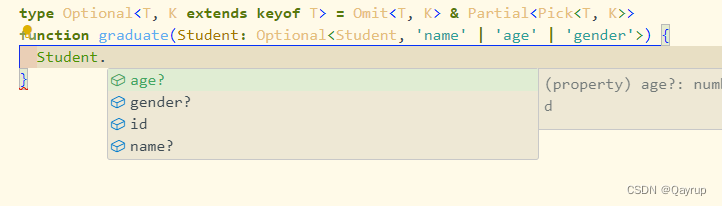
为什么需要分库分表
分库分表是因应数据库处理大规模数据时所面临的挑战而出现的解决方案.
// 提高性能
单个数据库在数据量增加时容易出现性能瓶颈。分库分表可以减轻单个数据库的负担,提高系统的读写性能和响应速度.
// 提高并发能力
大量用户同时访问数据库可能导致数据库的性能下降。通过分库分表,可以将用户请求分散到多个数据库或表上,提高并发处理能力.
// 降低单点故障风险
单个数据库出现故障可能导致整个系统不可用。分库分表可以将数据分布到多个节点上,降低单点故障对系统的影响。
// 优化数据存储和查询
针对特定的业务需求,通过分库分表可以优化数据存储结构,使得数据存储更合理、查询更高效。
// 扩展性
随着业务的增长,单个数据库可能无法满足高并发和大数据量的需求。分库分表可以水平扩展,将数据分散到多个节点上,增加系统的扩展性和容量。
// 节约成本
使用分库分表可以根据需求灵活扩展数据库,而无需立即投入大量成本购买高性能的硬件设备或数据库服务。
数据库瓶颈
不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。在业务Service来看就是,可用数据库连接少甚至无连接可用。接下来就可以想象了吧(并发量、吞吐量、崩溃).
// IO瓶颈
// 磁盘IO
磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度 -> 分库和垂直分表。
// 网络IO
网络IO瓶颈,请求的数据太多,网络带宽不够。-> 分库
// CPU瓶颈
// SQL问题
如SQL中包含join,group by,order by,非索引字段条件查询等,增加CPU运算的操作. -> SQL优化,在业务层计算,减轻数据库压力.
// 单表数据量太大
查询时扫描的行太多,SQL效率低,CPU率先出现瓶颈。-> 分库分表
分库分表
水平分库
// 原理
以某个字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中.
// 要求
1.每个库的结构都一样.
2.每个库的数据都不一样,没有交集.
3.所有库的并集是全量数据

水平分表
// 原理
以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中.
// 要求
1.每个表的结构都一样.
2.每个表的数据都不一样,没有交集.
3.所有表的并集是全量数据.

垂直分库
// 原理
以表为依据,按照业务归属不同,将不同的表拆分到不同的库中.
// 要求
1.每个库的结构都不一样.
2.每个库的数据也不一样,没有交.
3.所有库的并集是全量数据.

垂直分表
// 原理
以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中
// 要求
1.每个表的结构都不一样
2.每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据.
3.所有表的并集是全量数据

分库分表步骤
1.根据容量(当前容量和增长量)评估分库或分表个数 .
2.确定分库分表的key,尽量均匀.
3.确定分库分表的规则
4.迁移数据(一般双写)
总结
以上介绍了分库分表的一些理论知识,下一篇我会以水平分表为例,《Mybaits拦截器实现水平分表》来加深理解.
参考文章:
https://juejin.cn/post/6844903863464493064
https://www.cnblogs.com/qdhxhz/p/11608222.html



![壹[1],函数:ReadImage](https://img-blog.csdnimg.cn/direct/f2d632ecfd9d4990b4d6a66dca694ab1.png)