前 言
YOLO算法改进系列出到这,很多朋友问改进如何选择是最佳的,下面我就根据个人多年的写作发文章以及指导发文章的经验来看,按照优先顺序进行排序讲解YOLO算法改进方法的顺序选择。具体有需求的同学可以私信我沟通:第一,创新主干特征提取网络,将整个Backbone改进为其他的网络,比如这篇文章中的整个方法,直接将Backbone替换掉,理由是这种改进如果有效果,那么改进点就很值得写,不算是堆积木那种,也可以说是一种新的算法,所以做实验的话建议朋友们优先尝试这种改法。
第二,创新特征融合网络,这个同理第一,比如将原yolo算法PANet结构改进为Bifpn等。
第三,改进主干特征提取网络,就是类似加个注意力机制等。根据个人实验情况来说,这种改进有时候很难有较大的检测效果的提升,乱加反而降低了特征提取能力导致mAP下降,需要有技巧的添加。
第四,改进特征融合网络,理由、方法等同上。
第五,改进检测头,更换检测头这种也算个大的改进点。
第六,改进损失函数,nms、框等,要是有提升检测效果的话,算是一个小的改进点,也可以凑字数。
第七,对图像输入做改进,改进数据增强方法等。
第八,剪枝以及蒸馏等,这种用于特定的任务,比如轻量化检测等,但是这种会带来精度的下降。
...........未完待续
一、创新改进思路或解决的问题
将Backbone网络改为传统的resnet18等timm支持的网络,作为创新改进思路。
二、基本原理
原文链接:
代码链接:https://github.com/StevenLauHKHK/Large-Separable-Kernel-Attention/blob/main/mmsegmentation/van.py
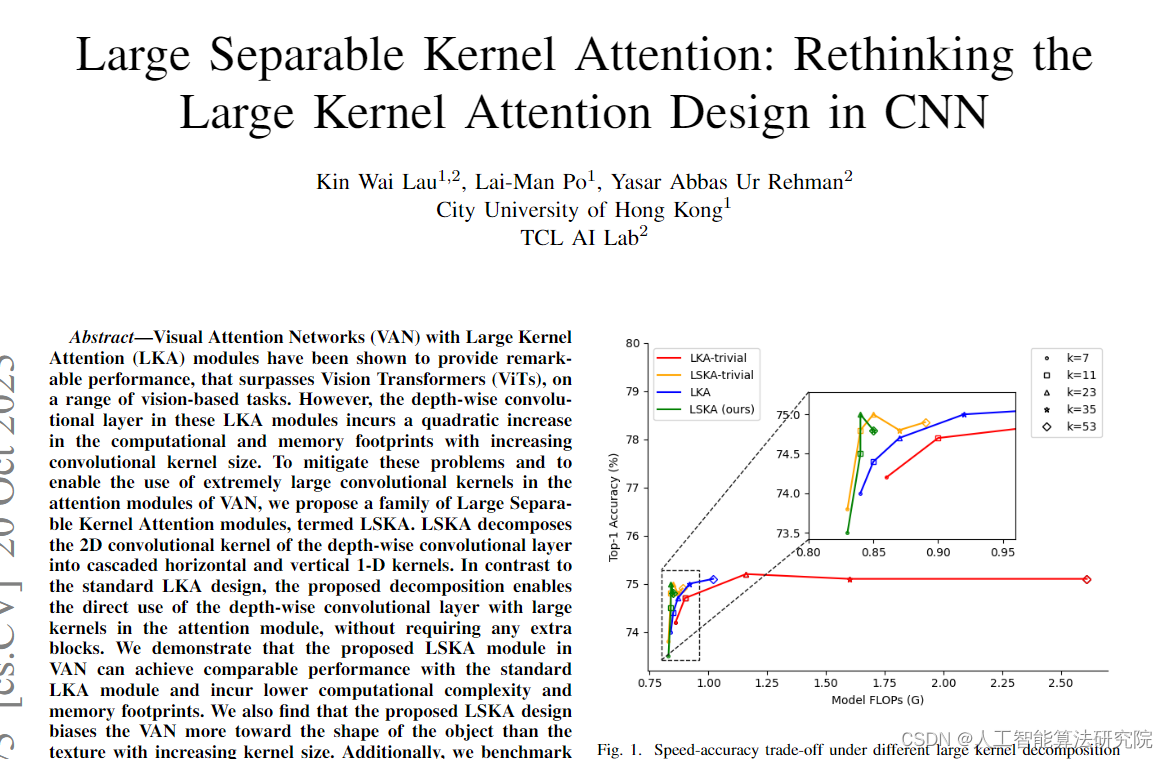 摘要:具有大内核注意力(LKA)模块的视觉注意力网络(VAN)已被证明在一系列基于视觉的任务中提供了超过视觉转换器(ViTs)的可注释性能。然而,随着卷积核大小的增加,这些LKA模块中的深度卷积层导致计算和内存占用的二次增加。为了缓解这些问题,并使超大卷积核能够在VAN的注意力模块中使用,我们提出了一系列大的可分离核注意力模块,称为LSKA。LSKA将深度卷积层的2D卷积核分解为级联的水平和垂直一维核。与标准LKA设计相比,所提出的分解能够在注意力模块中直接使用具有大内核的深度卷积层,而不需要任何额外的块。我们证明了所提出的VAN中的LSKA模块可以实现与标准LKA模块相当的性能,并降低计算复杂度和内存占用。我们还发现,随着内核大小的增加,所提出的LSKA设计使VAN更倾向于对象的形状,而不是纹理。此外,我们在ImageNet数据集的五个损坏版本上对VAN、ViTs和最近的ConvNeXt中的LKA和LSKA的稳健性进行了基准测试,这些版本在以前的工作中基本上未被探索。我们广泛的实验结果表明,随着内核大小的增加,VAN中提出的LSKA模块显著降低了计算复杂度和内存占用,同时在对象识别、对象检测、语义分割和鲁棒性测试方面优于ViTs、ConvNeXt,并提供了与VAN中LKA模块类似的性能。
摘要:具有大内核注意力(LKA)模块的视觉注意力网络(VAN)已被证明在一系列基于视觉的任务中提供了超过视觉转换器(ViTs)的可注释性能。然而,随着卷积核大小的增加,这些LKA模块中的深度卷积层导致计算和内存占用的二次增加。为了缓解这些问题,并使超大卷积核能够在VAN的注意力模块中使用,我们提出了一系列大的可分离核注意力模块,称为LSKA。LSKA将深度卷积层的2D卷积核分解为级联的水平和垂直一维核。与标准LKA设计相比,所提出的分解能够在注意力模块中直接使用具有大内核的深度卷积层,而不需要任何额外的块。我们证明了所提出的VAN中的LSKA模块可以实现与标准LKA模块相当的性能,并降低计算复杂度和内存占用。我们还发现,随着内核大小的增加,所提出的LSKA设计使VAN更倾向于对象的形状,而不是纹理。此外,我们在ImageNet数据集的五个损坏版本上对VAN、ViTs和最近的ConvNeXt中的LKA和LSKA的稳健性进行了基准测试,这些版本在以前的工作中基本上未被探索。我们广泛的实验结果表明,随着内核大小的增加,VAN中提出的LSKA模块显著降低了计算复杂度和内存占用,同时在对象识别、对象检测、语义分割和鲁棒性测试方面优于ViTs、ConvNeXt,并提供了与VAN中LKA模块类似的性能。
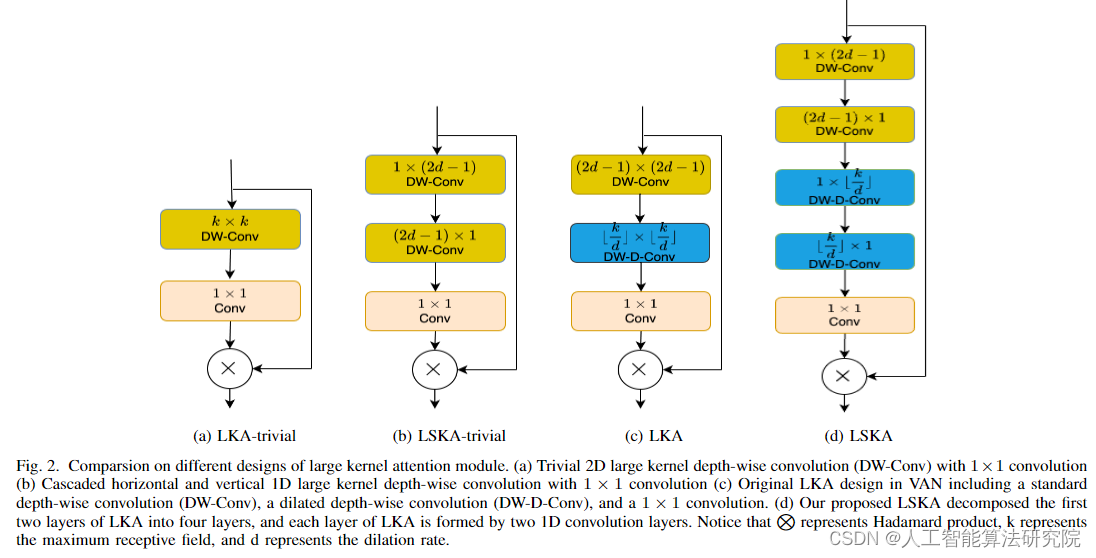
三、添加方法
部分代码如下所示,详细改进代码可私信我获取。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, resnet18, [False]] # 4
- [-1, 1, SPPF, [1024, 5]] # 5
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 6
- [[-1, 3], 1, Concat, [1]] # 7 cat backbone P4
- [-1, 3, C2f, [512]] # 8
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 9
- [[-1, 2], 1, Concat, [1]] # 10 cat backbone P3
- [-1, 3, C2f, [256]] # 11 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]] # 12
- [[-1, 8], 1, Concat, [1]] # 13 cat head P4
- [-1, 3, C2f, [512]] # 14 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]] # 15
- [[-1, 5], 1, Concat, [1]] # 16 cat head P5
- [-1, 3, C2f, [1024]] # 17 (P5/32-large)
- [[11, 14, 17], 1, Detect, [nc]] # Detect(P3, P4, P5)
四、总结
预告一下:下一篇内容将继续分享深度学习算法相关改进方法。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦
PS:该方法不仅仅是适用改进YOLOv5,也可以改进其他的YOLO网络以及目标检测网络,比如YOLOv7、v6、v4、v3,Faster rcnn ,ssd等。
最后,有需要的请关注私信我吧。关注免费领取深度学习算法学习资料!