▼最近直播超级多,预约保你有收获
今晚直播:《AI编程+向量数据库架构设计案例实践》
—1—
大模型的“数据局限性”
数据局限对企业做 LLM 大模型带来的影响,可归结为以下三点:
第一点:对数据的管理和运维。随着文本、图片、视频等多模态的、非结构化数据的使用需求增加,许多企业所产出的非结构化数据量级可高达 80%,如果选择以预训练的方式将数据“喂”给模型,与之而来的则是难以承载的高成本。
第二点:虽然大模型支持的 token 数量在持续增加,具备了“短暂记忆”的能力,但“一本正经地胡说八道”的问题仍无法解决,当中不乏有敏感内容的出现,稍不注意,便可能带来严重的影响。因此,支撑模型训练的数据不仅要数量多,质量也必须足够高。
第三点:如何保障企业数据的安全性,数据在空间和时间上会有很大的限制。
如何解决企业和大模型落地之间的数据宏观,主要有以下两种解决方案。
一是采用 Fine-tuning 的方式迭代演进,让大模型学到更多的知识;二是通过 Vector search 的方法,把最新的私域知识存在向量数据库中,需要时在向量数据库中做基于语义的向量检索,这两种方法都可以为大模型提供更加精准的答案。
但是从成本方面来看,向量数据库的成本仅为 Fine-tuning 的千分之一。向量数据库通过把数据向量化,进行存储和查询可以有效解决大模型预训练成本高、没有“长期记忆”、幻觉、知识更新不及时等问题。
因此,凭借其优势,向量数据库也被视为了加速大模型落地行业场景的关键突破口。
—2—
向量数据库的大模型之路
自 LLM 大模型火爆以来,原已沉寂多年的向量数据库再次受到企业和资本市场的高度关注,比如腾讯今年 7 月便正式上线了向量数据库 Tencent Cloud VectorDB,并在 11 月 1 日全量开放公测。
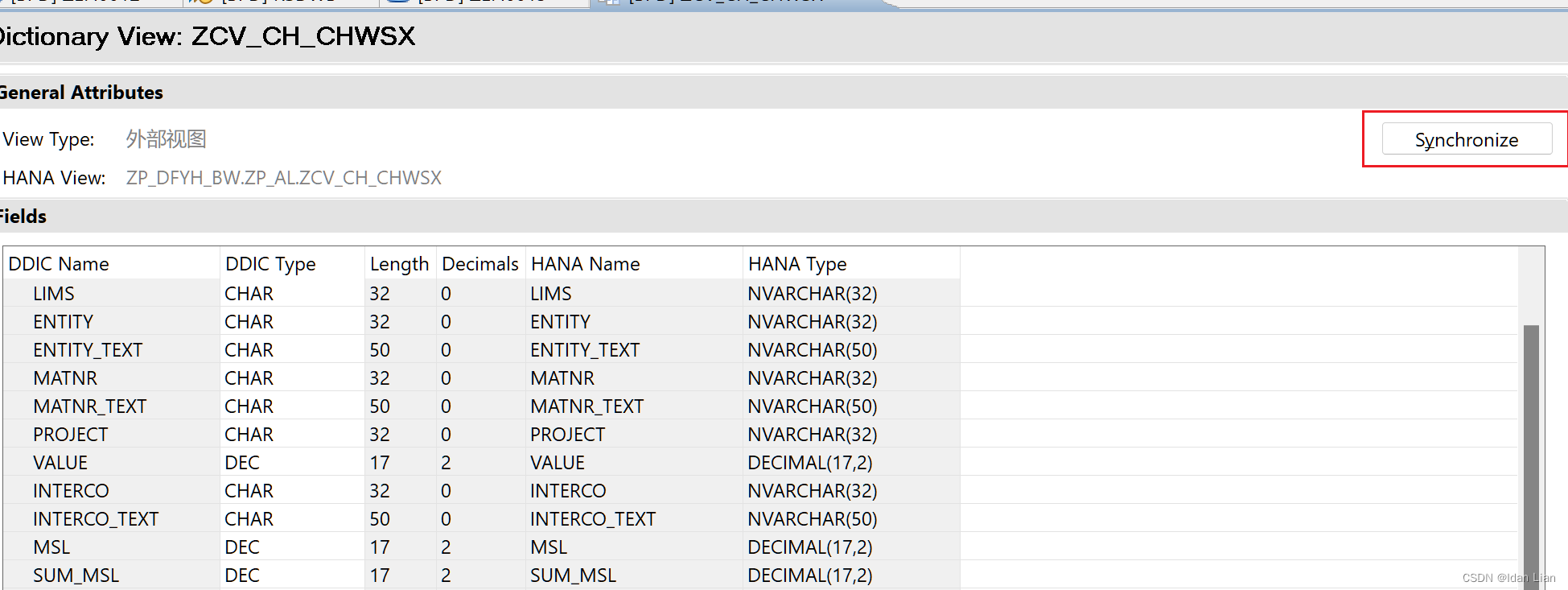
首先在架构上,腾讯云就采用了 AI 原生的开发架构,从接入层、计算层、存储层提供给全面 AI 化的解决方案,形成一套完整的端到端、一站式服务技术栈,让不同阶段、不同需求的用户,都能在腾讯云向量数据库里找到对应可用的 AI 能力。

第一、在接入层上,腾讯云向量数据库支持自然语言文本的数据,采用“标量+向量”的查询方式,可支持全内存索引;计算层,AI 原生的开发范式能实现全量数据 AI 计算,一站解决企业搭建私域知识库时数据切分等难题。
第二、集成了 Embedding 功能,企业用户无需关注向量生成过程,使用起来更简单。

除了接入层和 Embedding 外,向量数据库的核心技术到底是怎么设计的?在企业级应用侧,向量数据库也从以搜索、广告、推荐为主要服务领域,随着 AI 的大规模发展,开始深入千行百业中去,与 C 端用户链接也更加紧密。具体的实践案例有哪些?如何实践落地的?
今晚20点直播告诉你,直播精彩看点:
1、编程辅助技术与 AI 编程模型剖析
2、向量数据库架构剖析与检索技术详解
3、视频实时推荐系统架构设计与实践案例
4、AI 辅助编程完成即时通讯系统开发实践
请同学点击下方按钮预约直播,咱们今晚20点直播见!
END