目录
一、内部数据结构
二、简单动态字符串
1、sds的用途
实现字符串对象
将sds代替C默认的char*类型
2、Redis中的字符串
sds的实现
3、优化追加操作
4、sds 模块的 API
三、Redis动态字符串的内存分配和释放是如何进行的?
四、Redis动态字符串的扩容策略是什么?
五、Redis动态字符串在存储数据时有什么注意事项?
六、Redis动态字符串与常规字符串的区别是什么?
七、小结
一、内部数据结构
Redis和其他很多 key-value 数据库的不同之处在于, Redis不仅支持简单的字符串键值对,它还提供了一系列数据结构类型值,比如列表、哈希、集合和有序集,并在这些数据结构类型上定义了一套强大的 API。
通过对不同类型的值进行操作, Redis可以很轻易地完成其他只支持字符串键值对的 key-value数据库很难(或者无法)完成的任务。
在 Redis的内部,数据结构类型值由高效的数据结构和算法进行支持,并且在 Redis自身的构建当中,也大量用到了这些数据结构。
这一部分将对 Redis内存所使用的数据结构和算法进行介绍。
二、简单动态字符串
Sds(Simple Dynamic String ,简单动态字符串)是 Redis底层所使用的字符串表示,它被用在几乎所有的 Redis模块中。
本章将对 sds的实现、性能和功能等方面进行介绍,并说明 Redis使用 sds而不是传统 C字符串的原因。
1、sds的用途
Sds在 Redis中的主要作用有以下两个:
1.实现字符串对象( StringObject ) ;
2.在 Redis程序内部用作 char*类型的替代品;
以下两个小节分别对这两种用途进行介绍。
实现字符串对象
Redis是一个键值对数据库( key-value DB ) ,数据库的值可以是字符串、集合、列表等多种类型的对象,而数据库的键则总是字符串对象。
对于那些包含字符串值的字符串对象来说,每个字符串对象都包含一个 sds值。
Note:“包含字符串值的字符串对象”,这种说法初听上去可能会有点奇怪,但是在 Redis中,一个字符串对象除了可以保存字符串值之外,还可以保存 long类型的值,所以为了严谨起见,这里需要强调一下:当字符串对象保存的是字符串时,它包含的才是 sds值,否则的话,它就是一个long类型的值。
举个例子,以下命令创建了一个新的数据库键值对,这个键值对的键和值都是字符串对象,它们都包含一个 sds值:
redis>SET book "Mastering C++ in 21 days "
OK
redis>GET book
"Mastering C++ in 21 days "以下命令创建了另一个键值对,它的键是字符串对象,而值则是一个集合对象:
redis>SADD nosql "Redis""MongoDB""Neo4j"
(integer) 3
redis>SMEMBERS nosql
1)"Neo4j"
2)"Redis"
3)"MongoDB"将sds代替C默认的char*类型
因为char*类型的功能单一,抽象层次低,并且不能高效地支持一些 Redis常用的操作(比如追加操作和长度计算操作) ,所以在 Redis程序内部,绝大部分情况下都会使用 sds而不是char*来表示字符串。
性能问题在稍后介绍 sds定义的时候就会说到,因为我们还没有了解过 Redis的其他功能模块,所以也没办法详细地举例说那里用到了 sds,不过在后面的章节中,我们会经常看到其他模块(几乎每一个)都用到了 sds类型值。
目前来说,只要记住这样一个事实即可:在 Redis中,客户端传入服务器的协议内容、 aof缓存、返回给客户端的回复,等等,这些重要的内容都是由都是由 sds类型来保存的。
2、Redis中的字符串
在 C语言中,字符串可以用一个 \0结尾的char数组来表示。
比如说, hello world 在 C语言中就可以表示为 "hello world\0" 。这种简单的字符串表示在大多数情况下都能满足要求,但是,它并不能高效地支持长度计算和追加( append)这两种操作:
•每次计算字符串长度( strlen(s) )的复杂度为 (N)。
•对字符串进行 N次追加,必定需要对字符串进行 N次内存重分配( realloc) 。
在 Redis内部,字符串的追加和长度计算并不少见,而 APPEND 和 STRLEN 更是这两种操作在 Redis命令中的直接映射,这两个简单的操作不应该成为性能的瓶颈。
另外, Redis除了处理 C字符串之外,还需要处理单纯的字节数组,以及服务器协议等内容,所以为了方便起见, Redis的字符串表示还应该是 二进制安全的 :程序不应对字符串里面保存的数据做任何假设,数据可以是以 \0结尾的 C字符串,也可以是单纯的字节数组,或者其他格式的数据。
考虑到这两个原因, Redis使用 sds类型替换了 C语言的默认字符串表示: sds既可以高效地实现追加和长度计算,并且它还是二进制安全的。
sds的实现
在前面的内容中,我们一直将 sds作为一种抽象数据结构来说明,实际上,它的实现由以下两部分组成:
typedef char*sds;
structsdshdr {
// buf已占用长度
intlen;
// buf剩余可用长度
intfree;
//实际保存字符串数据的地方
charbuf[];
};其中,类型 sds是char *的别名 (alias),而结构 sdshdr则保存了 len、free和buf三个属性。
作为例子,以下是新创建的,同样保存 hello world 字符串的 sdshdr结构:
structsdshdr {
len=11;
free=0;
buf="hello world \0";// buf的实际长度为 len + 1
};通过len属性,sdshdr可以实现复杂度为 (1)的长度计算操作。
另一方面,通过对 buf分配一些额外的空间,并使用 free记录未使用空间的大小, sdshdr可以让执行追加操作所需的内存重分配次数大大减少,下一节我们就会来详细讨论这一点。
当然, sds也对操作的正确实现提出了要求——所有处理 sdshdr的函数,都必须正确地更新len和free属性,否则就会造成 bug。
3、优化追加操作
在前面说到过,利用 sdshdr结构,除了可以用 (1)复杂度获取字符串的长度之外,还可以减少追加 (append) 操作所需的内存重分配次数,以下就来详细解释这个优化的原理。
为了易于理解,我们用一个 Redis执行实例作为例子,解释一下,当执行以下代码时, Redis内部发生了什么:
redis>SET msg "hello world "
OK
redis>APPEND msg "again!"
(integer) 18
redis>GET msg
"hello world again! "首先,SET命令创建并保存 hello world 到一个sdshdr中,这个 sdshdr的值如下:
structsdshdr {
len=11;
free=0;
}当执行 APPEND 命令时,相应的 sdshdr被更新,字符串 " again!" 会被追加到原来的"hello world" 之后:
struct sdshdr {
len = 18;
free = 18;
// 空白的地方为预分配空间,共 18 + 18 + 1 个字节
buf = "hello world again!\0 ";
}注意,当调用 SET 命令创建 sdshdr 时,sdshdr 的 free 属性为 0 ,Redis 也没有为 buf 创建 额外的空间——而在执行 APPEND 之后,Redis 为 buf 创建了多于所需空间一倍的大小。
在这个例子中,保存 "hello world again!" 共需要 18 + 1 个字节,但程序却为我们分配了 18 + 18 + 1 = 37 个字节——这样一来,如果将来再次对同一个 sdshdr 进行追加操作,只要 追加内容的长度不超过 free 属性的值,那么就不需要对 buf 进行内存重分配。
比如说,执行以下命令并不会引起 buf 的内存重分配,因为新追加的字符串长度小于 18 :
redis> APPEND msg " again!"
(integer) 25再次执行 APPEND 命令之后,msg 的值所对应的 sdshdr 结构可以表示如下:
struct sdshdr {
len = 25;
free = 11;
// 空白的地方为预分配空间,共 18 + 18 + 1 个字节
buf = "hello world again! again!\0 ";
}sds.c/sdsMakeRoomFor 函数描述了 sdshdr 的这种内存预分配优化策略,以下是这个函数的 伪代码版本:
def sdsMakeRoomFor(sdshdr, required_len):
# 预分配空间足够,无须再进行空间分配
if (sdshdr.free >= required_len):
return sdshdr
# 计算新字符串的总长度
newlen = sdshdr.len + required_len
# 如果新字符串的总长度小于 SDS_MAX_PREALLOC
# 那么为字符串分配 2 倍于所需长度的空间
# 否则就分配所需长度加上 SDS_MAX_PREALLOC 数量的空间
if newlen < SDS_MAX_PREALLOC:
newlen *= 2
else:
newlen += SDS_MAX_PREALLOC
# 分配内存
newsh = zrelloc(sdshdr, sizeof(struct sdshdr)+newlen+1)
# 更新 free 属性
newsh.free = newlen - sdshdr.len
# 返回
return newsh在目前版本的 Redis 中,SDS_MAX_PREALLOC 的值为 1024 * 1024 ,也就是说,当大小小于 1MB 的字符串执行追加操作时,sdsMakeRoomFor 就为它们分配多于所需大小一倍的空间;当 字符串的大小大于 1MB ,那么 sdsMakeRoomFor 就为它们额外多分配 1MB 的空间。
Note: 这种分配策略会浪费内存吗?
执行过 APPEND 命令的字符串会带有额外的预分配空间,这些预分配空间不会被释放,除非 该字符串所对应的键被删除,或者等到关闭 Redis 之后,再次启动时重新载入的字符串对象将 不会有预分配空间。
因为执行 APPEND 命令的字符串键数量通常并不多,占用内存的体积通常也不大,所以这一 般并不算什么问题。
另一方面,如果执行 APPEND 操作的键很多,而字符串的体积又很大的话,那可能就需要修 改 Redis 服务器,让它定时释放一些字符串键的预分配空间,从而更有效地使用内存。
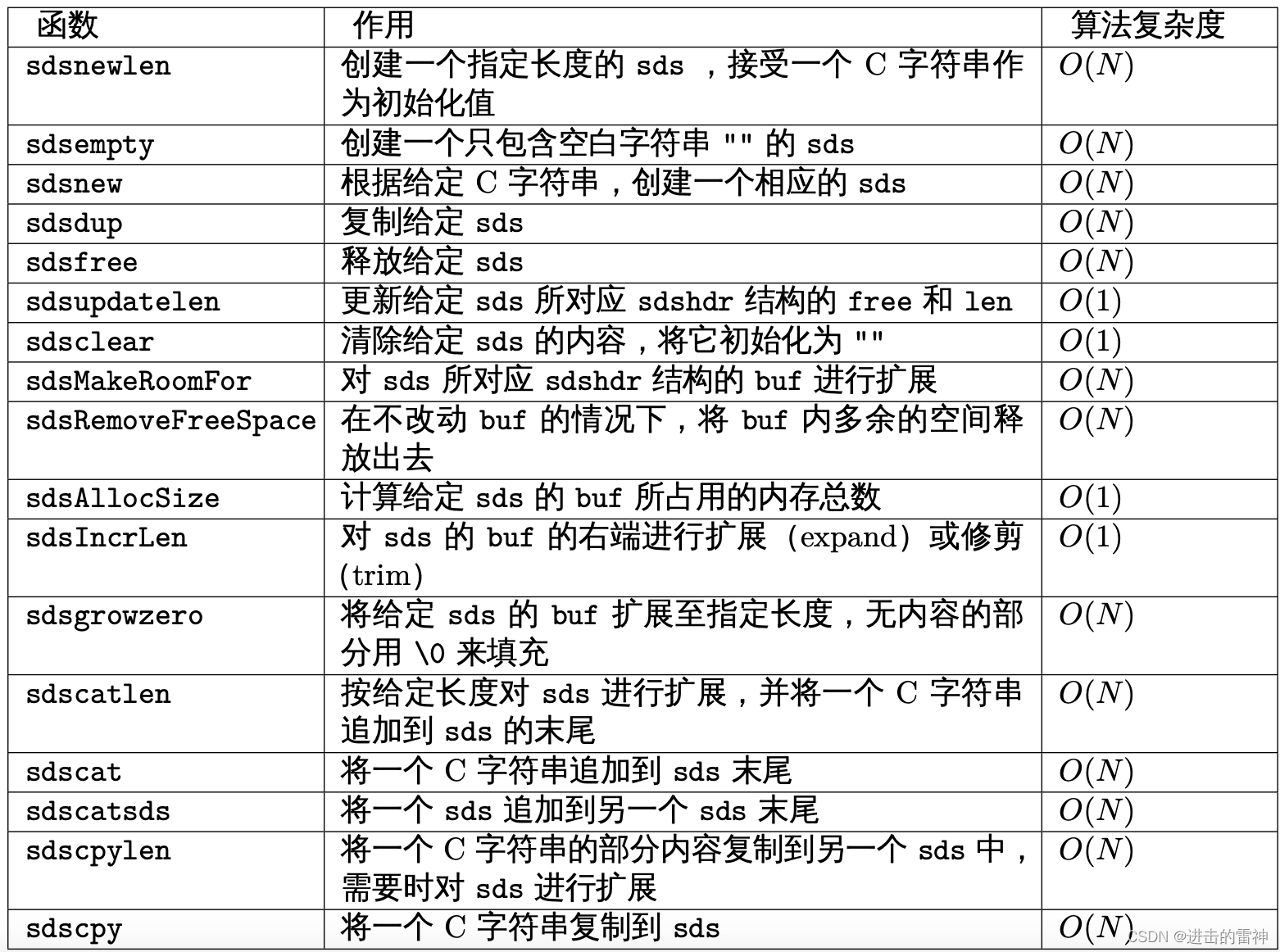
4、sds 模块的 API
sds 模块基于 sds 类型和 sdshdr 结构提供了以下 API :
三、Redis动态字符串的内存分配和释放是如何进行的?
Redis中的动态字符串类型redisObject内部实现了引用计数和惰性释放机制来管理内存分配和释放。
-
内存分配:Redis使用
malloc函数分配内存块来存储动态字符串。动态字符串结构体包含了当前字符串长度、可用空间大小和字符数组,其中字符数组的长度至少是当前字符串长度加一。 -
引用计数:每个
redisObject对象都包含一个refcount字段,记录了指向该对象的指针数量。当其他对象引用一个动态字符串时,它们会增加该动态字符串的引用计数。 -
惰性释放:当一个动态字符串不再被引用时,其引用计数会减少。如果引用计数变为0,Redis会将其标记为可释放状态,并不立即释放其内存。而是在合适的时机,例如内存紧张或者执行一次RDB或AOF持久化操作时,Redis会对所有可释放的动态字符串进行释放。
通过引用计数和惰性释放的组合,Redis可以减少内存分配和释放的次数,提高性能。同时,惰性释放机制也能够在需要释放内存时,一次性释放多个动态字符串,减少系统调用的开销。
四、Redis动态字符串的扩容策略是什么?
Redis动态字符串的扩容策略是通过预分配的方式来保证字符串的扩容操作效率。具体策略如下:
-
增长策略:当字符串长度增长时,Redis会根据当前字符串长度选择适当的增长策略。
- 如果当前字符串长度小于1MB,每次增长会以当前长度的2倍来进行。
- 如果当前字符串长度大于等于1MB,每次增长会增加1MB的长度。
-
预分配策略:Redis会预分配更大的空间,在每次扩容时,会为字符串分配比当前长度更大的空间。这样可以减少频繁地进行内存重新分配的次数,提高性能。
-
惰性空间释放策略:当字符串长度缩小时,Redis并不会立即释放多余的空间,而是将其保留起来。这样可以避免频繁地进行内存分配和释放操作,提高性能。
需要注意的是,Redis动态字符串是通过结构体sds(Simple Dynamic Strings)来实现的,结构体中记录了字符串的长度和剩余空间等信息。扩容策略可以保证字符串长度的增长和缩小的效率,同时避免了频繁进行内存分配和释放的操作。
五、Redis动态字符串在存储数据时有什么注意事项?
在存储数据时,使用Redis的动态字符串需要注意以下事项:
-
动态字符串可以存储任意的二进制数据,但需要注意数据的大小限制。Redis的最大字符串长度是512MB,如果要存储较大的数据,需要进行分片或者压缩等处理。
-
动态字符串是可修改的,但是在修改字符串时需要注意原来字符串的引用计数。如果有其他地方引用了该字符串,修改时需要先拷贝一份副本,再进行修改。
-
当动态字符串的长度超过预分配的空间时,需要进行重新分配和拷贝。这个过程可能会引发内存分配和拷贝的开销,因此在使用动态字符串时需要合理预估字符串的最大长度。
-
如果需要频繁地对字符串进行拼接、截取等操作,使用动态字符串性能更高。因为动态字符串的底层实现是一个char数组,可以直接通过索引访问和修改。
总而言之,使用动态字符串在存储数据时需要注意数据大小限制、引用计数、内存分配等问题,以及合理预估字符串的最大长度。
六、Redis动态字符串与常规字符串的区别是什么?
Redis的动态字符串与常规字符串有以下区别:
-
内存预分配:Redis的动态字符串会根据字符串的长度进行内存预分配,以减少字符串长度改变时的内存重新分配的次数。而常规字符串则需要每次长度改变都进行内存重新分配。
-
缓冲区溢出:Redis的动态字符串会维护一个字节缓冲区,用于保存字符串的内容。当字符串的长度超过缓冲区的大小时,会自动扩展缓冲区的大小,避免缓冲区溢出。而常规字符串没有这样的缓冲区,当字符串的长度超过字符串本身分配的空间时,会导致缓冲区溢出。
-
修改操作效率:Redis的动态字符串通过修改字符串结构体的方式进行字符串操作,可以在O(1)的时间内进行字符串长度的修改,并且不需要进行内存拷贝。而常规字符串需要在O(N)的时间内进行字符串长度的修改,并且需要进行内存拷贝。
-
字符串共享:Redis的动态字符串支持字符串共享,即多个键值对可以共享相同的字符串内容,节约内存。而常规字符串不支持字符串共享,每个字符串在内存中都有一份独立的拷贝。
总的来说,Redis的动态字符串相比常规字符串在内存管理、性能和内存占用等方面有一定的优势。
七、小结
• Redis 的字符串表示为 sds ,而不是 C 字符串(以 \0 结尾的 char*)。
• 对比 C 字符串,sds 有以下特性:
– 可以高效地执行长度计算(strlen);
– 可以高效地执行追加操作(append);
– 二进制安全;
• sds 会为追加操作进行优化:加快追加操作的速度,并降低内存分配的次数,代价是多占 用了一些内存,而且这些内存不会被主动释放。














![[PyTorch][chapter 7][李宏毅深度学习][深度学习简介]](https://img-blog.csdnimg.cn/direct/c0875fbe03c24aa9a04841bf6a25371a.png)