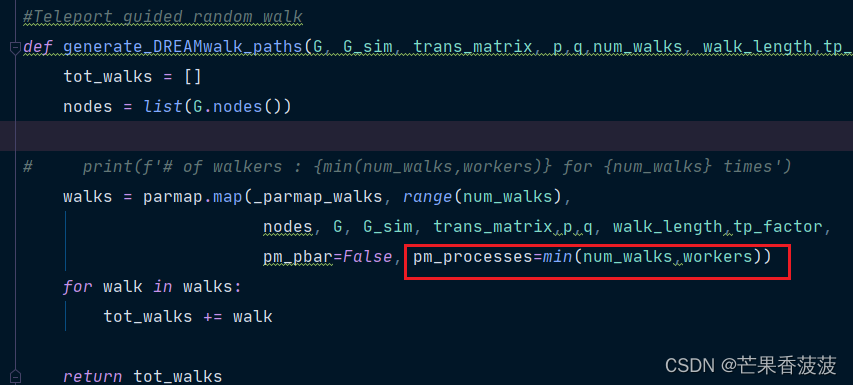
一、大边界的直观理解
1. 大间距分类器的背景
支持向量机的大间距分类器着眼于构建一个能够在正负样本之间划定最大间距的决策边界。为了理解这一点,首先观察支持向量机的代价函数,其中涉及到正负样本的代价函数cos𝑡1(𝑧)和cos𝑡0(𝑧)。
对于正样本(𝑦 = 1),我们希望𝜃^𝑇𝑥的值大于等于 1,而对于负样本(𝑦 = 0),希望𝜃^𝑇𝑥的值小于等于 -1。这要求决策边界不仅能够正确分离样本,还需要具备足够的“安全间距”。

2. 支持向量机的大间距特性
支持向量机不仅仅追求正确分类样本,更强调在分类过程中保持最大的间距。这一点通过引入一个常数𝐶来体现,当𝐶取非常大的值时,最小化代价函数将迫使𝜃^𝑇𝑥的值趋近于零,即实现最大间距分类器。
3. 优化问题与决策边界
通过解决一个相应的优化问题,可以得到支持向量机的决策边界。当𝐶非常大时,最优解将使得代价函数的第一项为零,从而得到一个大间距分类器。这种分类器在分离正负样本时更为鲁棒,因为它努力最大化正负样本之间的距离。
4. 正则化参数𝐶的影响
正则化参数𝐶的选择在支持向量机中至关重要。当𝐶较大时,相当于正则化参数𝜆较小,可能导致过拟合;而当𝐶较小时,相当于正则化参数𝜆较大,可能导致欠拟合。这表明𝐶的取值影响模型的偏差和方差,需要在训练中进行平衡。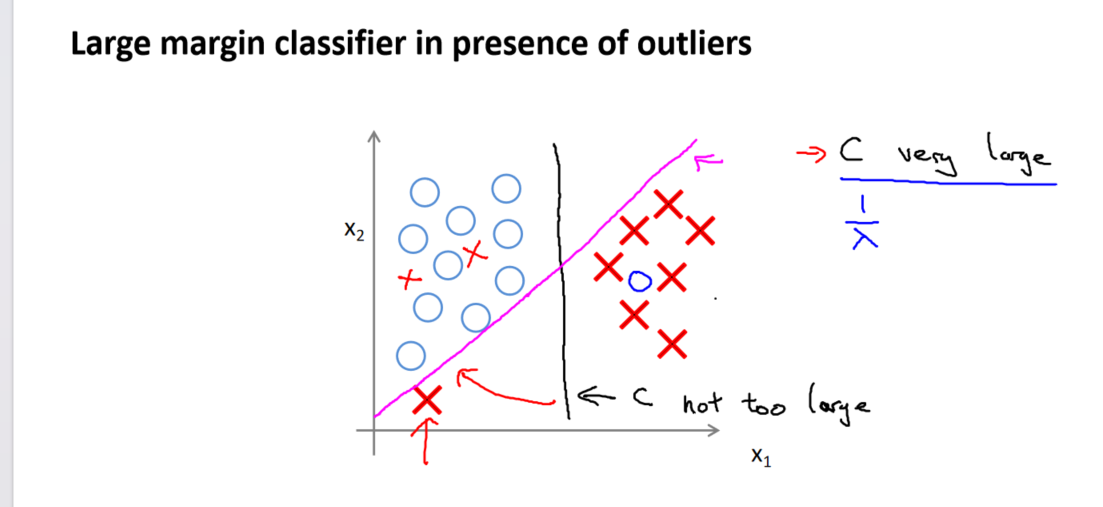
二、大边界分类背后的数学
-
向量内积: 假设有两个向量 𝑢 和 𝑣,它们的内积表示为 𝑢^𝑇𝑣。通过将向量投影到另一个向量上,可以计算投影的长度,即内积。
-
向量范数: 向量的范数表示其长度,通常使用欧几里得范数表示。对于二维向量 𝑢 = [𝑢1, 𝑢2],其范数为 ∥𝑢∥ = √(𝑢1^2 + 𝑢2^2)。
-
内积的计算: 内积 𝑢^𝑇𝑣 可以通过向量的点乘(𝑢1 × 𝑣1 + 𝑢2 × 𝑣2)或矩阵乘法 ([𝑢1 𝑢2] × [𝑣1, 𝑣2]) 计算。这两种方法得到的结果是相同的。
-
内积的性质: 内积具有交换性,即 𝑢^𝑇𝑣 = 𝑣^𝑇𝑢。此外,内积的结果是两个实数的乘积。
-
投影和内积的关系: 通过投影计算内积时,投影长度记为 𝑝,内积可以表示为 𝑢^𝑇𝑣 = 𝑝⬝∥𝑢∥。
-
符号和夹角: 投影的长度 𝑝 可能是正值或负值,取决于向量 𝑢 和 𝑣 之间的夹角。夹角大于 90 度时,投影为负值。
-
支持向量机目标函数: 支持向量机的目标函数是极小化参数向量 𝜃 的范数的平方,即最小化 1/2 ∥𝜃∥^2。
-
大间隔分类: 通过选择大间隔分类器,支持向量机追求最大化训练样本到决策边界的距离(间距),从而使参数向量的范数最小。
-
简化假设: 在推导中,作者简化了截距为零(𝜃0 = 0)和特征数为 2 的情况,使目标函数更容易分析。
-
决策边界选择: 选择大间隔分类器的决策边界可以使参数向量的范数最小,从而实现大间隔分类。
参考资料:
[中英字幕]吴恩达机器学习系列课程
黄海广博士 - 吴恩达机器学习个人笔记






![[Kubernetes]2. k8s集群中部署基于nodejs golang的项目以及Pod、Deployment详解](https://img-blog.csdnimg.cn/direct/cbbb0d5fdb324f3cb506557929e84537.png)