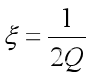Scrapy爬虫学习一
- 1 scrapy框架
- 1.1 scrapy 是什么
- 1.2 安装scrapy
- 2 scrapy的使用
- 2.1创建scrapy项目
- 2.2 创建爬虫文件
- 2.3爬虫文件的介绍
- 2.4 运行爬虫文件
- 3 爬取当当网前十页数据
- 3.1 dang.py:爬虫的主文件
- 3.2 items.py 定义数据结构
- 3.3 pipelines.py 管道
- 3.4 执行命令
1 scrapy框架
1.1 scrapy 是什么
Scrapy是一个为了 爬取网站 数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
1.2 安装scrapy
使用anaconda安装是比较方便的,直接使用命令
pip install scrapy
2 scrapy的使用
2.1创建scrapy项目
在终端输入命令
scrapy startproject dangdang(项目名称)
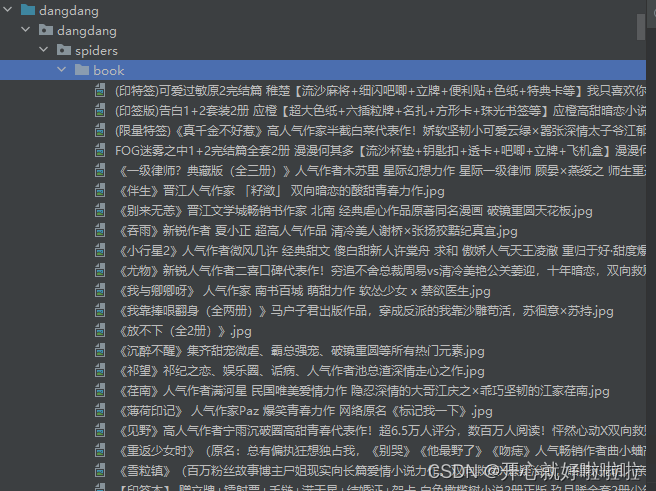
创建之后的文件如下


2.2 创建爬虫文件
首先跳转到项目下的spiders目录下
cd dangdang/dangdang/spiders
创建自定义爬虫文件,使用命令
scrapy genspider 爬虫名字 网页的域名
例如当当网的域名为https://category.dangdang.com/
scrapy genspider dang https://category.dangdang.com/
会在spiders目录下生成dang.py的文件
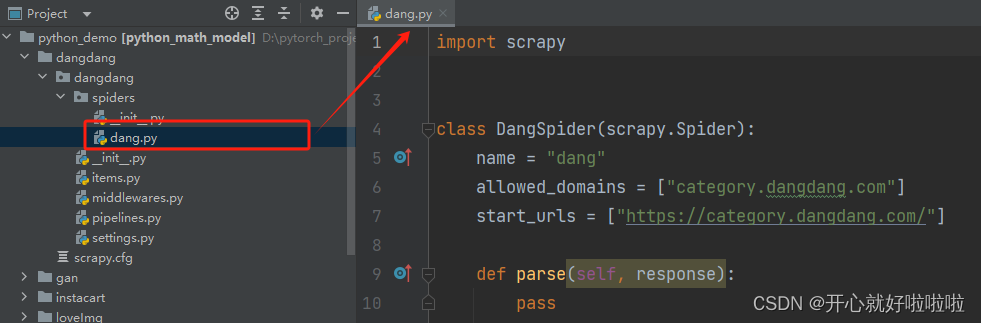
2.3爬虫文件的介绍
继承scrapy.Spider类

class DangSpider(scrapy.Spider):
name = "dang" # 运行爬虫文件使用的名字
allowed_domains = ["category.dangdang.com"] # 爬虫允许的域名,在爬虫的时候,如果不是此域名之下的url,会被过滤掉
start_urls = ["https://category.dangdang.com/"] # 声明了爬虫的起始地址,可以写多个url,一般是一个
def parse(self, response): # 解析数据的回调函数
pass # response.text 响应的是字符串
# response.body 响应的是字符串
2.4 运行爬虫文件
使用如下命令运行爬虫文件
scrapy crawl dang(爬虫名称)
3 爬取当当网前十页数据
直接使用上述的项目
3.1 dang.py:爬虫的主文件
dang.py:为爬虫的主要业务逻辑
import scrapy
from dangdang.items import DangdangItem
class DangSpider(scrapy.Spider):
name = "dang"
# 多页下载 一般情况下只写域名
allowed_domains = ["category.dangdang.com"]
start_urls = ["http://category.dangdang.com/cp01.01.02.00.00.00.html"]
base_url = 'http://category.dangdang.com/pg'
page = 1
def parse(self, response):
# src = //ul[@id="component_59"]/li//img/@src
#alt = //ul[@id="component_59"]/li//img/@alt
# price = //ul[@id="component_59"]/li/p[@class="price"]/span[1]/text()
# 所有的selector对象 都可以再次调用xpath方法
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first() # extract_first()提取数组第一个selector的data
# 第一张图片和其他图片的标签属性是不一样的
# 第一张图片的src是可以使用的 其他的图片地址是data-original
if src :
src = src
else:
src = li.xpath('.//img/@src').extract_first()
name = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
print(src,name,price)
book = DangdangItem(src=src,name=name,price=price)
# 获取一个book 交给pipeline管道
yield book
# http://category.dangdang.com/pg1-cp01.01.02.00.00.00.html
if self.page<10:
self.page = self.page +1
url = self.base_url+str(self.page) + '-cp01.01.02.00.00.00.html'
# scrapy.Request就是scrapy就是get请求
# url就是请求地址 callback就是回调,也就是要执行的函数 再次调用parse函数
yield scrapy.Request(url=url,callback=self.parse)
yield函数:
带有yield的函数不再是一个普通函数,而是一个生成器generator,可用于迭代
yield是一个类似return的关键字,迭代一次遇到yield就返回yield右边的值。
3.2 items.py 定义数据结构
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 图片
src = scrapy.Field()
#名字
name = scrapy.Field()
# 图片
price = scrapy.Field()
3.3 pipelines.py 管道
可定义多个管道。本案例使用双管道爬取,一个下载对应的json,一个爬取下载对应的图片
# 使用管道 在settings 中开启管道
#
class DangdangPipeline:
# item就是yield后面的book对象
def open_spider(self,spider):
print('-----open-----')
self.fp = open('book.json','w',encoding='utf-8')
def process_item(self, item, spider):
#过去频繁 不推荐
# #保存到文件中 w模式每次写都会打开一次文件 会覆盖之前的文件
# with open('book.json','a',encoding='utf-8') as fp:
# fp.write(str(item))
self.fp.write(str(item))
return item
def close_spider(self,spider):
print('-----close-----')
self.fp.close()
# 多条管道开启
# 'scrapy_dangdang.pipelines.DangDangDownloadPipeline': 301,#多条管道
class DangDangDownloadPipeline:
def process_item(self, item, spider):
filename = './book/'+item.get('name')+'.jpg'
urllib.request.urlretrieve(url='http:'+item.get('src'),filename=filename)
return item
使用前在settings.py设置类中,设置过管道爬取
ITEM_PIPELINES = {
# 管道是有优先级0-1000 值越小优先级越高
"dangdang.pipelines.DangdangPipeline": 300,
'dangdang.pipelines.DangDangDownloadPipeline': 301
}
3.4 执行命令
scrapy crawl dang
管道一DangdangPipeline类爬取的书名、价格、图片地址
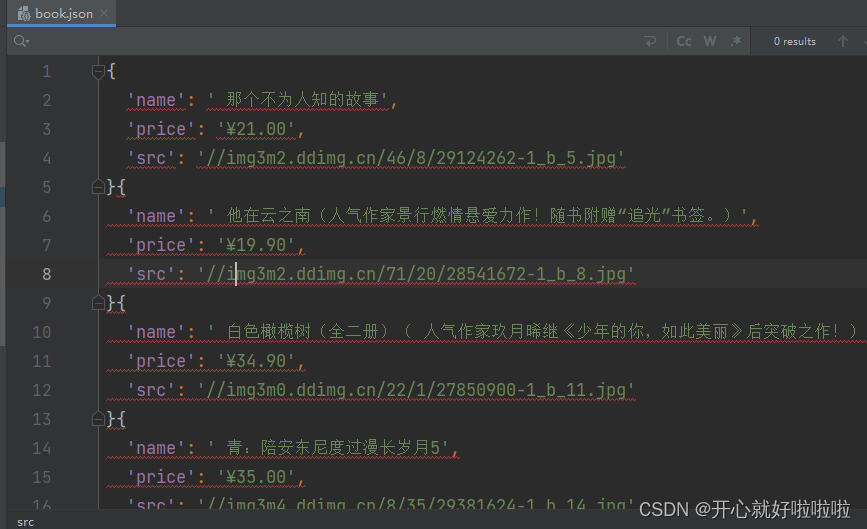
管道二DangDangDownloadPipeline类下载的书的图片