为什么要用POM设计模式
前期,我们学会了使用Python+Selenium编写Web UI自动化测试线性脚本
线性脚本(以快递100网站登录举栗):
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://sso.kuaidi100.com/sso/v2/authorize.do")
driver.maximize_window()
driver.find_element(By.ID, 'name').send_keys("***********")
driver.find_element(By.ID, 'password').send_keys("***********")
driver.find_element(By.ID, 'submit').click()
time.sleep(2)
text = driver.find_element(By.PARTIAL_LINK_TEXT, '首页').text
assert text == '首页'
driver.close()
使用以上代码,最基础最简单的Web UI 自动化测试就做起来了,但是,问题也随之而来,线性脚本的缺点也暴露出来了:
- Web UI自动化测试,简单来说,就是模拟人在浏览器上的操作,打开浏览器-定位元素-操作元素-模拟页面动作-断言结果
- 由于线性脚本中的
元素定位、元素操作细节、测试数据、结果验证(断言)是捆绑在一起的,代码会显得非常冗余、可读性差、不可复用、工作量大且可维护性差 - 刚开始,少数的测试用例维护起来可能很容易,但随着时间迁移、产品迭代、测试套件持续增长,脚本也越来越臃肿,可能需要维护几十个页面,且很多页面是公用的,元素的任何改变都会让我们的脚本变得繁琐复杂、耗时易出错。例如:十几个用例中都用到了A元素,某一天A元素被前端改成了B元素,我们就需要去十几个用到A元素的地方,将A元素修改为B元素
- 如果可以把公共元素抽取出来,即使元素被前端修改,我们也只需更新元素的定位方式,而不用修改每条测试用例,无论多少用例用到该元素,都只需修改元素定位方式,重新获取元素即可
- 所以我们引入了PageObject这种解决方案,它可以帮我们解决设计上的问题,可以将testcase和page分层,形成一个非常好的结果
什么是POM设计模式
-
POM:Page Object Model,
页面对象模型的简称 -
2013年,由Martin Fowler提出了PageObject的观点

-
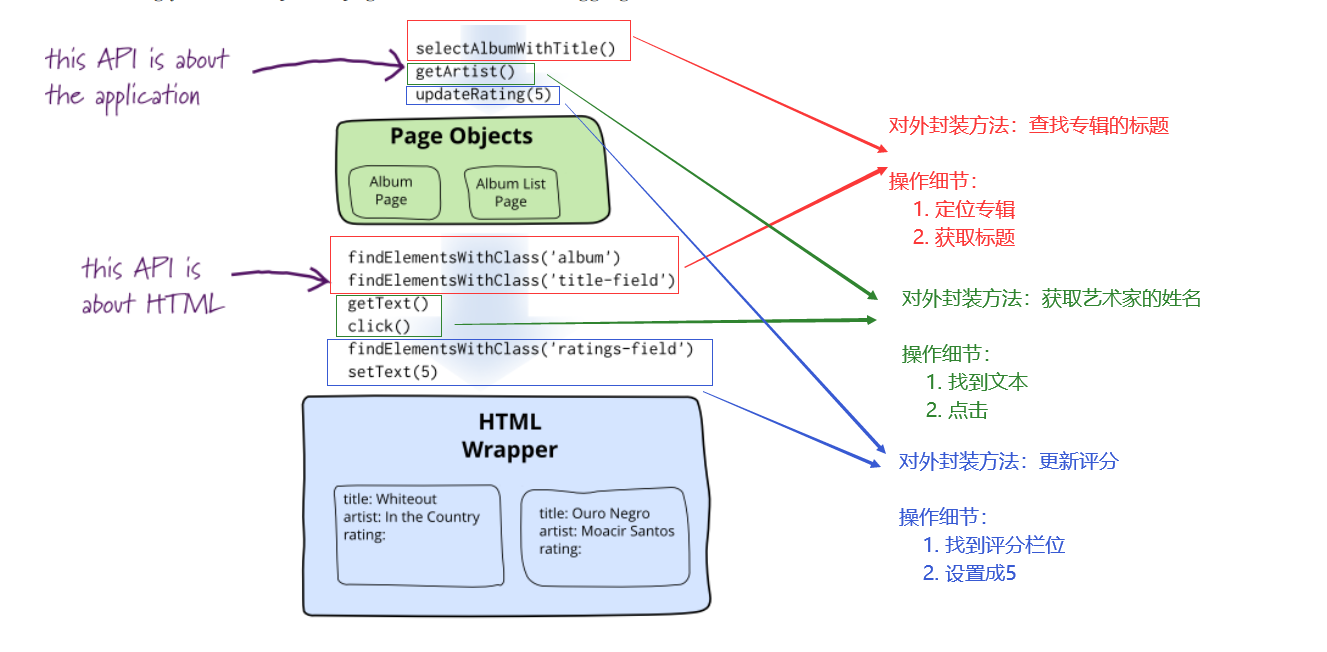
作者的观点是一种封装思想,旨在为每个待测页面创建一个页面对象,从而将繁琐的定位操作、操作细节封装到这个页面对象中,对外只提供必要的操作接口,在调用的时候只调用提供的接口,不用去调用操作细节,最终实现程序的高内聚低耦合,使程序模块的可重用性、移植性大大增强
-
在这种模式下,对于应用程序中的每个页面都应该有相应单独的页面类(例如:login_page、userinfo_page),类中应该包含此页面上的
元素对象和操作这些元素对象所需要的方法 -
再将流程所关联的页面作为对象,将对象串联起来形成不同的业务流程,例如:在登录页面完成登录操作后跳转到用户中心页面进行个人信息的修改
Selenium官方对PageObject的引入
历史
-
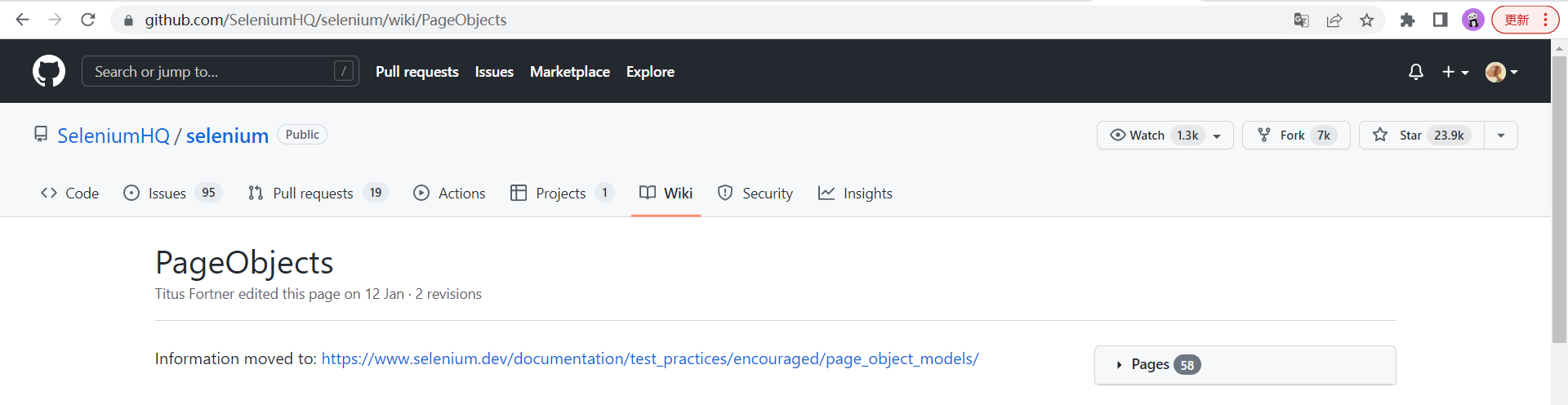
2015年,Selenium官方对PageObject进行引入:
PageObjects · SeleniumHQ/selenium Wiki · GitHub
-
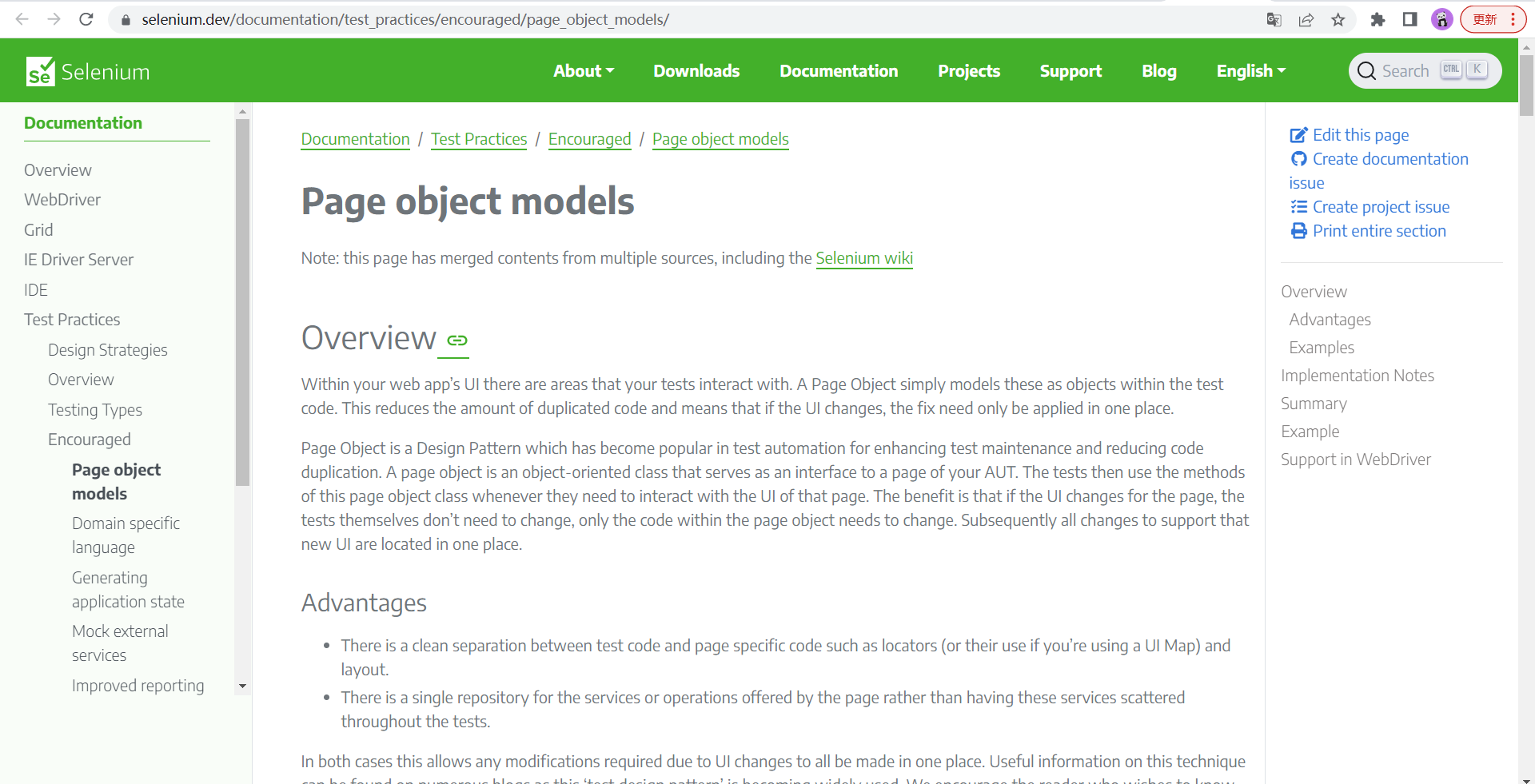
2020年,Selenium更新文档地址:
Page object models | Selenium
PageObject六大原则

-
The public methods represent the services that the page offers
用公共方法表示页面提供的服务
例如:登录页面,有用户名输入框、密码输入框、登录按钮,于是就可以用input_username()代表输入用户名、用input_password()代表输入密码、用click_submit()代表点击登录按钮
-
Try not to expose the internals of the page
尽量不要暴露页面的内部信息
将操作细节封装成方法,对外只提供对应的方法供调用
-
Generally don’t make assertions
一般不使用断言
断言要和Page代码分开,不要将断言写在PageObject层
-
Methods return other PageObjects
方法返回其他PageObjects
例如:首页有个方法是点击登录图标跳转到登录页面,因此这个方法应该返回login_page
-
Need not represent an entire page
不需要表示整个页面
不需要对页面中的每一个元素进行建模,只需要关注我们需要用到的元素。例如:登录页面除了账号密码登录,还有快捷登录、手机短信登录、扫码登录等
-
Different results for the same action are modelled as different methods
同一行为的不同结果可以用不同的方法来模拟
例如:对一个页面进行操作,可能出现正确的结果或者错误的结果,可以为这两种不同的结果分别创建两个不同的方法
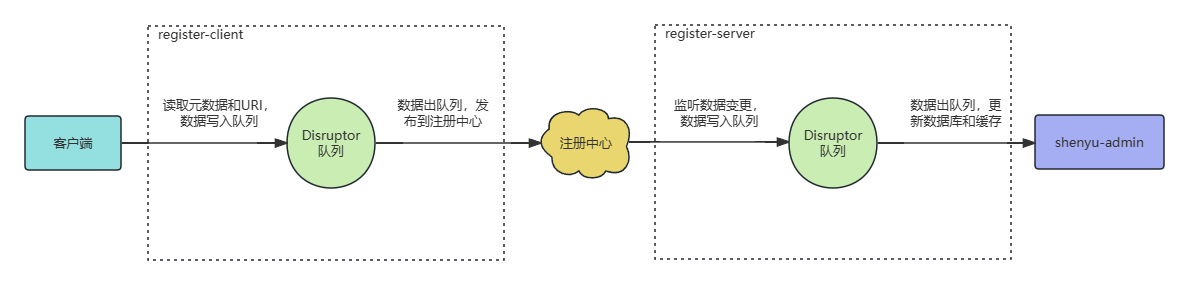
POM框架
GitHub开源代码
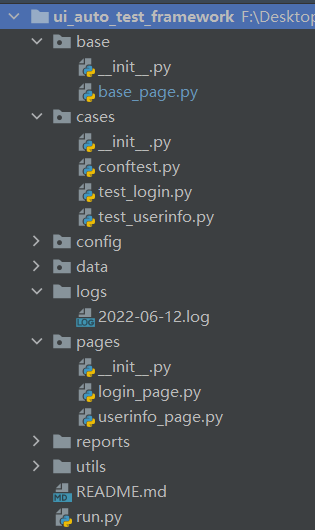
-
base:base_page,基类,定义项目所需的基础方法,对Selenium一些常用的api进行二次封装,如:find_element、click、send_keys、screenshot、调用JavaScript脚本的方法以及其他与浏览器相关的操作
为什么要有基类?
- 由于每个页面都会频繁使用这些方法,若单纯使用Selenium原始api,可能遇到一些问题,例如:某个按钮未加载完成,但已触发了点击事件,导致元素定位不到而报错。这时就可以对原始api进行二次封装,如:加入等待时间、对异常进行捕获并打印日志等,之后所有的PageObject都继承BasePage类,后续只需要调用这些封装好的方法,增强复用性
- 假设以后不使用Selenium这个框架,就只需要修改BasePage中的方法,不用去修改具体的测试用例业务代码
-
pages:page_object,页面对象层,也是PO的核心层,继承BasePage,管理页面元素以及操作元素的方法(将操作元素的动作写成方法)
-
cases:测试用例层,用于管理测试用例,这里会用到单元测试框架,如:Pytest、Unittest。
-
data:测试数据层,用于测试数据的管理,数据与脚本分离,降低维护成本,提高可移植性,如:yml 文件数据
-
config:配置文件层,存放整个项目需要用到的配置项,如:URL、数据库信息等
-
utils:CommonUtil,公共模块,将一些公共函数、方法以及通用操作进行封装,如:日志模块、yaml 操作模块、时间模块等
-
run.py:批量执行测试用例的主程序,根据不同需求不同场景进行组装,遵循框架的灵活性和扩展性
-
logs:日志模块,用于记录和管理日志,针对不同情况,设置不同的日志级别,方便定位问题
-
reports:测试报告层,用于测试报告的生成和管理,如:基于 Allure 生成的定制化报告
字节大牛十分钟讲清App自动化测试POM框架深度封装,全程高能