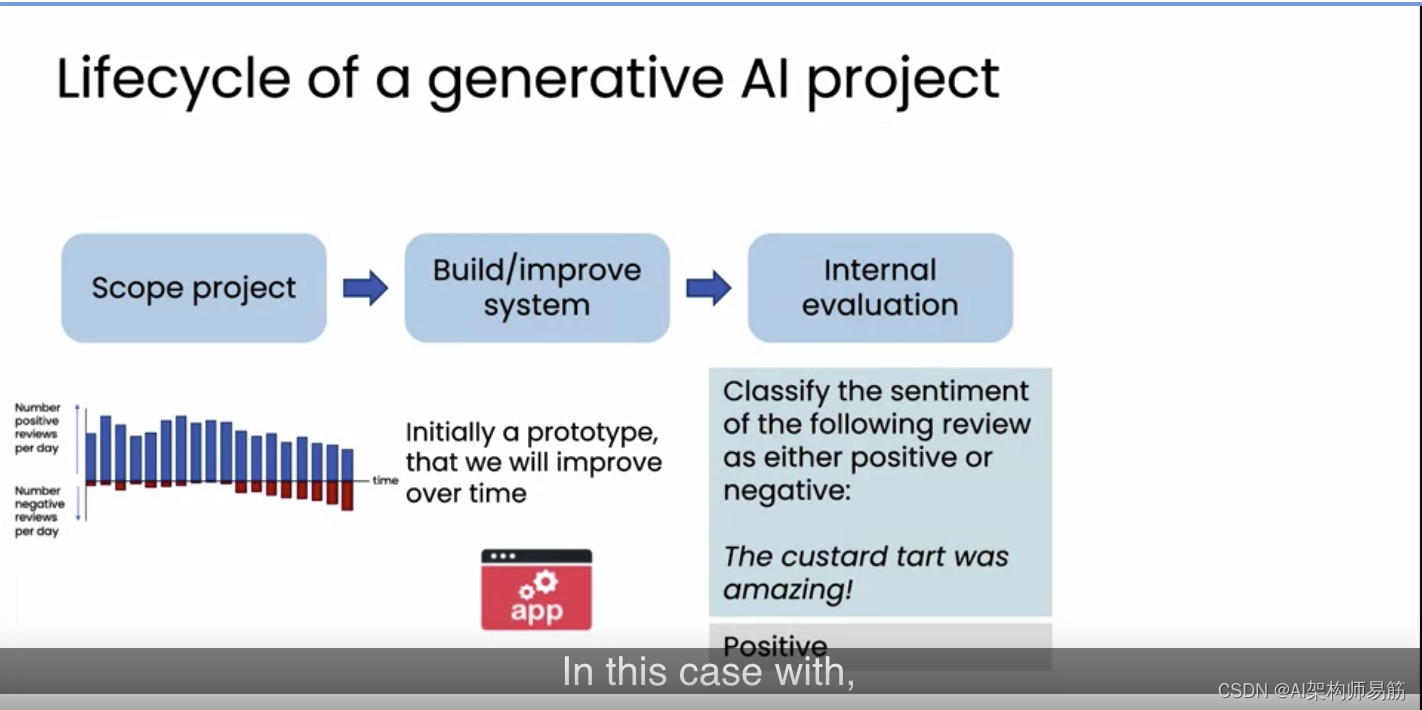
我将分享一下构建生成式AI软件应用程序的过程。首先,我们会确定项目范围,决定软件要实现的功能。例如,你可能决定建立一个餐厅声誉监控系统。接下来是实际的实施阶段。由于生成式AI使构建应用程序变得容易,你通常可以很快构建出一个原型,然后计划逐步改进它。一些我曾参与的应用程序,我们会在一两天内构建出初始原型,虽然最初并不完善。但快速构建原型使我们能够进行内部评估,测试系统对不同餐厅评论的反应准确性。
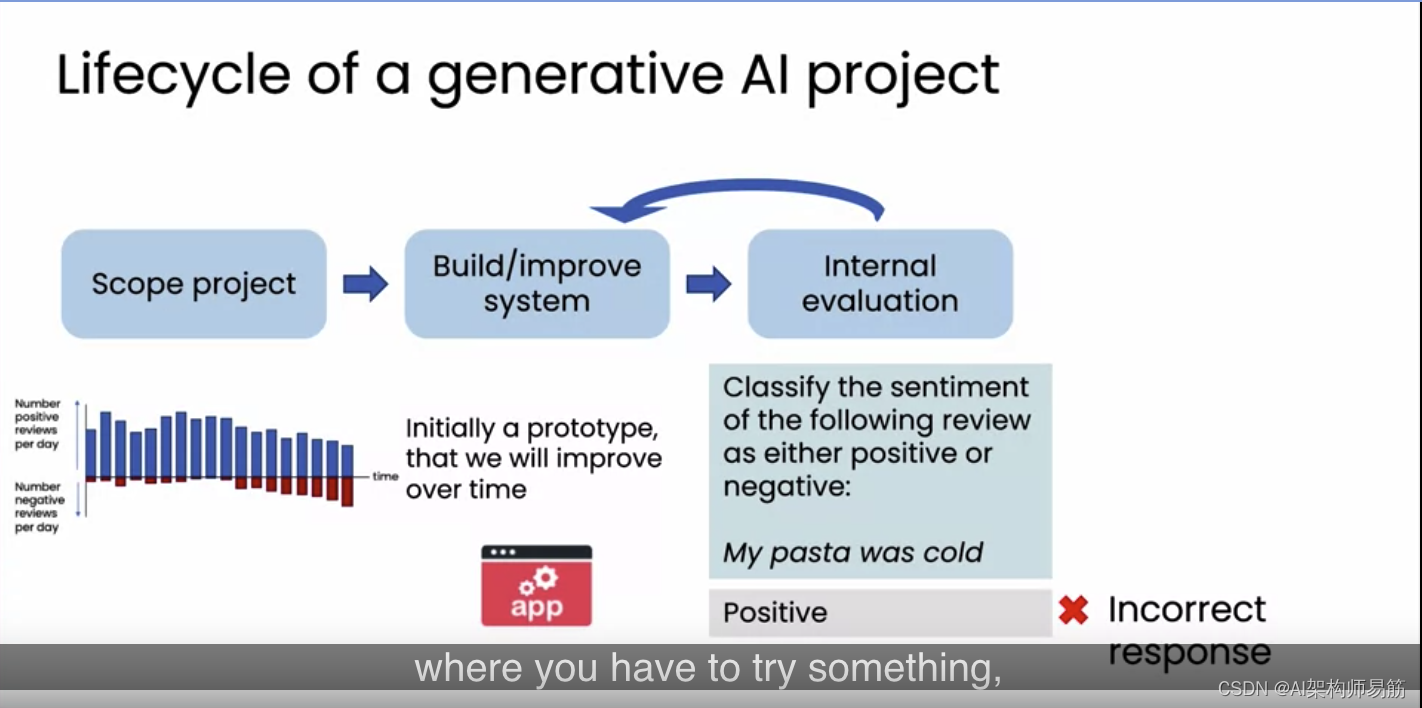
有时内部评估会发现一些问题,例如,“我的意大利面是冷的”,系统可能会将其判定为积极情绪,尽管这听起来像是负面评价。根据内部发现的问题,我们会继续改进系统。正如上周所讨论,撰写提示是一个高度迭代的过程,你需要尝试,看看效果,然后改进。
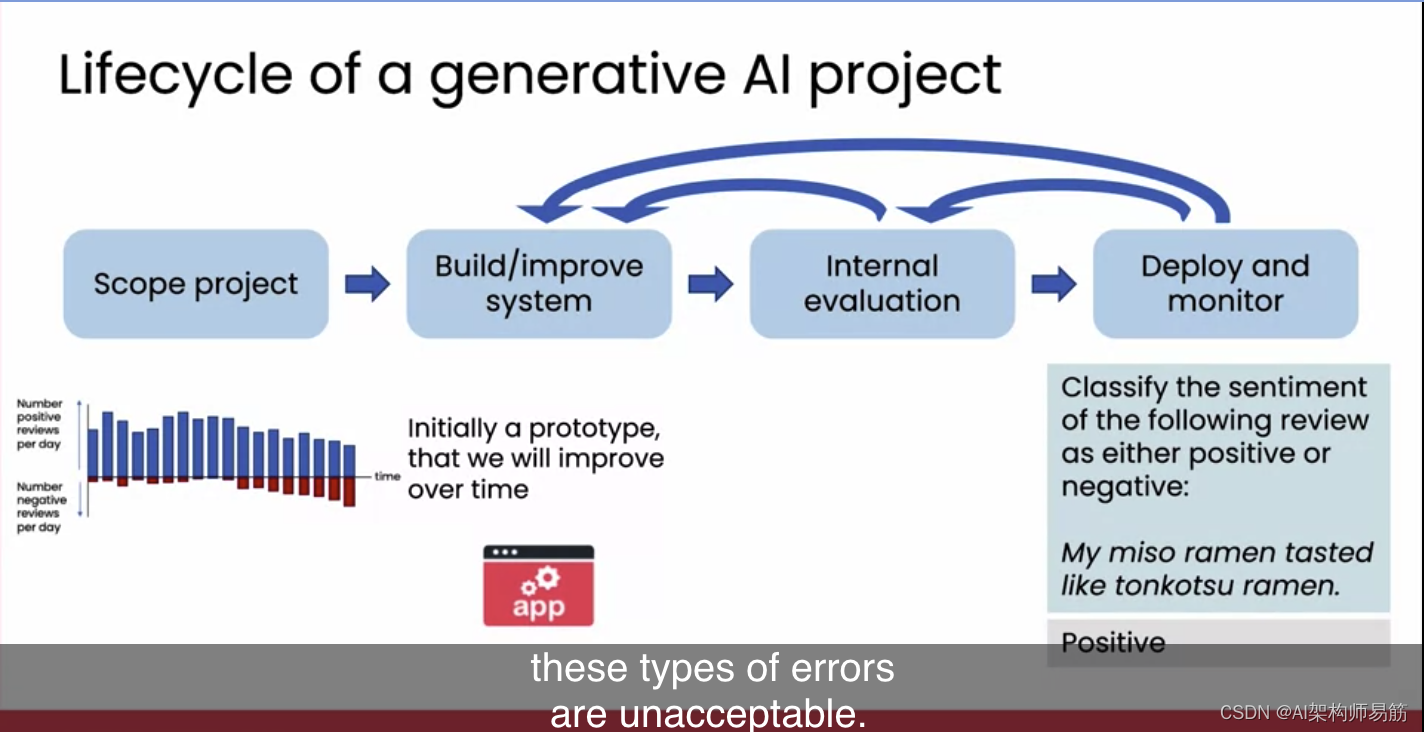
在充分的内部评估后,我们会将其部署到外部,并继续监控其表现。部署后,外部用户也可能提供导致系统出错的输入。例如,如果用户写道,“我的味噌拉面尝起来像豚骨拉面”,这是好是坏?如果你不熟悉拉面或日本料理,你可能不知道这是好事还是坏事。如果系统将其评为积极情绪,但事实上,如果你在菜单上点了味噌拉面,你可能不希望它尝起来像豚骨拉面,后者更像猪肉基汤底。当你发现这种错误响应时,你可能会决定重新进行内部评估,例如,系统是否在特定类型的美食上表现不佳,或者你可能会决定利用这些经验进一步改进提示或系统,假设你认为这类错误是不可接受的。

事实证明,构建生成式AI软件是一个高度经验性和实验性的过程。我们已经看到,撰写提示本身就是一个高度经验性的过程,你会有一个想法,尝试提示,看看元素的响应,然后可能更新你的想法和提示,然后再次尝试。

除了更新提示之外,本周我们还将讨论其他一些工具,用于提高生成式AI系统的性能。我们稍后会讨论的一个工具是RAG或检索增强生成,它允许大型语言模型访问外部数据源。我们还将讨论微调技术,它允许你将大型语言模型适应你的任务。最后是预训练模型,指的是从头开始训练大型语言模型。如果你不知道这些术语的含义,请不要担心,我们将在本周后面的内容中详细介绍它们。但除了提示之外,这些都是提高生成式AI系统性能的关键技术。
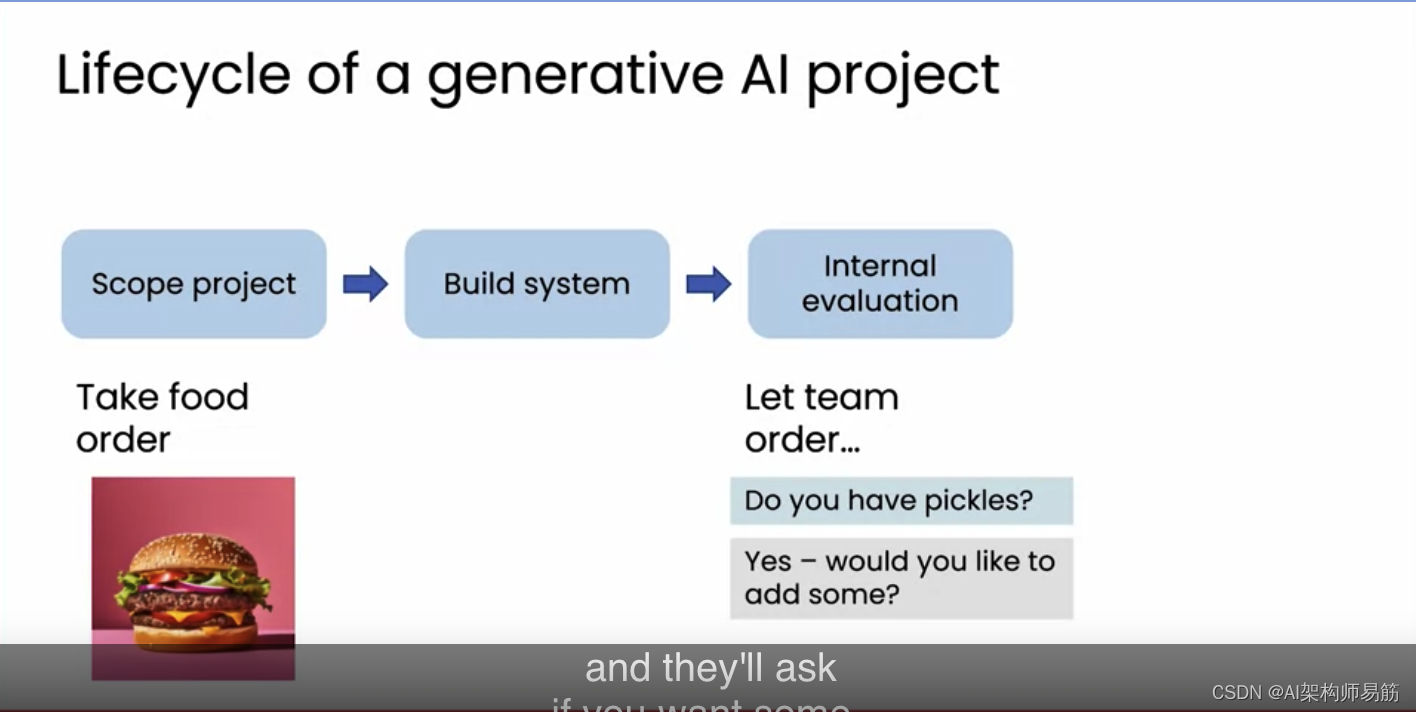
再举一个生成式AI项目生命周期的例子,让我们看看构建接受食品订单的系统会是什么样子。假设你决定构建一个用于接受订单的食品客服聊天机器人。你会开始构建系统,并快速组合出一个接受食品订单的聊天机器人。然后,因为我们不知道系统在内部的表现如何,你可能会让你的团队试用它,下不同的订单,看它的表现如何。有时它会生成好的回应,比如询问芝士汉堡上是否有泡菜。
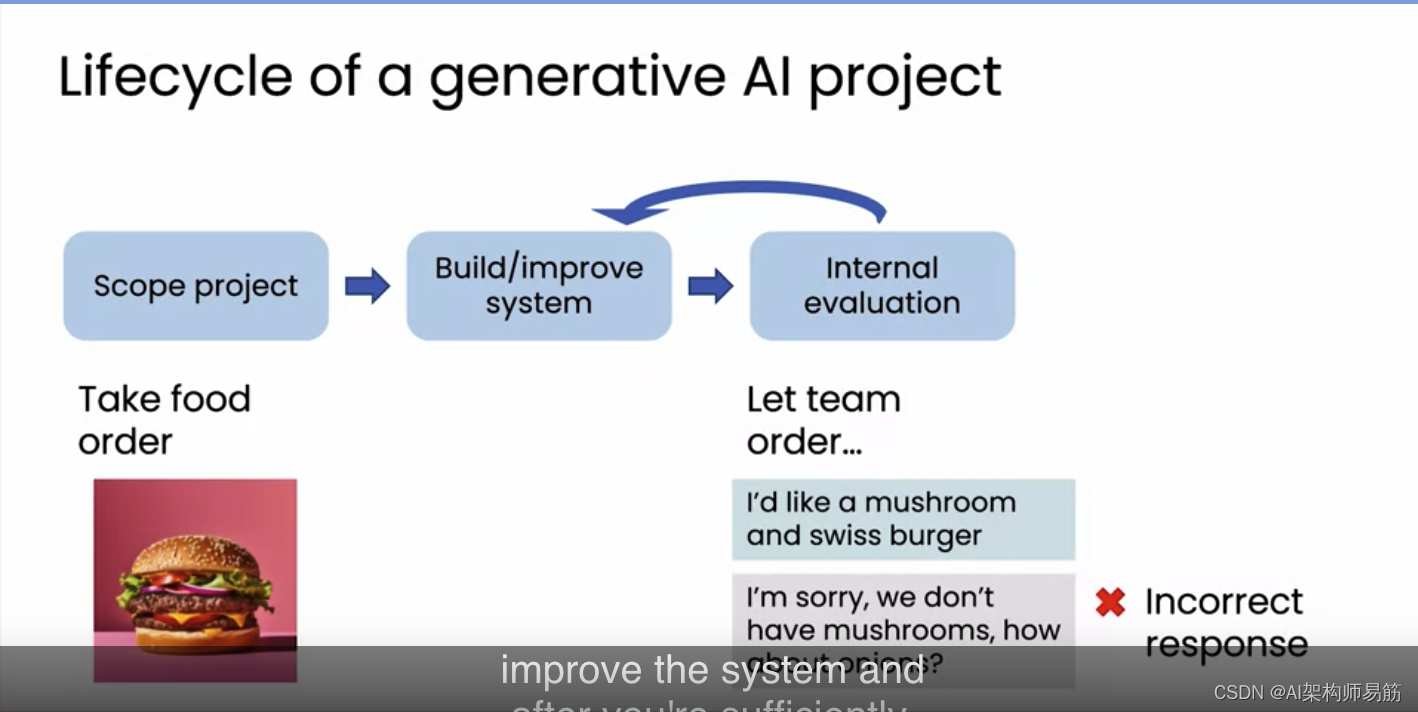
而有时它可能会给出意料之外的差劲回应,比如你的汉堡中确实有蘑菇,但出于某种原因,聊天机器人说“很抱歉,我们没有蘑菇”。和餐厅声誉监控系统类似,通过发现这些错误来帮助改进系统。
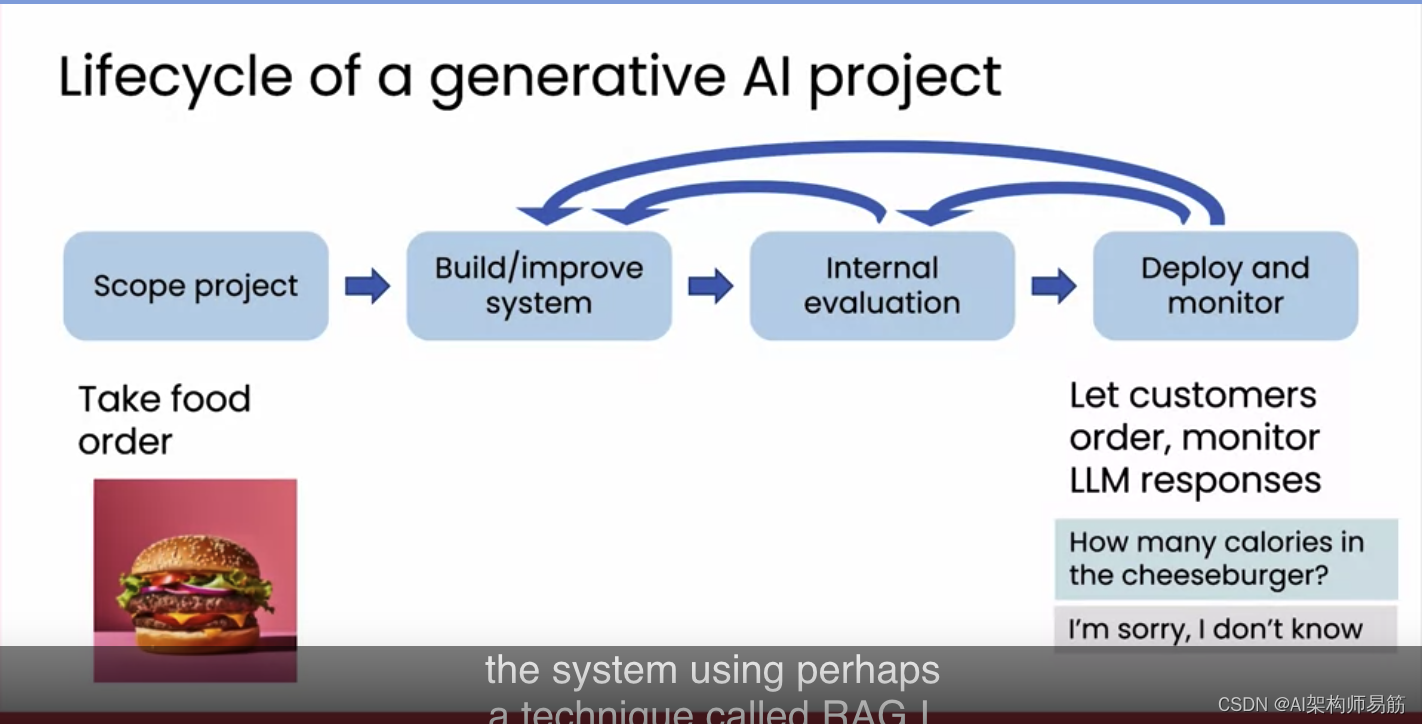
当你足够有信心认为它可以安全地对外部署时,你就可以部署它,让顾客下真正的订单,并监控大型语言模型的响应,以确保如果它仍然说出它不应该说的话,你可以继续改进它的表现。构建多个生成式AI项目后,我经常对用户会尝试用你的系统做出的奇特而美妙的事情感到惊讶和高兴。例如,如果用户问,“你们汉堡里有多少卡路里?”一开始,系统可能不知道。
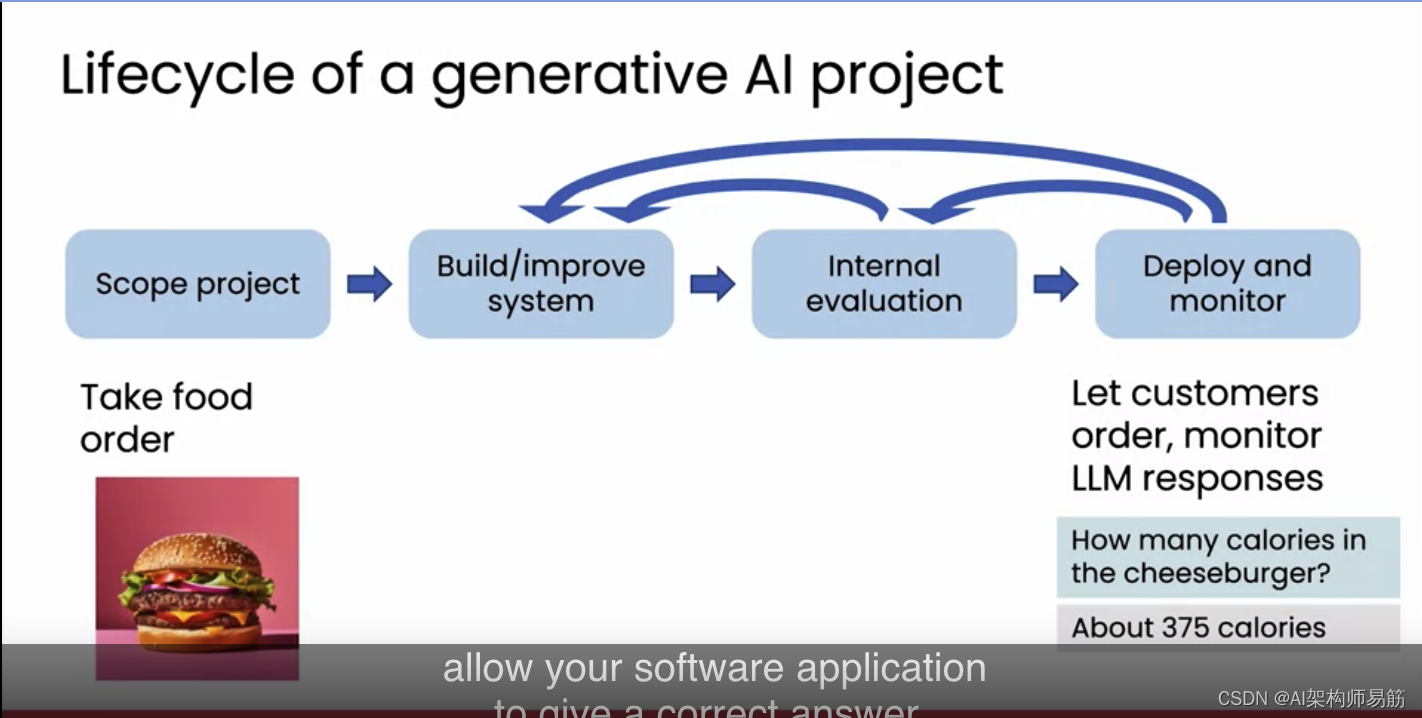
但如果你发现这一点,你可以使用我刚才提到的RAG技术更新系统,本周晚些时候我们将深入介绍这项技术,以使你的软件应用能够给出正确的答案。这就是构建生成式AI软件应用的感觉。如果你在一家有少数或许多软件开发人员的公司工作,并且如果你想出了一个你的公司可以构建的生成式AI应用的酷炫想法,这可能会给你一种感觉,即将它建成可能是什么样的过程。现在,我有时听到的一个担忧是,使用这些托管在互联网上的公司的大型语言模型真的很昂贵吗?事实证明,使用这些大型语言模型的成本可能比许多人想象的要便宜。
参考
https://www.coursera.org/learn/generative-ai-for-everyone/lecture/t2aQM/lifecycle-of-a-generative-ai-project