参考
Reinforcement Learning, Second Edition
An Introduction
By Richard S. Sutton and Andrew G. Barto
MDP 是强化学习问题在数学上的理想化形式,因为在这个框架下我们可以进行精确的理论说明
智能体与环境的交互
智能体与环境交互,会得到轨迹,根据轨迹长度
T
T
T的情况,分为分幕式任务(
T
<
∞
T<\infty
T<∞)和持续式任务(
T
=
∞
T=\infty
T=∞)。轨迹的形式为:
S
0
,
A
0
,
R
1
,
S
1
,
A
1
,
R
2
,
S
2
,
A
2
,
.
.
.
\blue{S_0,A_0},\red{R_1,S_1,A_1},\green{R_2,S_2,A_2},...
S0,A0,R1,S1,A1,R2,S2,A2,...
回报( G G G return)与奖励( R R R reward)
G
t
=
R
t
+
1
+
γ
R
t
+
2
+
γ
2
R
t
+
3
+
.
.
.
G_t=R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3} + ...
Gt=Rt+1+γRt+2+γ2Rt+3+...
从
t
+
1
t+1
t+1开始的原因:因为不存在
R
0
R_0
R0,但是存在
G
0
G_0
G0
状态价值函数 v π ( s ) v_{\pi}(s) vπ(s) 与动作价值函数 q π ( s , a ) q_{\pi}(s,a) qπ(s,a)
v
π
(
s
)
≐
E
[
G
t
∣
s
]
=
E
[
R
t
+
1
+
γ
G
t
+
1
∣
s
]
v_{\pi}(s) \doteq \mathbb{E}[G_t|s]=\mathbb{E}[R_{t+1}+\gamma G_{t+1}|s]
vπ(s)≐E[Gt∣s]=E[Rt+1+γGt+1∣s]
q
π
(
s
,
a
)
≐
E
[
G
t
∣
s
,
a
]
=
E
[
R
t
+
1
+
γ
G
t
+
1
∣
s
,
a
]
q_{\pi}(s,a) \doteq \mathbb{E}[G_t|s,a]=\mathbb{E}[R_{t+1}+\gamma G_{t+1}|s,a]
qπ(s,a)≐E[Gt∣s,a]=E[Rt+1+γGt+1∣s,a]
注意到
v
,
q
v, q
v,q都定义成给定
π
\pi
π这个分布的期望回报,因此都是理想存在的一个函数,而不是算法内部的。算法内部对他们两个函数的估计记作大写
V
π
(
S
t
)
V_{\pi}(S_{t})
Vπ(St)与
Q
π
(
S
t
,
A
t
)
Q_{\pi}(S_{t},A_{t})
Qπ(St,At)
策略函数 π ( a ∣ s ) \pi(a|s) π(a∣s)
策略是从状态到每个动作的选择概率之间的映射
π ( a ∣ s ) \pi(a|s) π(a∣s) 中间的"|“只是提醒我们它为每个 s 都定义了一个在 a 上的概率分布
重要函数与公式
- 四参数动态函数
p ( s ′ , r ∣ s , a ) p(s',r|s,a) p(s′,r∣s,a)
表示given s s s采取动作 a a a,走到 s ′ s' s′并获得 r r r的概率(对每一个不同的s,a组合,都有这样的一个函数)
- 状态转移概率
p ( s ′ ∣ s , a ) = ∑ r ∈ R p ( s ′ , r ∣ s , a ) p(s'|s,a)=\sum_{r\in \mathcal{R}} p(s',r|s,a) p(s′∣s,a)=r∈R∑p(s′,r∣s,a)- 状态-动作期望收益
r ( s , a ) = ∑ r ∈ R r ∑ s ′ ∈ S p ( s ′ , r ∣ s , a ) , r(s,a) = \sum_{r\in{\mathcal{R}}}{r}\sum_{s^{\prime}\in{\mathcal{S}}}p(s^{\prime},r\mid s ,a), r(s,a)=r∈R∑rs′∈S∑p(s′,r∣s,a),- 状态-动作-后继状态
r ( s , a , s ′ ) = ∑ r ∈ R r p ( s ′ , r ∣ s , a ) p ( s ′ ∣ s , a ) r(s,a,s') = \sum_{r\in{\mathcal{R}}}r\,\frac{p(s^{\prime},r\mid s,a)}{p(s^{\prime}\mid s,a)} r(s,a,s′)=r∈R∑rp(s′∣s,a)p(s′,r∣s,a)
- 用
π
,
q
\pi,q
π,q表示
v
v
v
v π ( s ) ≐ ∑ a π ( a ∣ s ) q π ( s , a ) v_\pi(s)\doteq\sum_{a}{\pi(a|s)q_{\pi}(s,a)} vπ(s)≐a∑π(a∣s)qπ(s,a) - 用
v
v
v和四参数动态函数表示
q
q
q
q π ( s , a ) = ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] q_\pi(s,a)=\sum_{s',r}p(s',r|s,a)[r+\gamma v_\pi(s')] qπ(s,a)=s′,r∑p(s′,r∣s,a)[r+γvπ(s′)]
贝尔曼方程
- 状态价值函数的贝尔曼方程

- 动作价值函数的贝尔曼方程
看第二个等号,求和号里面第二项实际上就是
q
π
q_\pi
qπ,因此
q
π
(
s
,
a
)
=
∑
s
′
,
r
p
(
s
′
,
r
∣
s
,
a
)
[
r
+
γ
v
π
(
s
′
)
]
q_{\pi}(s,a)=\sum_{s^{\prime},r}p(s^{\prime},r|s,a)[r+\gamma \red{v_{\pi }(s')}]
qπ(s,a)=s′,r∑p(s′,r∣s,a)[r+γvπ(s′)]
=
∑
s
′
,
r
p
(
s
′
,
r
∣
s
,
a
)
[
r
+
γ
∑
a
′
π
(
a
′
∣
s
′
)
q
π
(
s
′
,
a
′
)
]
=\sum_{s^{\prime},r}p(s^{\prime},r|s,a)[r+\gamma \red{\sum_{a^{\prime}}\pi(a^{\prime}|s^{\prime})q_{\pi}(s^{\prime},a^{\prime})}]
=s′,r∑p(s′,r∣s,a)[r+γa′∑π(a′∣s′)qπ(s′,a′)]
贝尔曼最优方程
v
∗
(
s
)
=
max
a
q
∗
(
s
,
a
)
v_*(s)=\max_a q_{*}(s,a)
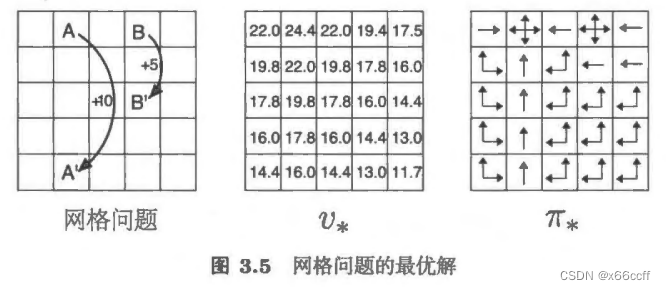
v∗(s)=amaxq∗(s,a)