本文原文来自DataLearnerAI:
准备迎接超级人工智能系统,OpenAI宣布RLHF即将终结!超级对齐技术将接任RLHF,保证超级人工智能系统遵循人类的意志 | 数据学习者官方网站(Datalearner)![]() https://www.datalearner.com/blog/1051702655263827
https://www.datalearner.com/blog/1051702655263827
今天,OpenAI在其官网上发布了一个全新的研究成果:一个利用较弱的模型来引导对齐更强模型的能力的技术,称为由弱到强的泛化。OpenAI认为,未来十年来将诞生超过人类的超级AI系统。但是,这会出现一个问题,即基于人类反馈的强化学习技术将终结。因为彼时,人类的水平不如AI系统,所以可能无法再对模型输出的内容评估好坏。为此,OpenAI提出这种超级对齐技术,希望可以用较弱的模型来对齐较强的模型。这样可以在出现比人类更强的AI系统之后可以继续让AI模型可以遵循人类的意志、偏好和价值观。

- RLHF技术及其问题
- RLHF面临超人类AI系统可能是不行的
- 为什么要做弱AI监督引导强AI
- 超级对齐
- 超级对齐的实验总结
- 总结
RLHF技术及其问题
RLHF全称Reinforcement Learning from Human Feedback,是当前大语言模型在微调之后必不可少的一个步骤。简单来说,就是让模型输出结果,人类提供结果反馈,然后模型学习理解哪些输出是更好的,这里所说的更好包括道德、价值观以及回复质量等。
总的来说,RLHF是当前大语言模型质量提升的一个必备步骤。但是,大家可以看到这其中的核心一个步骤是让『人类』来判断好坏。
RLHF面临超人类AI系统可能是不行的。
为什么要做弱AI监督引导强AI
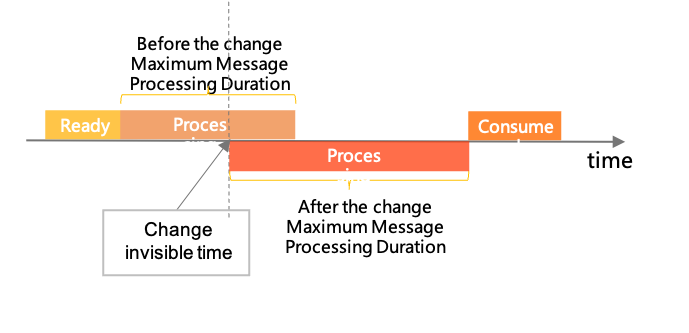
如前所述,此前的强化学习是人类比模型强的情况下推出的如下图所示,是一个示意图:

在未来,我们面临的是人类需要监督和控制比自己更强大的AI系统。AI系统产生的行为、错误和问题也会超出人类认知。所以,超人类AI系统的管理上必须具备一种能力,可以将人类给出的监督推广到更复杂的行为上。例如,人类可能只能审核1000行代码是否遵从了指令或者安全。但是,对于一个几百万行的代码系统,可能需要AI系统根据前面1000行代码的人类评估过程来推广,去自行评估这个几百万行代码的系统是否准确遵从了人类的意图且符合安全要求。
超级对齐
本次OpenAI做的超级对齐系统的目标非常简单。首先,我们说明一下当前AI系统如何完成地更好。
所以,OpenAI认为,超级对齐有三个基准。第一个是较弱的模型(比如未来的人类、较弱的AI系统),它有一个性能表现基准,还有一个强的AI模型的性能上限基准。超级对齐的目标就是通过弱模型微调(如生成好坏的评价),让强模型完成当前类似SFT和RLHF阶段,达到自己的上限。显然,实际上,由弱模型微调的强模型的性能其实可能并没有达到它上限水平,因此它与强模型上限的差距就是未来我们要缩小的目标。
l们这里篇幅原因不再细说,而是总结一下过程和结论(关于更详细的分析可以参考DataLearnerAI的原文:准备迎接超级人工智能系统,OpenAI宣布RLHF即将终结!超级对齐技术将接任RLHF,保证超级人工智能系统遵循人类的意志 | 数据学习者官方网站(Datalearner))。lu
总体的实验结论如下:
- 强大的预训练模型天然能够超越它们的弱监督者。如果我们使用弱模型生成的标签对强模型进行微调,强模型的表现会超出弱监督者。例如,在自然语言处理(NLP)任务上,如果我们用GPT-2级别模型的标签对GPT-4进行微调,可以让强模型恢复一半的性能水平。
- 仅依靠弱监督模型数据的微调是不够的。尽管有积极实验结果,但使用弱监督微调的强模型与使用真实监督微调的强模型之间仍然存在显著差距。弱到强泛化在ChatGPT奖励建模方面尤其不佳。综合来看,这个实验结果提供了实证证据,表明当前的RLHF可能无法很好地扩展到超人类模型,除非进行额外的工作。
- 改进弱到强的泛化是可行的。OpenAI发现,通过鼓励强模型使用辅助损失函数来进行自信预测、使用中间模型进行监督引导和通过无监督微调改进模型表示,可以提高性能。例如,当使用辅助信心损失函数对NLP任务中的GPT-4进行GPT-2级别模型的监督时,我们通常能够恢复弱模型和强模型之间近80%的性能差距。也就说,至少看到有方法可以实现这种泛化。
总结
这个论文最重要的不是OpenAI提出的方法和结论。而是2个信息,一个是OpenAI可能真的相信未来10年会出现超过人类的AI系统。另一个是OpenAI正在积极准备应对这种情况。而由弱到强的只是这方面的一个探索。同时,OpenAI也宣布投资1000万美元,在全球招募团队做这方面的研究,通过的团队可以获得10万-200万美元的资助,进行超级对齐的研究。
论文原文和更详细解释参考原文:准备迎接超级人工智能系统,OpenAI宣布RLHF即将终结!超级对齐技术将接任RLHF,保证超级人工智能系统遵循人类的意志 | 数据学习者官方网站(Datalearner)