前言
大家早好、午好、晚好吖 ❤ ~

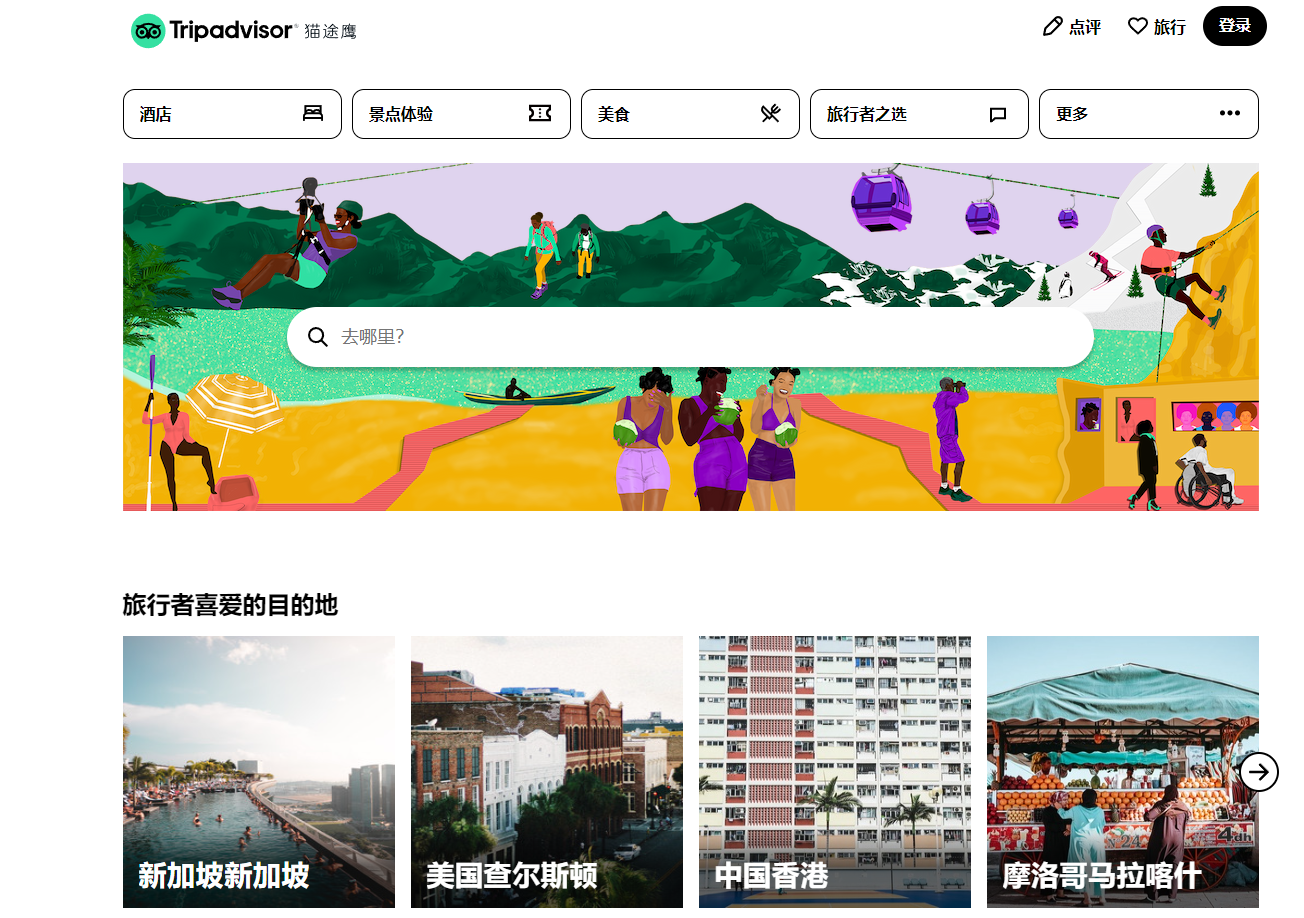
面试实战题:采集世界最大旅游平台Tripadvisor
另我给大家准备了一些资料,包括:
2022最新Python视频教程、Python电子书10个G
(涵盖基础、爬虫、数据分析、web开发、机器学习、人工智能、面试题)、Python学习路线图等等
全部可在文末名片获取哦!

第三方库:
-
requests >>> pip install requests
-
parsel >>> pip install parsel
安装python第三方模块:
-
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
-
在pycharm中点击Terminal(终端) 输入安装命令
开发环境:
-
版 本: python 3.8
-
编辑器: pycharm 2021.2
原理:
模拟 浏览器 向 服务器 发送网络请求(访问网站)
基本思路
实现案例:
分析数据来源
静态页面(数据来源 = 当前浏览器里面的网址)
代码实现:
-
发送请求
-
获取数据
-
解析数据(我需要的内容取出来 餐厅名称 评分 评价人数 地址 电话)
-
保存数据
代码展示
导入模块
# Python里面有非常多的第三方工具
# 内置工具也有很多
import requests # 发送请求 第三方模块
import parsel # 解析数据 第三方模块
伪装 Python 字典容器
🎯 博主所有文章素材、解答、源码、教程领取处:点击

list_html = requests.get(url=url_, headers=headers).text
list_select = parsel.Selector(list_html)
link_list = list_select.css('.bGnIM .OhCyu span a::attr(href)').getall()
for link in link_list:

- 发送请求
response = requests.get(url=url, headers=headers)
- 获取数据
html_data = response.text
- 解析数据
:nth-child(3): 选择第几个标签 采集多页内容
python学习交流Q群:261823976 ###
selector = parsel.Selector(html_data)
store_name = selector.css('.fHibz::text').get()
comment_count = selector.css('.eSAOV.H3:nth-child(2) .eBTWs::text').get()
address = selector.css('.eSAOV.H3:nth-child(3) .dyeJW.dUpPX:nth-child(1) a::text').get()
phone = selector.css('.eSAOV.H3:nth-child(3) .dyeJW.dUpPX:nth-child(2) a::text').get()
score = selector.css('.eEwDq .fdsdx::text').get()
print(store_name, comment_count, address, phone, score)
尾语 💝
要成功,先发疯,下定决心往前冲!
学习是需要长期坚持的,一步一个脚印地走向未来!
未来的你一定会感谢今天学习的你。
—— 心灵鸡汤
本文章到这里就结束啦~感兴趣的小伙伴可以复制代码去试试哦 😝