局的空间信息,论文:论文地址
如下图:

代码如下(代码连接):
import numpy as np
import torch
from torch import nn
from torch.nn import init
class External_attention(nn.Module):
'''
Arguments:
c (int): The input and output channel number.
'''
def __init__(self, c):
super(External_attention, self).__init__()
self.conv1 = nn.Conv2d(c, c, 1)
self.k = 64
self.linear_0 = nn.Conv1d(c, self.k, 1, bias=False)
self.linear_1 = nn.Conv1d(self.k, c, 1, bias=False)
self.linear_1.weight.data = self.linear_0.weight.data.permute(1, 0, 2)
self.conv2 = nn.Sequential(
nn.Conv2d(c, c, 1, bias=False),
norm_layer(c))
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.Conv1d):
n = m.kernel_size[0] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, _BatchNorm):
m.weight.data.fill_(1)
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
idn = x
x = self.conv1(x)
b, c, h, w = x.size()
n = h*w
x = x.view(b, c, h*w) # b * c * n
attn = self.linear_0(x) # b, k, n
attn = F.softmax(attn, dim=-1) # b, k, n
attn = attn / (1e-9 + attn.sum(dim=1, keepdim=True)) # # b, k, n
x = self.linear_1(attn) # b, c, n
x = x.view(b, c, h, w)
x = self.conv2(x)
x = x + idn
x = F.relu(x)
return x二、Multi Head Self Attention
注意力机制的经典,Transformer的基石。论文:论文地址
如下图:
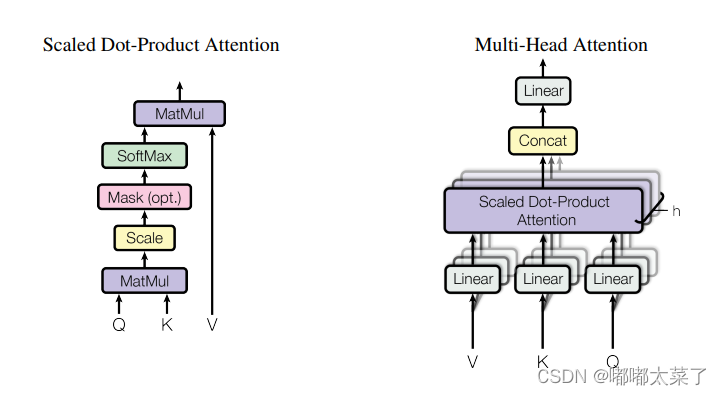
代码如下(代码连接):
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ScaledDotProductAttention(nn.Module):
'''
Scaled dot-product attention
'''
def __init__(self, d_model, d_k, d_v, h,dropout=.1):
'''
:param d_model: Output dimensionality of the model
:param d_k: Dimensionality of queries and keys
:param d_v: Dimensionality of values
:param h: Number of heads
'''
super(ScaledDotProductAttention, self).__init__()
self.fc_q = nn.Linear(d_model, h * d_k)
self.fc_k = nn.Linear(d_model, h * d_k)
self.fc_v = nn.Linear(d_model, h * d_v)
self.fc_o = nn.Linear(h * d_v, d_model)
self.dropout=nn.Dropout(dropout)
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.h = h
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
'''
Computes
:param queries: Queries (b_s, nq, d_model)
:param keys: Keys (b_s, nk, d_model)
:param values: Values (b_s, nk, d_model)
:param attention_mask: Mask over attention values (b_s, h, nq, nk). True indicates masking.
:param attention_weights: Multiplicative weights for attention values (b_s, h, nq, nk).
:return:
'''
b_s, nq = queries.shape[:2]
nk = keys.shape[1]
q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, nk)
if attention_weights is not None:
att = att * attention_weights
if attention_mask is not None:
att = att.masked_fill(attention_mask, -np.inf)
att = torch.softmax(att, -1)
att=self.dropout(att)
out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
return out三、SK(Selective Kernel Networks)
SK是通道注意力机制。论文地址:论文连接
如下图:

代码如下(代码连接):
import numpy as np
import torch
from torch import nn
from torch.nn import init
from collections import OrderedDict
class SKAttention(nn.Module):
def __init__(self, channel=512,kernels=[1,3,5,7],reduction=16,group=1,L=32):
super().__init__()
self.d=max(L,channel//reduction)
self.convs=nn.ModuleList([])
for k in kernels:
self.convs.append(
nn.Sequential(OrderedDict([
('conv',nn.Conv2d(channel,channel,kernel_size=k,padding=k//2,groups=group)),
('bn',nn.BatchNorm2d(channel)),
('relu',nn.ReLU())
]))
)
self.fc=nn.Linear(channel,self.d)
self.fcs=nn.ModuleList([])
for i in range(len(kernels)):
self.fcs.append(nn.Linear(self.d,channel))
self.softmax=nn.Softmax(dim=0)
def forward(self, x):
bs, c, _, _ = x.size()
conv_outs=[]
### split
for conv in self.convs:
conv_outs.append(conv(x))
feats=torch.stack(conv_outs,0)#k,bs,channel,h,w
### fuse
U=sum(conv_outs) #bs,c,h,w
### reduction channel
S=U.mean(-1).mean(-1) #bs,c
Z=self.fc(S) #bs,d
### calculate attention weight
weights=[]
for fc in self.fcs:
weight=fc(Z)
weights.append(weight.view(bs,c,1,1)) #bs,channel
attention_weughts=torch.stack(weights,0)#k,bs,channel,1,1
attention_weughts=self.softmax(attention_weughts)#k,bs,channel,1,1
### fuse
V=(attention_weughts*feats).sum(0)
return V
四、DA(Dual Attention)
DA融合了通道注意力和空间注意力机制。论文:论文地址
如下图:
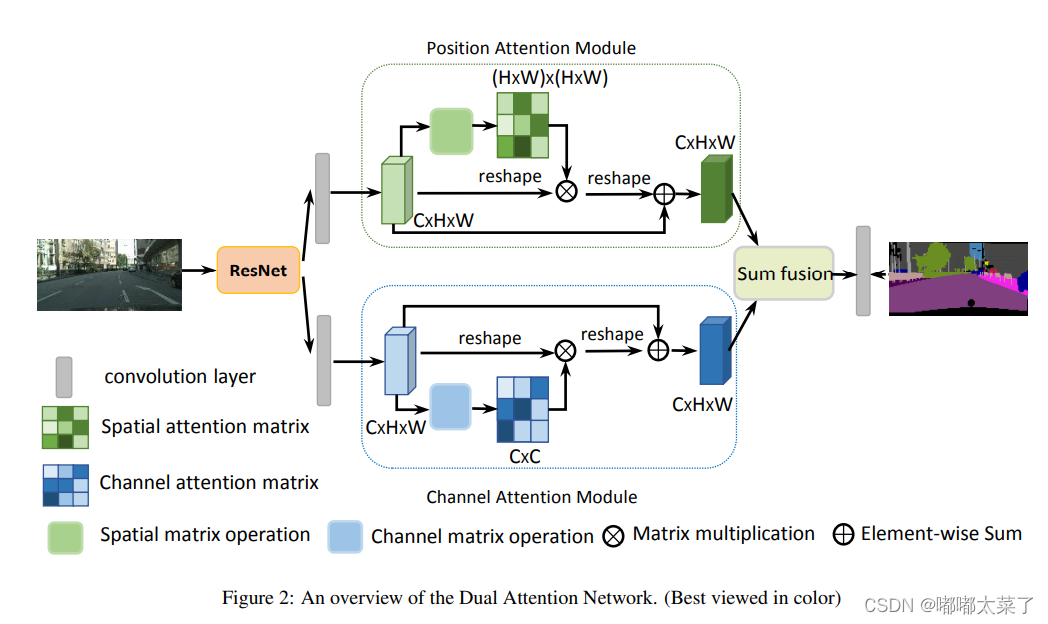
代码(代码连接):
import numpy as np
import torch
from torch import nn
from torch.nn import init
from model.attention.SelfAttention import ScaledDotProductAttention
from model.attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
class PositionAttentionModule(nn.Module):
def __init__(self,d_model=512,kernel_size=3,H=7,W=7):
super().__init__()
self.cnn=nn.Conv2d(d_model,d_model,kernel_size=kernel_size,padding=(kernel_size-1)//2)
self.pa=ScaledDotProductAttention(d_model,d_k=d_model,d_v=d_model,h=1)
def forward(self,x):
bs,c,h,w=x.shape
y=self.cnn(x)
y=y.view(bs,c,-1).permute(0,2,1) #bs,h*w,c
y=self.pa(y,y,y) #bs,h*w,c
return y
class ChannelAttentionModule(nn.Module):
def __init__(self,d_model=512,kernel_size=3,H=7,W=7):
super().__init__()
self.cnn=nn.Conv2d(d_model,d_model,kernel_size=kernel_size,padding=(kernel_size-1)//2)
self.pa=SimplifiedScaledDotProductAttention(H*W,h=1)
def forward(self,x):
bs,c,h,w=x.shape
y=self.cnn(x)
y=y.view(bs,c,-1) #bs,c,h*w
y=self.pa(y,y,y) #bs,c,h*w
return y
class DAModule(nn.Module):
def __init__(self,d_model=512,kernel_size=3,H=7,W=7):
super().__init__()
self.position_attention_module=PositionAttentionModule(d_model=512,kernel_size=3,H=7,W=7)
self.channel_attention_module=ChannelAttentionModule(d_model=512,kernel_size=3,H=7,W=7)
def forward(self,input):
bs,c,h,w=input.shape
p_out=self.position_attention_module(input)
c_out=self.channel_attention_module(input)
p_out=p_out.permute(0,2,1).view(bs,c,h,w)
c_out=c_out.view(bs,c,h,w)
return p_out+c_out五、EPSA(Efficient Pyramid Squeeze Attention)
论文:论文地址
如下图:
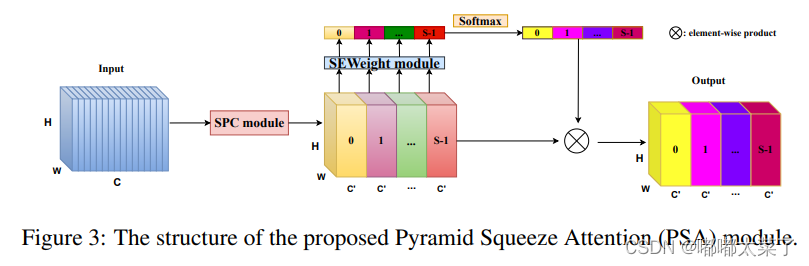
代码如下(代码连接):
import torch.nn as nn
class SEWeightModule(nn.Module):
def __init__(self, channels, reduction=16):
super(SEWeightModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(channels, channels//reduction, kernel_size=1, padding=0)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(channels//reduction, channels, kernel_size=1, padding=0)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.avg_pool(x)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
weight = self.sigmoid(out)
return weight
def conv(in_planes, out_planes, kernel_size=3, stride=1, padding=1, dilation=1, groups=1):
"""standard convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=False)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class PSAModule(nn.Module):
def __init__(self, inplans, planes, conv_kernels=[3, 5, 7, 9], stride=1, conv_groups=[1, 4, 8, 16]):
super(PSAModule, self).__init__()
self.conv_1 = conv(inplans, planes//4, kernel_size=conv_kernels[0], padding=conv_kernels[0]//2,
stride=stride, groups=conv_groups[0])
self.conv_2 = conv(inplans, planes//4, kernel_size=conv_kernels[1], padding=conv_kernels[1]//2,
stride=stride, groups=conv_groups[1])
self.conv_3 = conv(inplans, planes//4, kernel_size=conv_kernels[2], padding=conv_kernels[2]//2,
stride=stride, groups=conv_groups[2])
self.conv_4 = conv(inplans, planes//4, kernel_size=conv_kernels[3], padding=conv_kernels[3]//2,
stride=stride, groups=conv_groups[3])
self.se = SEWeightModule(planes // 4)
self.split_channel = planes // 4
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
batch_size = x.shape[0]
x1 = self.conv_1(x)
x2 = self.conv_2(x)
x3 = self.conv_3(x)
x4 = self.conv_4(x)
feats = torch.cat((x1, x2, x3, x4), dim=1)
feats = feats.view(batch_size, 4, self.split_channel, feats.shape[2], feats.shape[3])
x1_se = self.se(x1)
x2_se = self.se(x2)
x3_se = self.se(x3)
x4_se = self.se(x4)
x_se = torch.cat((x1_se, x2_se, x3_se, x4_se), dim=1)
attention_vectors = x_se.view(batch_size, 4, self.split_channel, 1, 1)
attention_vectors = self.softmax(attention_vectors)
feats_weight = feats * attention_vectors
for i in range(4):
x_se_weight_fp = feats_weight[:, i, :, :]
if i == 0:
out = x_se_weight_fp
else:
out = torch.cat((x_se_weight_fp, out), 1)
return out