注:最后有面试挑战,看看自己掌握了吗
文章目录
什么是特征工程?
算法 特征工程
影响最终效果--------数据和特征工程 决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
意义:直接影响机器学习效果
一种数据处理
用什么做?
pandas------数据清洗、数据处理
sklearn------对特征处理提供了强大的接口
1.特征提取
比如文章分类
机器学习算法-------统计方法------数学公式
文本类型—》数值
类型-------》数值
任意数据-----------》用于机器学习的数字特征
特征值化:
字典特征提取---------特征离散化
文本特征提取
图像特征提取---------深度学习
特征提取API
sklearn.featurn_extraction()
字典特征提取—向量化—类别–》one-hot编码
sklearn.featurn_extraction.DicVertorizer(sparse=True,...)
vector 向量、
matrix矩阵----二维数组
vector 一维数组
父类:转换器类
哑变量
哑变量定义
哑变量(DummyVariable),也叫虚拟变量,引入哑变量的目的是,将不能够定量处理的变量量化,在线性回归分析中引入哑变量的目的是,可以考察定性因素对因变量的影响,它是人为虚设的变量,通常取值为0或1,来反映某个变量的不同属性。对于有n个分类属性的自变量,通常需要选取1个分类作为参照,因此可以产生n-1个哑变量。
如职业、性别对收入的影响,战争、自然灾害对GDP的影响,季节对某些产品(如冷饮)销售的影响等等。
这种“量化”通常是通过引入“哑变量”来完成的。根据这些因素的属性类型,构造只取“0”或“1”的人工变量,通常称为哑变量(dummyvariables),记为D。
举一个例子,假设变量“职业”的取值分别为:工人、农民、学生、企业职员、其他,5种选项,我们可以增加4个哑变量来代替“职业”这个变量,分别为D1(1=工人/0=非工人)、D2(1=农民/0=非农民)、D3(1=学生/0=非学生)、D4(1=企业职员/0=非企业职员),最后一个选项“其他”的信息已经包含在这4个变量中了,所以不需要再增加一个D5(1=其他/0=非其他)了。这个过程就是引入哑变量的过程,其实在结合分析(ConjointAnalysis)中,就是利用哑变量来分析各个属性的效用值的。
此时,我们通常会将原始的多分类变量转化为哑变量,每个哑变量只代表某两个级别或若干个级别间的差异,通过构建回归模型,每一个哑变量都能得出一个估计的回归系数,从而使得回归的结果更易于解释,更具有实际意义。
将类别转换成了one-hot编码
sparse-------稀疏矩阵--------------返回值-----省内存,提高加载速度------将非零值按位置表示出来
1.DictVectorizer()使用默认参数会返回一个稀疏矩阵
代码如下:
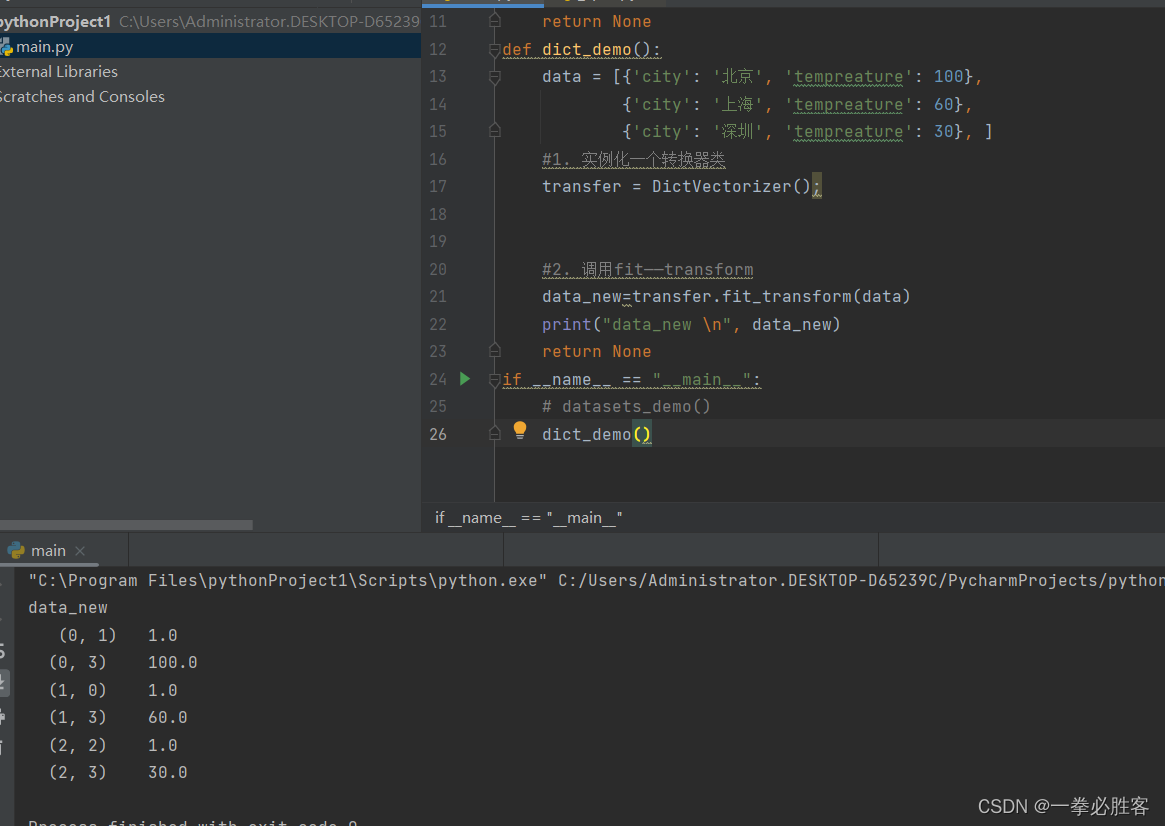
#1)实例化一个转换器类 2)调用fir_transform()方法
from sklearn.feature_extraction import DictVectorizer#导包
#下面的data是数据
data=[{'city':'北京','tempreature':100},
{'city':'上海','tempreature':60},
{'city':'深圳','tempreature':30},]
#1实例化一个转换器类
transfer=DictVectorizer()
#2调用一fit_transform()方法
data_new=transfer.fit_transform(data)
print("看一下转换的结果data_new:\n",data_new)
print("看一下特征的名字:\n",transfer.get_feature_names())
运行结果如下:
看一下转换的结果data_new:
(0, 1) 1.0
(0, 3) 100.0
(1, 0) 1.0
(1, 3) 60.0
(2, 2) 1.0
(2, 3) 30.0
看一下特征的名字:
[‘city=上海’, ‘city=北京’, ‘city=深圳’, ‘tempreature’]
data_new
[[ 0. 1. 0. 100.]
[ 1. 0. 0. 60.]
[ 0. 0. 1. 30.]]
one-hot-------直接1234会产生歧义,不公平
所以用onehot
应用场景
- pclass sex 数据集类别特征较多的情况
将数据集的特征转换为字典类型,
DictVectorizer转换
- 本身拿到的数据就是字典类型
文本特征提取
单词作为特征
句子、短语、单词、字母
单词最合适
特征:特征词
实例
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
def datasets_demo():
#获取数据集
iris = load_iris();
print('鸢尾花数据集的描述:\n', iris.data, iris.data.shape)
x_train, x_test, y_train, y_test=train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("xunlianjitezhengzhi:\n:", x_train, x_train.shape)
return None
def count_demo():
data = ["The voice of one man is the voice of no one one",
"The voice of one woman is the voice of one"]
# 1.实例化一个转换器类
transfer = CountVectorizer() # 注意CountVecotrizer()没有sparse参数,所以无法通过调节sparse参数来调节返回的结果
# transfer = CountVectorizer(stop_words=['one']) # 注意CountVecotrizer()有一个stop_words参数用于去除不需要提取的词,且stop_words必须传一个列表对象
# 2.调用实例对象的fit_transform()
new_data = transfer.fit_transform(data) # 会自动去除单个词
# print("new_data:\n",new_data) # 返回稀疏矩阵(通常默认情况下都是返回稀疏矩阵)
print("new_data:\n", new_data.toarray()) # 返回密集矩阵
return None
if __name__ == "__main__":
# datasets_demo()
count_demo()
new_data:
[[1 1 1 2 3 2 2 0]
[1 0 0 2 2 2 2 1]]
Process finished with exit code 0
countVectorizer统计每个样本特征词出现的个数
中文无法用此方法划分,会把一句话当作一个词,可以手动分词解决
借助工具:jieba分词---------结巴
中文文本特征抽取—jieba结巴
import sklearn.feature_extraction.text as text
import jieba
transfer = text.CountVectorizer(stop_words=['vb'])
def count_chinese_demo2():
data = ['发表回复这件事', '飞机里面飞一杯飞机专属奶茶', '没有什么比在飞机上喝一杯飞机专属的飞机奶茶要更好了']
data_new = []
# 中文文本分词
for send in data:
data_new.append(' '.join(list(jieba.cut(send))))
print(data_new)
# 文本特征提取
data_final = transfer.fit_transform(data_new)
print(data_final.toarray())
# print(transfer.get_feature_names())
if __name__ == "__main__":
count_chinese_demo2()
['发表 回复 这件 事', '飞机 里面 飞 一杯 飞机 专属 奶茶', '没有 什么 比 在 飞机 上 喝一杯 飞机 专属 的 飞机 奶茶 要 更好 了']
[[0 0 0 1 0 1 0 0 0 1 0 0]
[1 1 0 0 0 0 1 0 0 0 1 2]
[0 1 1 0 1 0 1 1 1 0 0 3]]
Process finished with exit code 0
🌸I could be bounded in a nutshell and count myself a king of infinite space.
特别鸣谢:木芯工作室 、Ivan from Russia