文章目录
- 引言
- 什么时候适合加缓存?
- 示例1
- 示例2:
- 示例3:
- 缓存应该怎么配置?
- 数据分布
- **缓存容量大小:**
- 数据淘汰策略
- 缓存的副作用
- 总结
引言
在上一篇文章IO密集型服务提升性能的三种方法中,我们提到了三种优化IO密集型系统的方法,其中添加缓存(cache)的方法是最常用的,而且普适性也是最强的,今天展开讲下如何正确使用缓存。准确说我们需要解决下面三个大问题。
- 什么样的情况下才适合加缓存?
- 缓存应该怎么配置?
- 如何解决或者减少缓存的副作用?
什么时候适合加缓存?
我们先解决第一个问题,什么情况下适合加缓存。 一句话总结就是**如果某个数据获取”成本高“,并且数据是长期有价值,那么这份数据是可以加缓存的。**至于这个”长期“到底有多长,我们会在后文中详细讲解到。 注意 获取成本高 并且 长期有价值, 这两个条件是加缓存的必要条件,必须满足这两个条件才可以添加缓存。成本高和长期有价值这两个词很抽象,怎么判定成本高?什么叫长期有价值?其实这里没有客观的判定标准,只能是通过对比的方式, 我们拿两个具体的示例来说明下。
示例1
你登陆到微信后,你好友的头像需要展示到微信各个页面里(聊天、点赞、评论……),头像是一张图片,图片的获取成本相对于纯文本几十个字节的数据是比较高的,毕竟即便是一张缩略图也有几十KB大小,这里就体现出了图片数据相对的成本高。而微信头像很少会变化,拉取一次长期有效,这里就体现出来了长期有价值的特性。这个场景就很符合可以缓存的数据的特点。事实上微信确实也是这么做的,你换个新头像然后去好友那边观察,那边也不会立即生效的。
示例2:
可能家庭条件好的同学都在双十一买过东西吧,你看中的某个商品库存信息,它是一直在变化的,你现在看到是100但可能下一秒就变成0了。因为这个数据一直是变化的,这个数据对时效性的要求很严格,所以它不满足”长期有价值“这个条件,因此它是无法缓存的。
示例3:
比如我要扫一遍我们系统里所有内容数据,找出其中不合规的内容,对于单条的内容判定是很消耗资源,而且判断结果之后也是一直有效的。这种情况下也没有必要加缓存,因为判定结果我使用一次之后也不会再用了,这里数据不符合长期有价值的特性。 因此这里也是没必要加缓存的。
有些数据单次获取的成本不高,但获取频次非常高,这种总的获取成本非常高其实也算是获取成本高。比如各系统里和人员有个的信息,这种其实一个接口也能快速返回,但架不住调用的次数多,这种情况下也是可以添加缓存来减轻压力的。 我们从获取成本和长期价值两个维度可以将数据请求拆分到4个象限。

通过 获取成本高 并且 长期有价值 这两个维度,你可以想想在你所遇到的所有业务场景中,有哪些是可以通过加缓存来提升性能的?
缓存应该怎么配置?
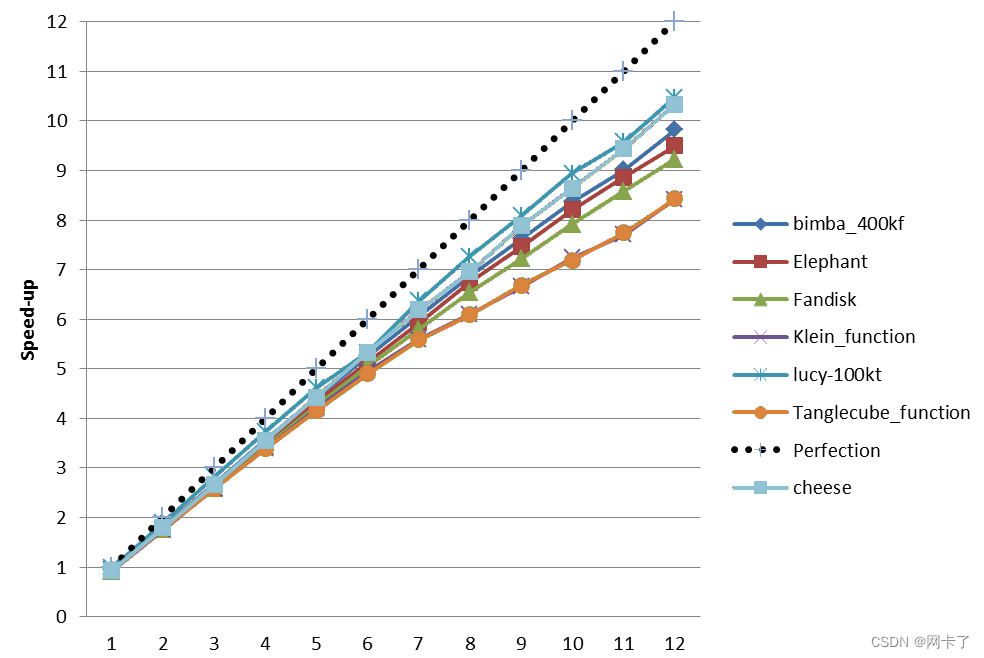
在解决了什么场景下可以加缓存的时候,就得考虑怎么配置缓存了。这里先来介绍下一个如何评估缓存性能的公式,为了直观点我们以IO密集型场景举例,IO密集型衡量性能的一个关键指标就是访问延迟(latency),在缓存的加持下,整个系统的平均延时计算方式如下:
a v g L a t e n c y = h i t R a t e × c a c h e L a t e n c y + ( 1 − h i t R a t e ) × o r i g i n a l L a t e n c y (1) avgLatency = hitRate \times cacheLatency + (1 - hitRate) \times originalLatency \tag{1} avgLatency=hitRate×cacheLatency+(1−hitRate)×originalLatency(1)
其中 hitRate 代表的是缓存的命中率,cacheLatency是访问一次缓存时的延时,originalLatency 是访问一次原始数据时的延迟。avgLatency就是我们系统最终的延迟,这个值越低越好。 有些同学可能会问,为什么我们不直接把数据全部放到访问最快的存储介质中? 这里就涉及到不同存储介质的特性了,主要是其数据访问速度、价格导致,总之越快的存储介质,单位价格也就越高,这里就不在展开了,大家可以自行查阅下资料。
在我们选定一种缓存介质时,缓存延迟(cacheLatency)也就基本固定下来了,而原始数据的访问延迟(originalLatency)我们肯定是干预不了的。剩下我们能干预的也只有缓存命中率(hitRate)。我们以redis作为缓存为例,然后缓存某个10ms接口的数据,同机房内redis访问延迟是0.1ms的量级 当缓存命中率分别为1% 10% 50% 90% 100%时,我们用上面公式计算出来的结果分别是 9.9ms 9ms 5ms 1ms 0.1ms。可以看出在不同的缓存命中率下最终结果也有着巨大的差异,命中率越高性能越强。
由于成本限制,我们一般是不会将全量的数据导入到缓存介质里的,所以大部分情况下缓存命中率不会是100%,而且还希望缓存空间用的越少越好。如何在有限的缓存介质下,提升系统性能? 从上面的公式就可以看出,提升缓存性能最关键的就是提升缓存的命中率,而缓存的命中率和数据的访问分布、缓存的大小、缓存数据淘汰策略息息相关。
**数据分布:**数据访问是否有规律,是否可以利用这些规律?
**缓存大小:**指缓存最多能存储多少的数据。
**数据淘汰策略:**在缓存已满的情况下,如何剔除缓存中价值最低的数据,腾出空间来给别的数据使用。
数据分布

当我将一份单位时间内访问频次标记在纵坐标轴上,并且按频次从大到小排序。大部分情况下我们会的到以上这张数据访问分布图,可以看出最左侧的一部分数据占掉了总体访问非常大的一部分(头部效应),而且长尾的大量数据被访问的频次很低。这就是大家所熟知的长尾分布。 这种分布下的数据是最时候加缓存的,头部效应越明显加缓存后的性能提升越明显,幸运的是在现实世界中,绝大多数数据的访问分布都是这样的。
当然也有部分数据在单位时间内访问的频次很均匀,这种一般都是程序定时触发的数据访问,这种情况下添加缓存带来的效果提升就很弱,甚至没有提升。 所以你会看到在定时任务里,很少会考虑去加缓存。
缓存容量大小:

在确定了数据分布后,就得考虑缓存容量大小的问题了。从上面的性能计算公式来看,理论上缓存容量越大,缓存对性能提升就越明显,但上文我也提到了越快的存储介质价格越高。在上图中,蓝色框相比红色框在容量增加一倍后,其覆盖的数据访问(曲线下方带背景色面积)远没有增加一倍,后面增加缓存带来的覆盖率增长也会越来越低。
可以看出,缓存容量大小也会显著影响到缓存的命中率,从而影响到性能提升。反过来,我们在知道预期性能目标后,也可以根据上面的公式反向去计算预期缓存命中率,然后计算出缓存的最小合理配置大小。
数据淘汰策略
当缓存已满时,我们就需要考虑如何淘汰出当前缓存下最没有价值的数据,也就是未来最不可能被访问的数据。 没有任何人或者系统拥有准确预知未来的能力,但我们有个简单策略来估算每份数据未来可能被使用的概率,这个策略背后的依据就是局部性,如果某个数据被访问了,那么它未来被访问的概率会高于其他未被访问的数据。已被访问的频次越高,未来再被访问的可能性也就越高。所以这里我们只需要记录下每份数据被访问的频次,然后把缓存中被访问频次最低的一份数据删除掉就行。
说到这里我们已经不小心发明了LFU (Least Frequently Used)缓存淘汰策略,即维护每份数据的访问频次,当缓存空间不足时,淘汰访问频次最少的一份数据。 与之齐名了还有LRU (Least Recently Used),LRU每次淘汰缓存中最长没有被使用过的数据,具体实现的时候按数据被访问的时间由近到远排成一个队列,然后淘汰最尾的一份数据,相对与LFU实现会简单很多。
LFU和LRU在一定程度上都实现了淘汰最低价值数据的功能,但还是有一些差异的。
- LFU (Least Frequently Used): 这种策略会淘汰在一段时间内被访问次数最少的数据。这意味着即使某个数据项最近被访问过,但只要其总的访问次数仍然是最少的,那么就会被淘汰。LFU适合的场景是存在长期热点数据的情况,也就是说有一部分数据的访问频率持续地高于其他数据。
- LRU (Least Recently Used): 这种策略会将最近最少使用的数据项淘汰。也就是说,如果一个数据项在过去被访问的频率较低,那么在需要淘汰数据以腾出空间时,这个数据项会被优先考虑。LRU比较适合在数据访问模式中存在明显的"最近偏好"特性的情况,即最近访问过的数据在未来被再次访问的概率相对较高。
总的来讲,LFU能涵盖的数据时间窗口更大,而LRU只能覆盖缓存大小那么大的时间窗口,所以LFU更适合大时间窗口下头部效应明显的数据,而LRU更适合小时间窗口下头部效应明显的数据。根据我的使用经验,LRU大部分情况下足以。
除了LRU和LFU之外,还有其他的数据淘汰策略,比如FIFO和Random,甚至还有一些LRU和LFU的改进策略,核心都是为了提升缓存的命中率,在具体选择的时候,还是需要根据自己的缓存大小和数据分布,选择合适的数据淘汰策略。
缓存的副作用
缓存最大的副作用就是数据的不一致性,这也是很多人谈缓存色变,甚至成为拒绝使用缓存的理由。确实使用缓存会有数据不一致性的可能,但实际上很多系统是可以接受短暂的数据不一致性的。就像上文中微信头像的问题,实测更换微信头像后,甚至几天后别人看到的还是你的旧头像。不是微信没法解决头像一致性的问题,而是这个问题价值并不大,很多人都能接受。
避免数据一致性的问题分为被动和主动两种方式,被动方式就是给数据设置有效期,像大家在使用redis缓存或者spring-cache时,都是可以设置数据过期时间的。当然数据过期时间的设置也是有讲究的,设大了不仅浪费空间,而且还会增加读到就数据的概率。 命中过期数据的概率可以用以下公式计算:
i n v a l i d H i t R a t e = c a c h e E x p i r e T i m e 2 d a t a U p d a t e I n t e r v a l × c a c h e H i t R a t e (2) invalidHitRate= \frac{\frac{cacheExpireTime}{2}} {dataUpdateInterval} \times cacheHitRate \tag{2} invalidHitRate=dataUpdateInterval2cacheExpireTime×cacheHitRate(2)
其中dataUpdateInterval指的是数据的更新时间间隔,比如某些数据平均3天更新一次,这里就是3天。cacheExpireTime就是你在设置缓存的时候数据的有效期,任意时刻下剩余有效期平均就是原来的1/2。而cacheHitRate就是上文中提到的缓存命中率。 在开接受的错误率下,根据缓存命中率和数据更新的周期,就可以反推出一个合理的缓存数据有效期。 这里需要注意的时,对缓存数据设置过期时间也可能会显著影响缓存的命中率,最终缓存的命中率需要综合缓存大小、数据淘汰策略和缓存过期时间综合去看。
另外一种主动的方式就是在检测到数据发生变化后,主动删除缓存里的数据,或者是主动将变更后的数据写入。相比被动的方式,错误数据的命中率会显著降低。计算错误数据命中率时,将公式2中的cacheExpireTime替换为数据变更处理时间即可,这在实际使用中这部分时间几乎是0。 但主动更新的方式有很高的实现复杂度,首先数据需要有变更事件通知的能力,这在很多系统里都是需要额外开发的。其次还需要实现变更监听和写入的逻辑,又带来了额外的开发量。 所以除非是很重要的数据,一般不会选择主动更新的方式。
总结
在本文中,我们探讨了正确使用缓存以提升系统性能的关键要素。首先,我们通过数据获取成本和长期价值两个维度来确定是否适合添加缓存。然后,我们深入讨论了缓存配置的策略,包括如何根据访问延迟、命中率以及存储成本来评估和优化缓存表现。其中缓存命中率是性能提升的核心,而这与数据访问的分布、缓存的大小和数据的淘汰策略紧密相关。最后,我们讨论了缓存带来的主要副作用:数据一致性问题。我们介绍了两种处理这一问题的方法,一种是被动的设置数据有效期,另一种是主动的数据更新策略,每种方法都有其适用场景和权衡考量。
缓存是一个强大的工具,用好的话还是可以显著提升系统性能的。选择是否以及如何使用缓存需要从数据特性、业务需求和成本收益上综合去考虑。正确的配置和管理可以最大化缓存的优势,同时降低潜在的风险。