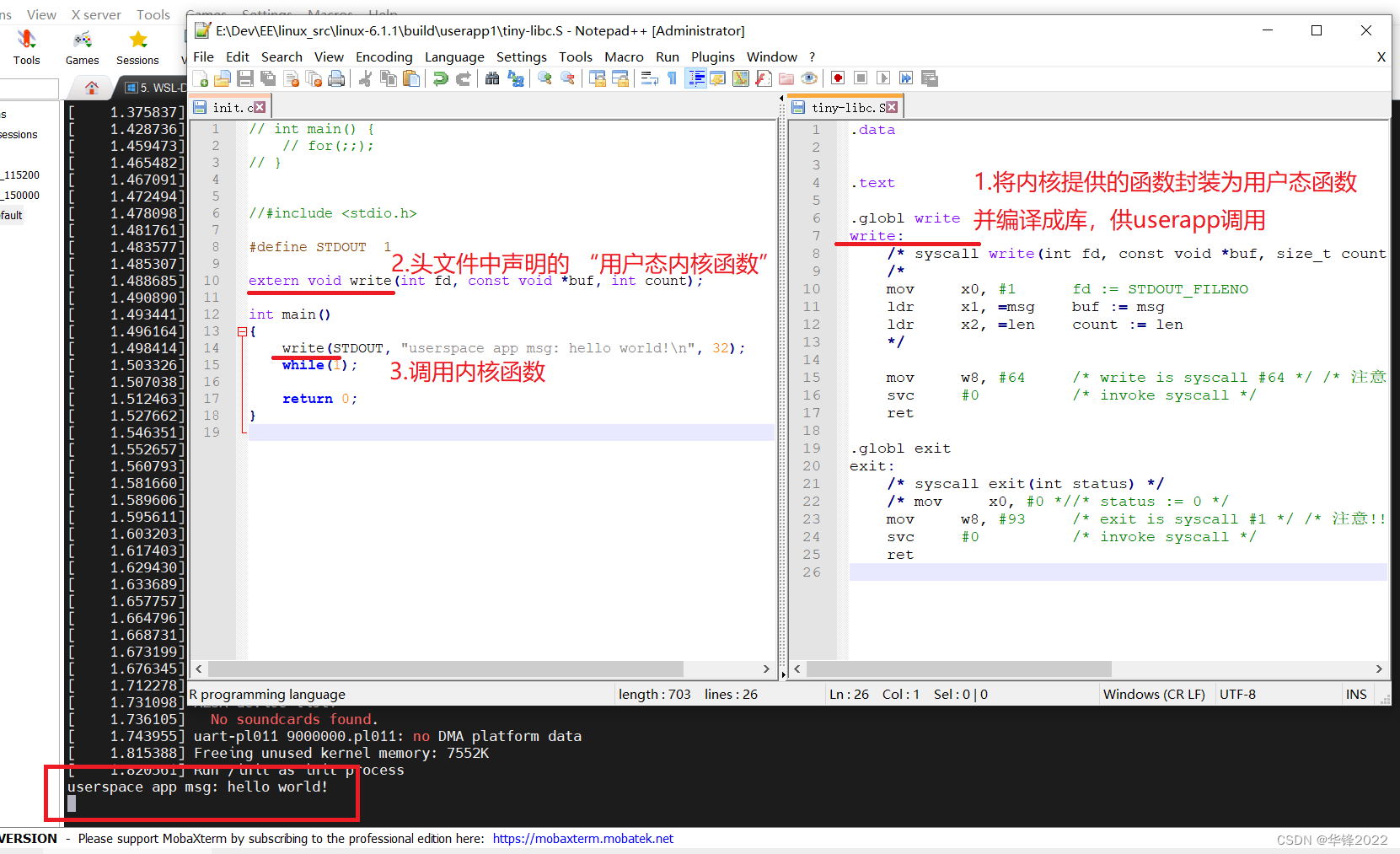
文章目录
- 一、前言
- 二、语法对比
- 数据表
- union
- join
- 1、两表 inner join
- 2、两表 left join
- 3、两表 right join
- 4、两表 outer join
- 5、多表 join
- 三、小结
一、前言
环境:
windows11 64位
Python3.9
MySQL8
pandas1.4.2
本文主要介绍 MySQL 中的union和join如何使用pandas实现,同时二者又有什么区别。
注:Python是很灵活的语言,达成同一个目标或有多种途径,我提供的只是其中一种解决方法,大家有其他的方法也欢迎留言讨论。
二、语法对比
数据表
本次使用的数据如下。
使用 Python 构建该数据集的语法如下:
import pandas as pd
import numpy as np
df1 = pd.DataFrame({ 'col1' : list(range(1,7))
,'col2' : ['AA','AA','AA','BB','BB','BB']#list('AABCA')
,'col3' : ['X',np.nan,'Da','Xi','Xa','xa']
,'col4' : [10,5,3,5,2,None]
,'col5' : [90,60,60,80,50,50]
,'col6' : ['Abc','Abc','bbb','Cac','Abc','bbb']
})
df2 = pd.DataFrame({'col2':['AA','BB','CC'],'col7':[1,2,3],'col4':[5,6,7]})
df3 = pd.DataFrame({'col2':['AA','DD','CC'],'col8':[50,70,90]})
注:直接将代码放 jupyter 的 cell 跑即可。后文都直接使用
df1、df2、df3调用对应的数据。
使用 MySQL 构建该数据集的语法如下:
with t1 as(
select 1 as col1, 'AA' as col2, 'X' as col3, 10.0 as col4, 90 as col5, 'Abc' as col6 union all
select 2 as col1, 'AA' as col2, null as col3, 5.0 as col4, 60 as col5, 'Abc' as col6 union all
select 3 as col1, 'AA' as col2, 'Da' as col3, 3.0 as col4, 60 as col5, 'bbb' as col6 union all
select 4 as col1, 'BB' as col2, 'Xi' as col3, 5.0 as col4, 80 as col5, 'Cac' as col6 union all
select 5 as col1, 'BB' as col2, 'Xa' as col3, 2.0 as col4, 50 as col5, 'Abc' as col6 union all
select 6 as col1, 'BB' as col2, 'xa' as col3, null as col4, 50 as col5, 'bbb' as col6
)
,t2 as(
select 'AA' as col2, 1 as col7, 5 as col4 union all
select 'BB' as col2, 2 as col7, 6 as col4 union all
select 'CC' as col2, 3 as col7, 7 as col4
)
,t3 as(
select 'AA' as col2, 50 as col8 union all
select 'DD' as col2, 70 as col8 union all
select 'CC' as col2, 90 as col8
)
select * from t1;
注:直接将代码放 MySQL 代码运行框跑即可。后文跑 SQL 代码时,默认带上数据集(代码的1~18行),仅展示查询语句,如第9行。
对应关系如下:
| Python 数据集 | MySQL 数据集 |
|---|---|
| df1 | t1 |
| df2 | t2 |
| df3 | t3 |
union
union的情况比较简单,就分两种:不去重的union all和去重的union。
1、不去重 union all
可以使用 Pandas 的pd.concat()函数实现 MySQL 的union。
注意向pd.concat()函数传递一个列表,将所有的数据集作为列表的元素,如果有三个表单进行union,则给列表3个对应的数据集作为元素即可,有几个加几个。reset_index()函数是重置索引,而参数drop=True则是删除旧的索引,如果不删除则是会多加一列index。如果不需要重置索引,则可以将.reset_index(drop=True)去掉。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | pd.concat([df1.col2,df2.col2]).reset_index(drop=True) | select col2 from t1 union all select col2 from t2; |
| 结果 | 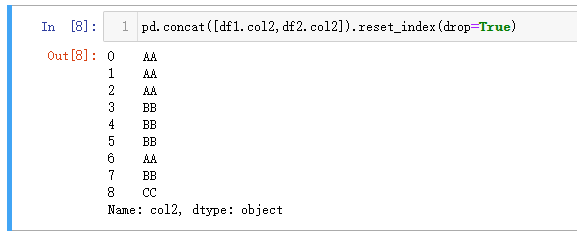 | 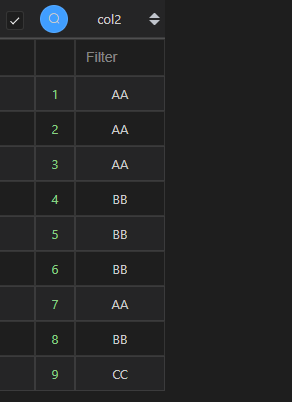 |
当union前后的表单有其他限制的时候,比如下例,则按照上一篇文章《Python和MySQL对比(1):用Pandas 实现MySQL语法效果》中的where条件进行处理即可。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1_1 = df1.col2[df1.col2==‘BB’] df2_1 = df2.col2[df2.col2==‘AA’] pd.concat([df1_1, df2_1]).reset_index(drop=True) | select col2 from t1 where col2=‘BB’ union all select col2 from t2 where col2=‘AA’; |
| 结果 |  | 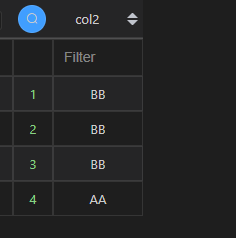 |
2、去重 union
MySQL 使用union,不加all,实现对合并的数据表进行去重,在 Pandas 中可以使用df.drop_duplicates()实现同样的效果。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | pd.concat([df1.col2,df2.col2]).drop_duplicates().reset_index(drop=True) | select col2 from t1 union select col2 from t2; |
| 结果 |  | 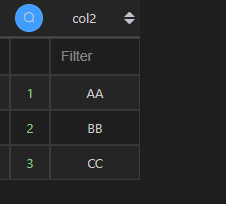 |
join
join的内容比较多,分inner join、left join、right join和outer join。在 Pandas 中,一般使用merge()实现,另外 Pandas 还有一个生成笛卡尔积的cross join,不过一般不会用到。用的最多的还是两个基本的inner join和left join,left join的联结方式相对比较好理解一些,right join一般可以通过left join实现。
而这些联结方式中,又分单个条件(on)和多个条件(and)、两个表的关联和多个表的关联。
下文就分别通过两个表介绍四种联结方法(顺带介绍多条件)和使用inner join和left join进行多表关联展开叙述。
1、两表 inner join
单条件,一般只有**on****将两个表的一个外键进行关联。**当两个表的键相同的时候,可以使用【代码一】直接使用on;如果两个表的键不同,则可以使用【代码二】分别用left_on和right_on指定对应的键的名称。suffixes参数是传递两个后缀,当两个表除了关联的外键之外,有同名的字段的时候,则分别给两个表同名的字段加上这里指定的后缀,默认是('_x','_y'),即左表的同名字段加上_x后缀,右表的同名字段加上_y后缀。
【代码一】和【代码二】都是使用pd.merge(df1,df2)进行操作,该函数的第一个参数是left即左表,第二个参数是right即右表;除了使用该方式,也可以使用df1.merge(df2),df1是左表,df2是右表,其他的参数和上一小段讲的一致。如下【代码三】和【代码四】的示例。
注:由于 MySQL 联结之后,有两个相同的列,第一个列的数据会被第二个列的数据覆盖,所以看到两个col2和col4列,且数据一致。而 Pandas 会将键保留一个,其他同名列加上后缀区分。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | 【代码一】pd.merge(df1,df2,on=‘col2’,how=‘inner’,suffixes=(‘_left’,‘_right’)) 【代码二】pd.merge(df1,df2,left_on=‘col2’,right_on=‘col2’,how=‘inner’,suffixes=(‘_left’,‘_right’)) 【代码三】 df1.merge(df2,on=‘col2’,how=‘inner’,suffixes=(‘_left’,‘_right’)) 【代码四】 df1.merge(df2,left_on=‘col2’,right_on=‘col2’,how=‘inner’,suffixes=(‘_left’,‘_right’)) | select * from t1 join t2 on t1.col2=t2.col2 ; |
| 结果 | 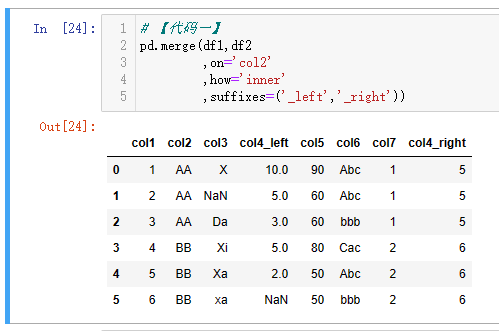 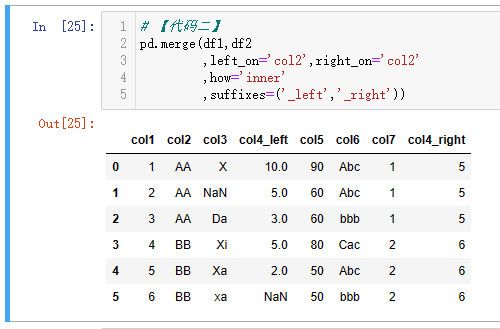 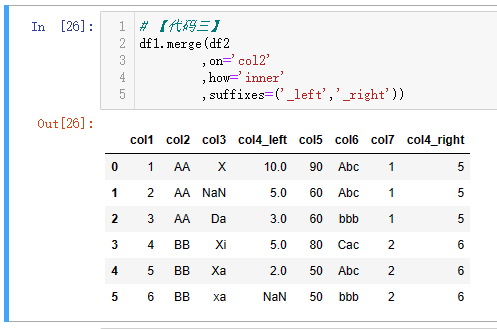 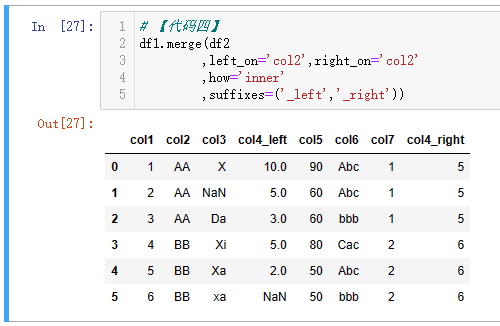 | 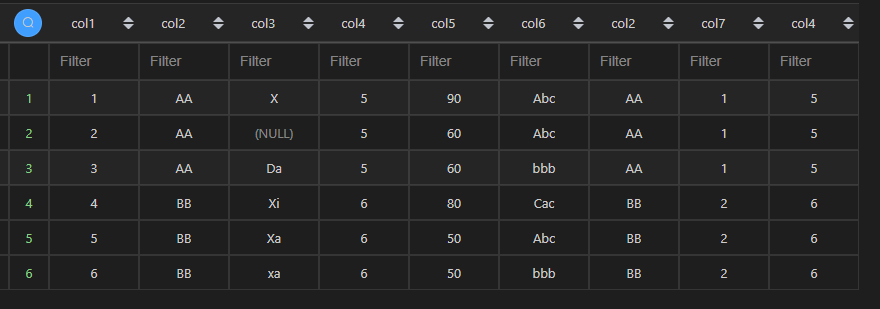 |
多条件-多个键
当多个键联结时,在单个键的基础上修改一下on或left join和right join的参数即可,以列表的形式作为参数值,列表的每个元素是外键的名称,每个外键在列表中的索引位置必须一一对应。
注:单个建,也可以使用列表的形式,传递键,这时列表中只有一个元素。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | 【代码一】 pd.merge(df1,df2,left_on=[‘col2’,‘col4’],right_on=[‘col2’,‘col4’],how=‘inner’,suffixes=(‘_left’,‘_right’)) 【代码二】 pd.merge(df1,df2,on=[‘col2’,‘col4’],how=‘inner’,suffixes=(‘_left’,‘_right’)) 【代码三】 df1.merge(df2,left_on=[‘col2’,‘col4’],right_on=[‘col2’,‘col4’],how=‘inner’,suffixes=(‘_left’,‘_right’)) 【代码四】 df1.merge(df2,on=[‘col2’,‘col4’],how=‘inner’,suffixes=(‘_left’,‘_right’)) | select * from t1 join t2 on t1.col2=t2.col2 and t1.col4=t2.col4; |
| 结果 |     |  |
多条件-单表限制条件
以下4个代码返回的结果是一致的。
针对 MySQL 的两个代码,【MySQL1】是join时同时进行筛选,而【MySQL2】则是先join完再进行where。
使用 pandas 实现的时候,可以在merge()前进行条件筛选,如下【代码一】;也可以在merge()之后再进行条件筛选,如下【代码二】。
注:用df1.merge(df2)和pd.merge(df1,df2)大同小异,针对df1.merge(df2)不再赘述。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | 【代码一】 pd.merge(df1,df2[df2.col2==‘AA’],left_on=[‘col2’],right_on=[‘col2’],how=‘inner’,suffixes=(‘_left’,‘_right’)) 【代码二】 df1_1 = pd.merge(df1,df2,left_on=[‘col2’],right_on=[‘col2’],how=‘inner’,suffixes=(‘_left’,‘_right’)) df1_1[df1_1.col2==‘AA’] | 【MySQL1】 select * from t1 join t2 on t1.col2=t2.col2 and t2.col2=‘AA’; 【MySQL2】 select * from t1 join t2 on t1.col2=t2.col2 where t2.col2=‘AA’; |
| 结果 |   | 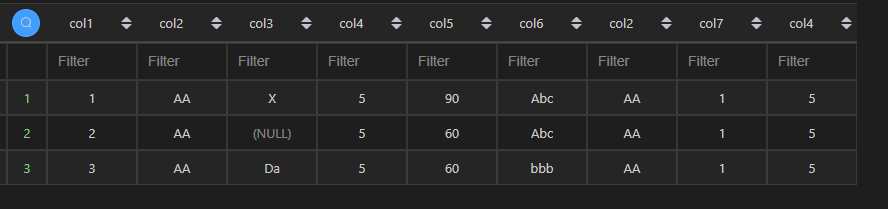 |
2、两表 left join
多条件-多键
单条件的比较简单,直接看一个多键的情况。
用 Python 实现left join的语法和inner join的语法差不多,只是把how的参数由inner改为left即可。当然,返回的结果是有一定差别的。left join是以左表为准,将右表能通过外键关联上的字段关联到左表上。
差异:在下面的例子中可以看出一些差异,Python 返回的结果只保留了左表的键,如果需要使用到右表的键,则不能直接使用,需要借助右表其他的列辅助判断。而 MySQL 还是可以通过 t2.col2和t2.col4进行调用右表的键。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | pd.merge(df1,df2,left_on=[‘col2’,‘col4’],right_on=[‘col2’,‘col4’],how=‘left’,suffixes=(‘_left’,‘_right’)) | select * from t1 left join t2 on t1.col2=t2.col2 and t1.col4=t2.col4; |
| 结果 |  | 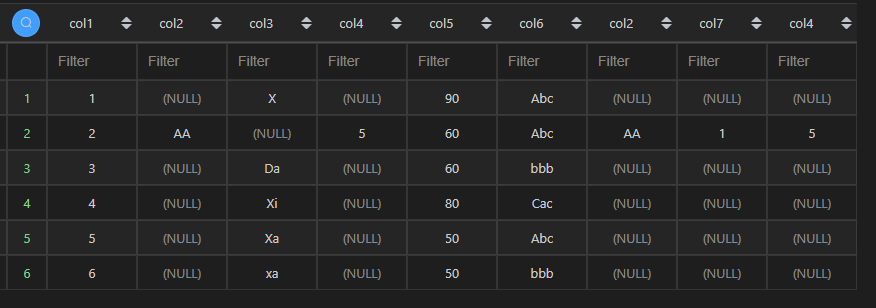 注:截图中由于有相同列,导致相同列显示数据不准确。 |
多条件-单表限制条件
当有多条件,且是对单独的表单进行限制的时候,和inner join有一些差异,下图是前面inner join多条件-单表限制条件的4个代码,结果是一致的。
如果改为left join,结果会大不同。
如下,【MySQL1】和【MySQL2】结果有很大不同,【MySQL1】是以t1为主表,and t2.col2='AA'条件是在关联的时候对t2进行筛选,筛选完再将t2关联到t1上,所以返回的记录都有t1表的数据,再加上能关联上t1.col2的t2表的列数据。而【MySQL2】是以t1为主表,直接将t2关联到t1上,然后再对关联后的数据通过where t2.col2='AA'进行筛选。
Python 【代码一】效果同【MySQL1】,【代码二】效果同【MySQL2】。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | 【代码一】 pd.merge(df1,df2[df2.col2==‘AA’],left_on=[‘col2’],right_on=[‘col2’],how=‘left’,suffixes=(‘_left’,‘_right’)) 【代码二】 df1_1 = pd.merge(df1,df2,left_on=[‘col2’],right_on=[‘col2’],how=‘left’,suffixes=(‘_left’,‘_right’)) df1_1[df1_1.col2==‘AA’] | 【MySQL1】 select * from t1 left join t2 on t1.col2=t2.col2 and t2.col2=‘AA’; 【MySQL2】 select * from t1 left join t2 on t1.col2=t2.col2 where t2.col2=‘AA’; |
| 结果 | 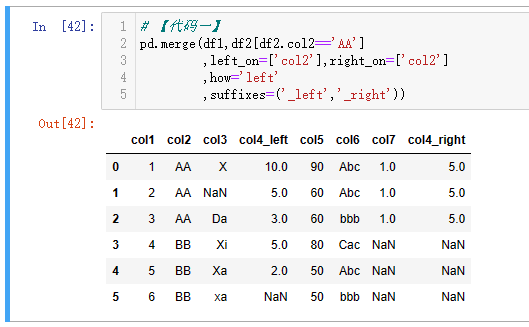  | 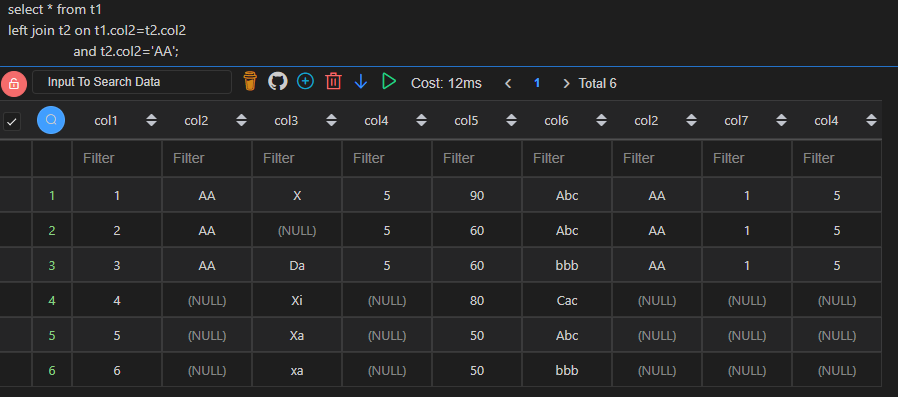 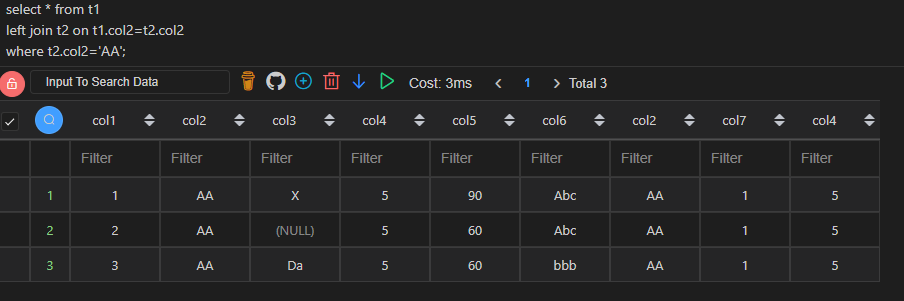 |
3、两表 right join
right join和left join语法和含义上差不多,如果将左右表位置换一下,就可以通过right join替换left join,具体看看下面例子,和left join的【多条件-多键】的效果(下图)是一致的。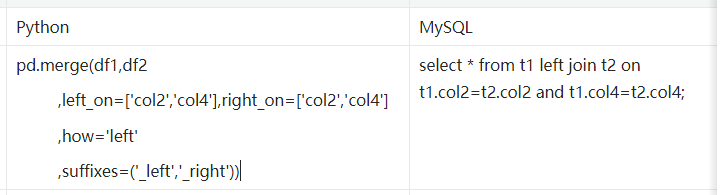
从以下例子可以看出二者的一些差异,Python 返回的结果只保留了右表的键,如果需要使用到左表的键,则不能直接使用,需要借助左表其他的列辅助判断。而 MySQL 还是可以通过 t2.col2和t2.col4进行调用左表的键。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | pd.merge(df2,df1,left_on=[‘col2’,‘col4’],right_on=[‘col2’,‘col4’],how=‘right’,suffixes=(‘_left’,‘_right’)) | select * from t1 left join t2 on t1.col2=t2.col2 and t1.col4=t2.col4; |
| 结果 |  | 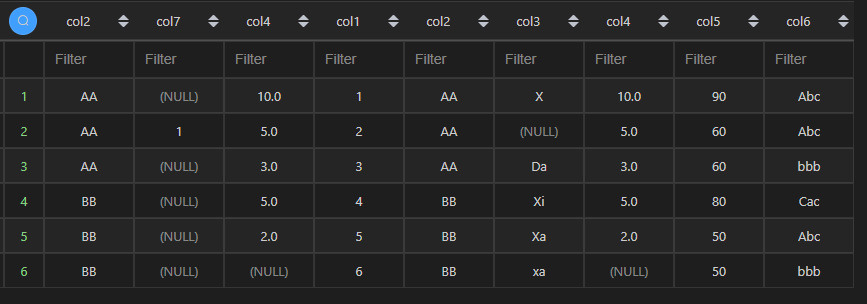 注:截图中由于有相同列,导致相同列显示数据不准确。 |
4、两表 outer join
outer join也叫full join,在 MySQL 8 中,有一些版本不支持full join,下表的【MySQL1】使用了full join的方式进行关联,如果使用不了该语法,也可以使用【MySQL2】或【MySQL3】代替。(注意,由于有多列col2,第一列会被第二列覆盖,所以为了看出差异,可以对其中一列进行重命名。)
而在 Python 中,没有对outer join限制,可以一步到位,如下【代码一】,该结果和 MySQL 也有一定的差异,主要是 Python 代码对左右表的col2列进行了合并,所以看到的col2列有4个值。另外, Python 的【代码二】和【代码三】也可以实现一样的效果,逻辑和【MySQL2】和【MySQL3】类似,不过由于外键覆盖,使用不到右表的外键,所以【代码三】通过右表的其他字段将空值筛选掉,但是需要保证这个其他字段没有空值,否则会使得原本需要保留的空值也被剔除掉。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | 【代码一】 pd.merge(df2,df3,left_on=[‘col2’],right_on=[‘col2’],how=‘outer’,suffixes=(‘_left’,‘_right’)) 【代码二】 df2_1 = pd.merge(df2,df3,left_on=[‘col2’],right_on=[‘col2’],how=‘left’,suffixes=(‘_left’,‘_right’)) df3_1 = pd.merge(df2,df3,left_on=[‘col2’],right_on=[‘col2’],how=‘right’,suffixes=(‘_left’,‘_right’)) pd.concat([df2_1, df3_1]).drop_duplicates().reset_index(drop=True) # 推荐 【代码三】 df2_1 = pd.merge(df2,df3,left_on=[‘col2’],right_on=[‘col2’],how=‘left’,suffixes=(‘_left’,‘_right’)) df3_1 = pd.merge(df2,df3,left_on=[‘col2’],right_on=[‘col2’],how=‘right’,suffixes=(‘_left’,‘_right’)) pd.concat([df2_1, df3_1[df3_1.col4.isna()]]).reset_index(drop=True) # 如果df3_1.col4本身有空值,会影响最终结果 | 【MySQL1】 select * from t2 full join t3 on t3.col2=t2.col2; 【MySQL2】 select * from t2 left join t3 on t3.col2=t2.col2 union all select * from t3 left join t2 on t3.col2=t2.col2 where t2.col2 is null; 【MySQL3】 select * from t2 left join t3 on t3.col2=t2.col2 union all select * from t2 right join t3 on t3.col2=t2.col2 where t2.col2 is null; |
| 结果 | 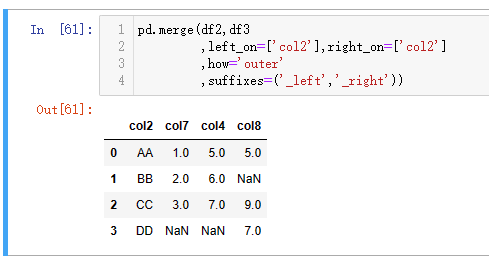 | 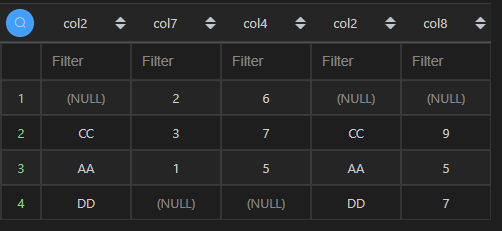 注:由于有多个相同列,第一列的数据会被第二列覆盖,可以通过命别名形式避免该问题。 |
其实,本次结果应该如下图所示。MySQL 和 Python 由于一些限制,返回的结果都有一些出入。
该图的 MySQL 代码如下:
select t2.col2 t2_col2,t2.col7,t2.col4,t3.col2 t3_col2,t3.col8
from t2 full join t3 on t3.col2=t2.col2;
-- 或
select t2.col2 t2_col2,t2.col7,t2.col4,t3.col2 t3_col2,t3.col8
from t2 left join t3 on t3.col2=t2.col2
union all
select t2.col2 t2_col2,t2.col7,t2.col4,t3.col2 t3_col2,t3.col8
from t3 left join t2 on t3.col2=t2.col2 where t2.col2 is null;
5、多表 join
多表进行join的时候,推荐使用df1.merge(df2)的形式来进行链式join,如下例子
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1.merge(df2,left_on=‘col2’,right_on=‘col2’,how=‘left’).merge(df3,left_on=‘col2’,right_on=‘col2’,how=‘left’) | select * from t1 left join t2 on t2.col2=t1.col2 left join t3 on t3.col2=t1.col2 |
| 结果 |  |  注:由于有多个相同列,第一列的数据会被第二列覆盖,可以通过命别名形式避免该问题。 |
Python 对外键的处理同样存在合并的情况,除了该问题,还需要注意的一点是,当非外键有重复列的时候,Python 会添加后缀,如果后缀在后面的join中有作为外键使用,则需要注意加上带有外键的字段名称。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1.merge(df2,left_on=‘col2’,right_on=‘col2’,how=‘left’,suffixes=(‘_x’,‘_y’)).merge(df3,left_on=‘col4_y’,right_on=‘col8’,how=‘left’,suffixes=(‘_left’,‘_right’)) | select * from t1 left join t2 on t2.col2=t1.col2 left join t3 on t3.col8=t2.col4; |
| 结果 |  | 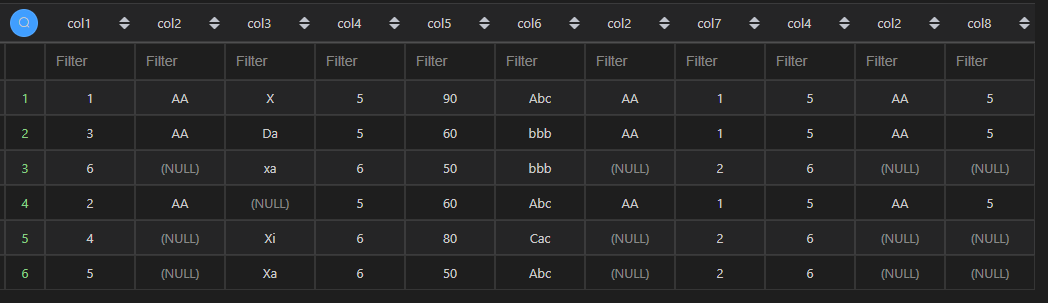 注:由于有多个相同列,第一列的数据会被第二列覆盖,可以通过命别名形式避免该问题。 |
三、小结
Python 在多表联结的时候,会对外键进行合并,当使用的是inner join时,无所谓,但是如果使用的是left join、right join或inner join时,需要注意该差异,避免一些不必要的错误。